
👋 Hello! We’re Jason Punyon and Kevin Montrose, long time Stack Overflow developers and the founding members of the Data Science Team.
We all want Stack Overflow to be a welcoming and friendly place. Sometimes comments on Stack Overflow are very obviously unwelcoming, and we’re good at removing those. Things like hate speech and bigotry are infrequent, and they don’t last long before they’re flagged by our community and handled by our moderators. Some unfriendliness is more subtle though, and these comments don’t always get flagged away. We’ve written about some of our work attempting to address these subtly unfriendly comments and recently our community has asked us about it. In this post, we’re going to update you on the work we’ve done in this area over the last two years.
As developers, we’re inclined to think in terms of systems. Stack Overflow is a big system, made of many subsystems, intended to help people get answers to their programming questions. These subsystems are things like voting, reputation, the ask flow, comments, Meta, closing, badges, flagging, review queues, nurturing new contributors, and so on. No part of the system is here just for funsies. All of these subsystems come together to help the overall system fulfill its purpose. When these subsystems have issues, they need—and deserve—fixes.
Unfriendly comments are an issue in our system because of the effect that their tone has on their recipient’s and future readers’ willingness to contribute to Stack Overflow. We know (from personal experience, surveys, and interviews) that making the leap to being a contributor is intimidating and scary and it stands to reason that every little “you won’t be welcome here” signal makes it even scarier. There are more comments than almost anything else in the system, and accordingly, there’s a lot of space for these signals.
The problem with unwelcoming comments is rarely the commenter or the intent of their comments (remember that bigotry and harassment, while definitely unwelcoming, are a completely different category). The problem is the tone the reader experiences. Most of the time, it doesn’t appear that commenters are actively trying to make their comment condescending, dismissive, or any of the other subtle variations of unwelcoming we see. These are people earnestly trying to help others, even if their tone is off.
The recipient of an unfriendly comment bears the brunt of its impact. These people have already made the scary leap of trying to contribute, but these sorts of comments can easily convince them that was a mistake. More insidious and arguably more important is the impact on future readers of these comments. These readers are often neglected in discussions, probably because they are relatively invisible, but there are lots of them. A comment will be read by it’s “intended” recipient once or twice, but dozens or hundreds of readers will read it over time. In aggregate, passersby could be more impacted by an unfriendly comment than a question asker despite having no control over the post or its quality. While it is hard to measure how many could-have-been-good-contributors have been turned away by this experienced unfriendliness, we do know it is a common piece of feedback. It was the most common coded response to “What do you find most frustrating or unappealing about using Stack Overflow?” in a recent survey at ~10% of respondents.
The solution to these issues isn’t to argue about circumstance or intent. Arguments that end up at “What does it matter how you feel, I wasn’t intending to be dismissive” or “You can’t be trying to help, not with that tone” don’t get us anywhere. You cannot invalidate someone’s lived experiences. We don’t believe that there are villains to expel here, so suspending or banning users isn’t the answer. The only remaining option is to work on the comments themselves.
Go and see
We started by going to see the problem for ourselves. Stack Overflow employees classified comments from random Stack Overflow posts into three categories: Fine, Unfriendly, and Abusive. Experience was varied but our median employee classified 6.5% comments of the comments they saw as unfriendly. We invited three more groups of people to classify comments: moderators, a set of registered users from our general research list, and a set of people who responded to our original blog post saying they were interested in making Stack Overflow more welcoming. Experience was again varied. The median person from these groups classified 3.5% of the comments they saw as unfriendly.
Flagging history
Stack Overflow introduced comment flagging on April 16, 2009. Once a user earns 15 reputation, they can flag comments to bring them to the attention of our moderators. Once a comment is flagged, moderators either accept the flag and the comment is removed from the site, or decline the flag and the comment is allowed to stay. Until mid-2018, we had one relevant type of comment flag for dealing with anything like unfriendliness: The offensive flag. For about the first year when we aged offensive flags away, the data was deleted. We began to have reliable data on usage of the offensive flag in March 2010. Let’s calculate the comment offensive flagged percentage for each day (# of comments flagged from a day / # of comments posted that day) and put them on a monthly box plot.
