We had a brief outage early Tuesday morning from 3 AM - 5 AM PST, because the database server was doing this:
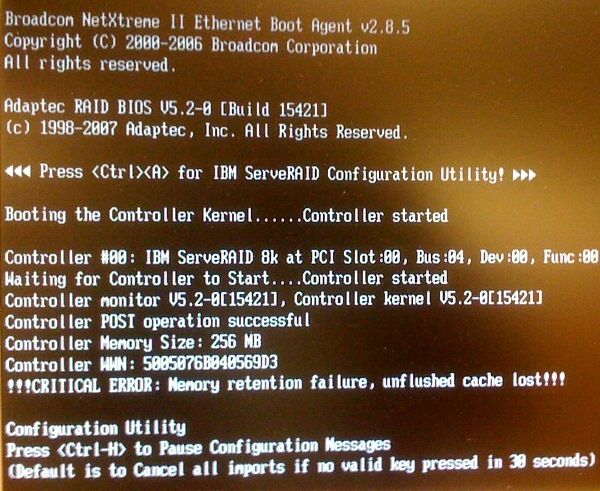
Oh noes! Not ...
!!! CRITICAL ERROR: Memory retention failure, unflushed cache lost !!!
There are six exclamation points so you know it's serious. Also, you have to press ENTER. Because it's a CRITICAL ERROR !!!
(we didn't know this at the time, we only belatedly found out later -- once Geoff got up in the morning and had time to head down to the data center.)
One of the pieces of advice I got on server hosting was to have extra servers on hand just in case. We currently have three web tier servers, though we're only using one (and soon two), so one of those was quickly pressed into service as our temporary database server.
We have a reasonable backup scheme in place using our little NAS; full database backups occur at 2AM, and incremental backups every four hours. This problem happened at 3AM so we did lose about an hour of data. Our apologies for that.
Our contingency planning isn't what it should be. We went back and forth with the datacenter for a bit trying to figure out what had happened, and that wasn't smooth due to our lack of planning and the late hour (~1 hour). After I realized a quick power cycle wasn't going to fix the issue, I had to reconfigure one of the web servers. This meant downloading the SQL Server 2008 ISO (25 minutes), installing a hotfix and reboot (5 minutes), then completing the installation (20 minutes). I could then, finally, restore the latest backup from 2 AM (10 minutes). So we were down longer than I would've liked.
What's unnerving about this problem, though, is that the RAID controller on the Lenovo RD120 -- an Adaptec card that has been rebranded the "IBM ServeRaid 8k" -- has had three BIOS updates since I built the machine in late January, with the (then) latest BIOS! The good news is that the latest BIOS for the ServeRaid-8k fixes this specific 'press ENTER' problem, in fact. So Geoff burned it to bootable CD and installed it.
(On a related note, I discovered that the lower-end LSI 1064e RAID card on our web servers has also had a driver update which fixes the "bluescreen on drive eject" problem I observed while building them -- and assumed was the norm. I guess not.)
We know why the server didn't come back after the reboot. But we still don't know what triggered this server reboot in the first place. The event logs and SQL logs look clean, with no hints on rebooting. Now, the Adaptec / ServeRaid 8k card has always been a little wonky for us, causing oddball hard drive incompatibilities with its factory shipped BIOS, and leaving us unable to turn write-back caching on without suffering from bizarre I/O pauses under heavy writes even with the (then) absolute latest firmware, bios, and drivers. So I am tempted to blame it, in the absence of any other evidence.
If I've learned anything from this experience, it is:
- Never skimp on your RAID controller. Invest in something quality.
- Pick a RAID controller with good community buzz, and a proven track record of support and reliable performance.
I thought when I bought Lenovo / IBM, I'd be getting decent RAID controllers with the servers. This is at least partially true. Those rebranded entry-level LSI 1064e RAID controllers on the Lenovo RS110 servers have been solid and reliable performers. The fancier Adaptec/ServeRaid 8k RAID controller on the Lenovo RD120 has been ... uh, less so. But at the rate they're releasing new BIOS updates for the ServeRaid 8k, maybe they'll get there eventually? Or at least let us turn write-back caching on without crippling I/O pauses under load? At this point I'll settle for please don't corrupt all our data..