It has been a year and a half since we launched Data Explorer. In the past few months Tim Stone (on a community grant) and I have pushed a major round of changes. Thanks Tim!
Recap on last years changes
Since we publicly launched data explorer, the most notable change contributed back from the community was support for query plans, big thanks to Justin for submitting the patch. We also added quite a few bug fixes/features, mostly around merging users. Some features were added to defend data.se against an onslaught of public queries. A few features were added to support non Stack Exchange data dumps, most notably a system for white listing. Our very own Rebecca Chernoff ported Data Explorer to ASP.NET MVC3 amongst many other fixes. The current round of changes offers some very cool new functionality, which is worth listing:
Query revisions
When we created Data Explorer there was no way to track a query's "lineage". This was particularly problematic because we had no way of updating featured queries or shared queries. Even I complained about this on meta. The new pipeline works just like Gist, you can track the history of your query as you are editing (attributing the various editors along the way):

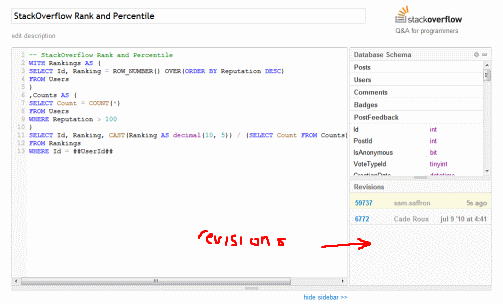
You can link to a specific revision, or simply share a "query set" by using the permalink. By sharing a "query set" you can later on fix up any issues the query has, without needing to update the link. The new pipeline allows you to "fork" any query created by other users and tracks attribution along the way.
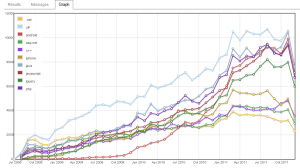
Graphs
We added some basic graphing facilities, supporting 2 types of line graphs: The first type is a simple graph, where the first column represents the X-axis and the other columns the data points. For example: a graph of questions and answers per month. The second type is a bit trickier, it unpivots the second column in the result set. For example: a graph of questions per tag for top 10 tags.
Huge open source upgrade
Data Explorer consumes a fair amount of open source libraries. In the past year and a half many have evolved. We took the time to upgrade them all. The excellent Code Mirror was updated to the 2.0 version, the new version no longer uses messy iframes. Marjin wrote a great post explaining the changes, a fantastic read for any JavaScript developers. SlickGrid, which in my opinion is the best grid control built on jQuery, was upgraded to version infinity.
100% more Dapper
Dapper our open source micro ORM is the only ORM Data Explorer uses. We took the time to port the entire solution to Dapper. I even added a few CRUD helpers so you are not stuck hard coding INSERT and UPDATE statements everywhere. Data Explorer is a good open source example of how we code web sites at Stack Overflow. It is built on our stack using many of our helpers. Dapper and related helpers are used for data access. It uses the same homebrew migration system we use in production and an interesting asset packaging system I wrote (for the record, Ben wrote a much more awesome one that we use in production, lobby him to get it blogged). It also uses MiniProfiler for profiling. MiniProfiler is even enabled in production, so go have a play.
Lots of smaller less notable fixes
- We now have a concept of "user preferences", so we can remember which tab you selected, etc.
- We remember the page you were at and try to redirect you there after you log on.
- We attribute the query properly to the creator / editor from the query show page.
- You can page through your queries on your user page.
- Support for arbitrary hyperlinks
- Revamped object browser, you can collapse table definitions
- Lots of other stuff I forgot :)
You too can run Data Explorer
At Stack Exchange we run 3 different instances of Data Explorer. We have the public Data Explorer and a couple of private instances we use to explore other data sets. The first private instance is used for raw site database access. The other is used to browse through our haproxy logs. There is nothing forcing you to point Data Explorer at a Stack Exchange data dump, the vast majority of the features work fine pointed at an arbitrary database. Hope you enjoy this round of changes. If there are any bugs or feature requests please post them to Meta Stack Overflow. Data Explorer is open source, patches welcome. Do you enjoy exploring and mining data? Discover new job opportunities using big data on Stack Overflow Jobs.