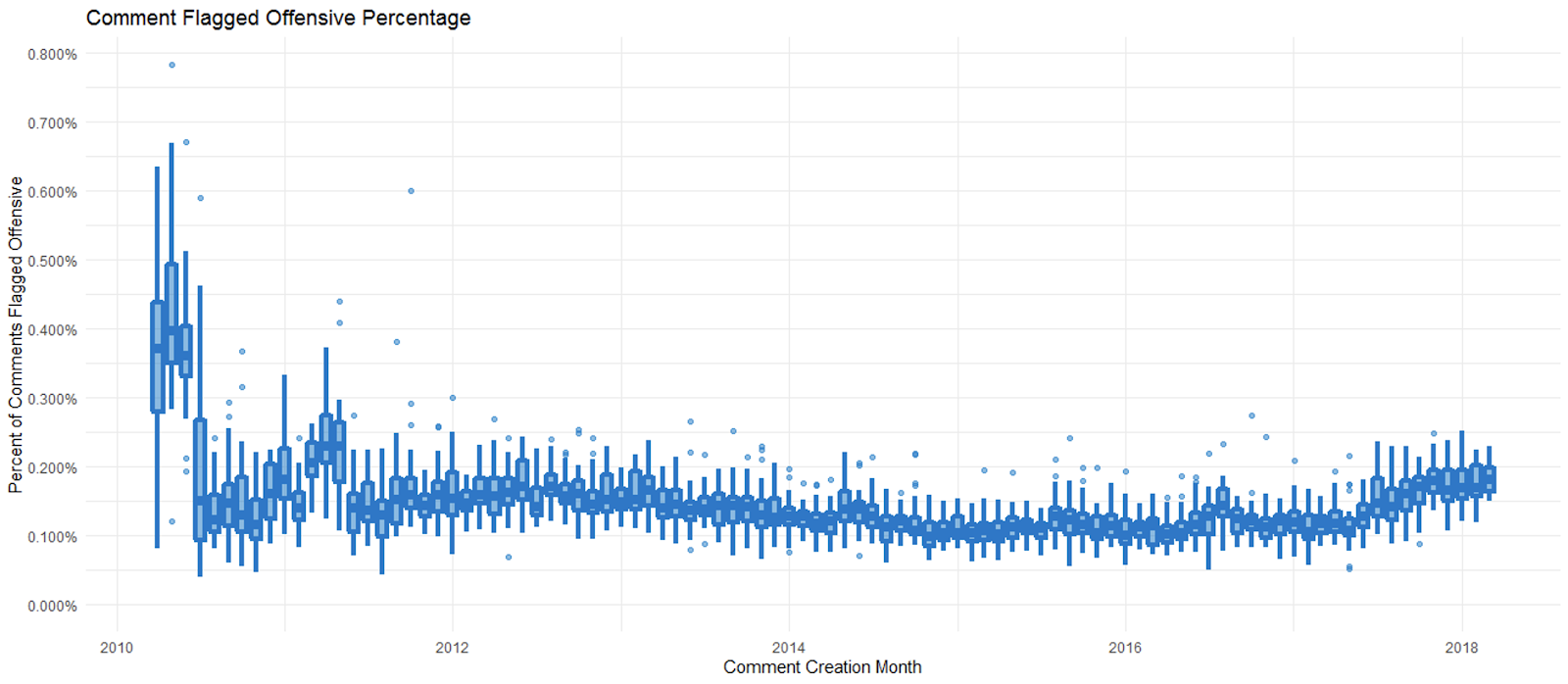
There are two periods of elevated comment flag percentage near the beginning of the data where Stack Overflow developers used the comment flagging system for some bulk cleanup. The monthly distribution stabilizes in the middle of 2011 and very slowly rolls off until mid-2017, when it starts notching up. The bulk of the monthly distributions are between 0.1% and 0.2%. During this period 83.6 million comments were posted, and 114,577 of them were flagged, which gives an overall comment offensive flagged percentage of 0.137%. If we count only the flags that moderators accepted, we have an estimate that 0.105% of comments on Stack Overflow are unfriendly.
Very different estimates
The two estimates we had for unfriendliness in the comments were wildly different. The flagging system estimates the unfriendly percentage of Stack Overflow comments at 0.105%. The median non-employee found 3.5% of Stack Overflow comments unfriendly. Those are very different estimates, but to be fair, they were measured in very different contexts. One context is Stack Overflow, the full website with questions, answers, reputation, everything. The other context is stripped down to just the text entries from a random comment thread. The states of mind of the users in each context are different: people on Stack Overflow are busy trying to solve their own problems or help someone else; comment classifiers have been primed by instructions to look for unfriendliness. The people themselves are self-selected in slightly different ways. Flaggers on Stack Overflow played at least enough of the game to get 15 reputation; comment classifiers were moderators or answered one of our research calls to action. We should expect some difference in the results due to the differences in the way we’re measuring, but a factor of 33 was too much to wave away. We moved forward on the hypothesis that Stack Overflow’s comment flagging system had a false negative or an underflagging problem.
Build or buy?
We explored ways to test that hypothesis. A few companies looked like they had tools we could buy, and we explored what they had to offer. For one reason or another, none of them worked out. Companies got bought. There were legal issues about data sharing or NDAs. We’d get deep in and find out they were focused on the adjacent problem of identifying problematic users from their comment histories instead of just classifying the text itself.
While that was all not working out we also explored build options. 2018 was an exciting year in natural language processing. In May 2018, Jeremy Howard and Sebastian Ruder published ”Universal Language Model Fine-tuning for Text Classification”. ULMFiT made it possible to train very good text classifiers with very little labeled data. fast.ai released code to train ULMFiT models in the fastai library. They also offered a free online course to teach you neural networks and use the library. We took a first swing at getting it to run in July 2018, but we were unable to get access to an appropriately sized GPU (all our home cards were too small, and we couldn’t get any of the cloud providers to give us one). October rolled around and the fastai library went v1. Coincidentally, our last buy option had just dried up, and it felt like it was time to give fastai another go.
ULMFiT
In November 2018, we got access to a usable GPU in Azure and had nearly immediate success. ULMFiT uses two datasets of Stack Overflow comments to produce a classifier. An unlabeled set of Stack Overflow comments is used to adapt ULMFiT’s pre-trained Wikipedia language model to the language of Stack Overflow comments. A set of Stack Overflow comments with labels is then used to train a binary Unfriendly/NotUnfriendly classifier. For the unlabeled set, we used a few hundred thousand randomly selected Stack Overflow comments. For the labeled set, we took every comment that had been flagged offensive and labeled them Unfriendly and we chose an equal number of random Stack Overflow comments and labeled them NotUnfriendly. With 20 more lines of python (really go take the course and see for yourself) and a few hours of training, we had a model with a validation set AUC of .93. We used the threshold associated with the highest F1 score and measured an accuracy of 85% on our evenly split validation set.
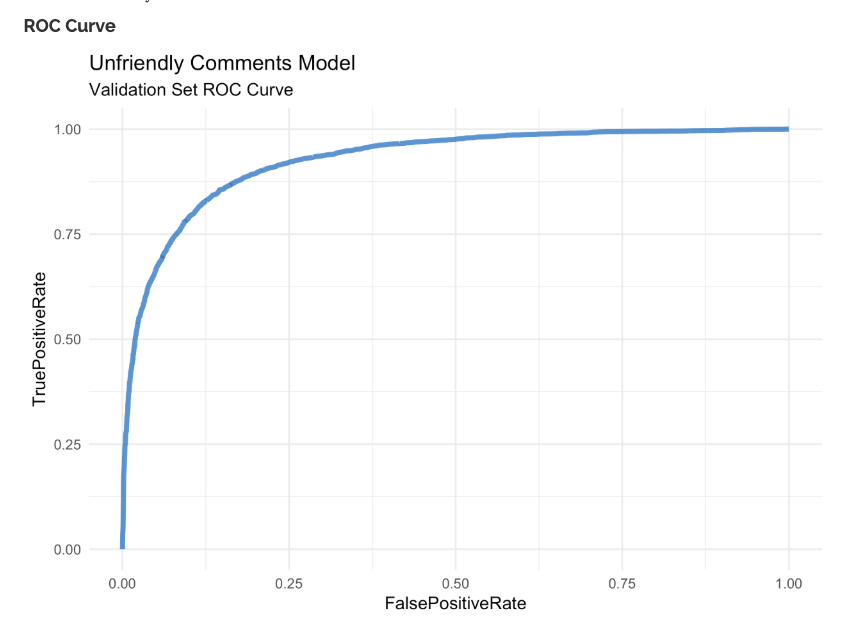
Exploring the validation predictions gave us the impression that the accuracy number was soft because our labels were dirty. On the Unfriendly end of the predictions, we found comments from the validation set that were truly unfriendly but had never been flagged. These “false” positives weren’t really false at all, they were simply missed by the existing flagging system. At the NotUnfriendly end of the predictions, we found comments from the validation set that had been flagged offensive but really weren’t. Really innocuous stuff like people saying “Thank you” (the audacity!). These “false” negatives weren’t really false either. ULMFiT found and corrected some of these dirty labels which indicated to us that if the underflagging hypothesis was indeed true then ULMFiT could find some of the missing flags.
Humans in the loop
We set out to build the rest of the system that would allow ULMFiT to watch all new incoming comments and propose flags to our moderators for them to handle. We really want to stress the propose bit there. We weren’t and aren’t interested in building anything into our system where the machine makes final decisions in the absence of humans. Our hope wasn’t (and isn’t) to train and train and train and one future, glorious day, pass the mantle of flag handling from our moderators to a GPU. We wanted to build a tool to augment the capabilities of the humans in our system, not replace the humans.
The building of that system would take a few more months. We had to socialize what we’d found within the company. We had to wrap the model up in a web API. We worked with SRE to get our cloud environment up to snuff. We had to make Stack Overflow call out to the model when new comments came in and put the flags into the dashboard for moderators. Our community team watched the flag for a few weeks, and using their results, we tuned the flagging threshold. We watched them work and had them think out loud while they were handling the flags. There’s a lot of stuff that has to go down after you get a good validation score. Training the model ended up being the easiest part, by far. When all that was done, we put Unfriendly Robot V1 to work.
Robot Results (so far)
Unfriendly Robot V1 (UR-V1) was in service from July 11, 2019, to September 13, 2019. There were 1,715,693 comments posted to Stack Overflow during this period. UR-V1 flagged 15,564 comments (0.9%), and 6,833 of those flags were accepted by our moderators. 43.9% of UR-V1’s flags were accepted. During the same period humans flagged 4,870 (0.2%) comments as unfriendly and 2,942 of those flags were accepted by our moderators. 60.4% of human flaggers’ flags were accepted.
Is that good? To assess that it helps to combine the human and robot performance metrics into two new metrics: The Robot Rating and the Detection Factor.

Robot Ratings above 1 indicate that robot flags are accepted more often than human flags. Detection Factors above 2 mean that the robot finds more objectionable comments on Stack Overflow than human flaggers. UR-V1’s robot rating was 0.72, so its flags weren’t accepted as often as human flags. There were a lot of false positives. UR-V1’s detection factor was 3.3. UR-V1 helped moderators remove 3.3× as many comments as human flaggers alone.
At the end of August, we retrained the robot. We wanted to get a better false positive rate (higher Robot Rating) without compromising accepted flag throughput (the Detection Factor). There was much training, and eventually, UR-V2 passed the smell test. UR-V2 went into service on September 13, 2019. There have been 4,251,723 comments posted to Stack Overflow since then. UR-V2 has flagged 35,341 comments, and 25,695 of those flags were accepted by our moderators. Humans have flagged 11,810 comments as unfriendly and moderators accepted 7,523 of those flags. UR-V2’s robot rating is 1.14 and its detection factor is 4.4. UR-V2’s flags were accepted 14% more often than human flags during this period, and it helped moderators remove 4.4× as many comments as human flaggers alone.
We want to make clear here that even though the current version of the robot appears to be performing amazingly well, our human flaggers are just as important as ever. The only reason the robot is able to do as well as it’s doing is because of the 100,000+ flags that humans have raised and moderators have handled. The robot is a way to find things that look like things humans have flagged before, but we don’t think it can identify truly novel modes of unfriendliness. Only the humans in our system can do that. So if you see unfriendliness in the comments, please flag it. You’re helping to make Stack Overflow better.
Updating our estimates
Our original humans-only flagging system found and moderators removed 0.105% of comments as unfriendly. The median non-employee found 3.5% of comments are unfriendly. Those estimates were a factor of 33 apart. Our new Humans+UR-V2 flagging system finds and moderators confirm that 0.78% of comments on Stack Overflow are unfriendly. Humans+UR-V2 is finding 7.4× as much unfriendliness in the comments as humans have historically. Instead of being a factor of 33 away from the median non-employee estimate of unfriendliness, now we’re just a factor of 4.4 away.
We do want to temper that finding a little. It can be really tempting to say “We’ve found what the unfriendliness rate really is on Stack Overflow, just look at the Robot Ratings and Detection Factors! It’s so much higher than we thought!” The truth, as always, is a bit blurrier. By the evidence presented here, we don’t necessarily have an iron-clad unfriendliness detector, we have a model that our moderators will accept flags from that happens to have been trained on human unfriendly flags. We know that not all of the comments the robot flags are unfriendly and moderators do accept some of those flags because the comment is worthy of removal for other reasons. We also believe the robot doesn’t catch everything (there’s still false negatives out there to be found).
What’s next?
Our goal is to continue to increase our common understanding of unfriendliness in the comments on Stack Overflow. The work we covered here focused on getting better estimates of the current scale of the problem and resolving questions around the large disparities between our previous estimates, but that is in no way the end. We want to see what we can do about the 100 million comments that went into the system before we had the robot, too. We’re also thinking about ways of using the robot to provide just-in-time guidance for comment authors.
We’ve used these models to help us assess changes we’re making to Stack Overflow. Combining A/B testing with the unfriendly robot allows us to get an estimate of what happens to unfriendliness in the comments when we make changes. Dr. Julia Silge showed in her research update on the Ask Question Wizard that using the wizard was associated with 5% fewer comments overall but 20% fewer unfriendly comments. Helping question askers ask better questions had a huge effect on unfriendliness and we want to see if there are further systemic improvements to be had.
Thanks
This work is the culmination of a lot of effort from a lot of people, not just the authors of this post. We would like to specially thank (in no particular order):
- Everyone who participated in our comment rating exercises
- Everyone who’s flagged a comment on Stack Overflow
- Our moderators who work everyday to improve Stack Overflow
- SOBotics team members for all of their hard work
- The FastAI folks for creating some great software and teaching us how to use it
- Our Community Team, especially Catija and Tim Post
- Dr. Julia Silge
- Shog9
- Meg Risdal
Please direct any comments that you have to this Meta post.