
Customers have told us that they want to avoid context switching. If they are searching for an answer on Stack Overflow for Teams, they want to be able to see answers from across the public Stack Overflow as well. Until today, that ability was available on our Free, Basic, and Business tiers, but not for Enterprise customers. Today we released Unified Search, which allows Enterprise plan customers of Stack Overflow for Teams to search for answers from both their private instance and public content from stackoverflow.com. Now all customers, regardless of their plan, have access to this robust searching capability.
This means you can find answers to your engineering questions even if your engineers haven’t answered them in your private collaboration and knowledge-sharing platform. This post will take a peek under the hood of this new feature and explain how we built this and which architectural trade-offs we dealt with along the way.
Most of our visitors find questions on Stack Overflow via their search engine of choice and not by using Stack Overflow's internal site search. While it's hard to beat professional search engines at their game, our site search still offers a few advantages: First, it allows you to narrow down your search queries via advanced search operators. Second, our internal site search is the only way to search for private content as you'd have on Stack Overflow for Teams. Teams content is yours and most often contains confidential information that we never want to expose to public search engines.
Searching for answers
Our site search is powered by Elasticsearch. Our Elasticsearch cluster contains one index per site on the Stack Exchange network: stackoverflow.com has an index, superuser.com has an index, bicycles.stackexchange.com has an index, you get the idea. This Elasticsearch cluster is running on our own infrastructure in our own data center next to our web servers, SQL databases and Redis instances. Each Teams instance has it's own private Elasticsearch cluster that's completely separate from our public search cluster. If you're an Enterprise-tier Teams customer, for example, you'll have your own Elasticsearch cluster for your private content. That cluster would be running on the same infrastructure where we (or you, if you self-host your Enterprise instance) host your Stack Overflow for Teams instance.
For Teams, we offer different hosting models. Some of our Teams are hosted on stackoverflow.com (you'll get a fancy URL for your team like stackoverflow.com/c/myteam). Those teams are running on the same server infrastructure and in the same data centers that we use to run stackoverflow.com and the entire Stack Exchange network. If your Team is hosted on stackoverflow.com, you've always had the option to run a mixed search when using our site search: You could run the same query against your Team's content as well as the content on stackoverflow.com and the results would show up neatly grouped by origin:
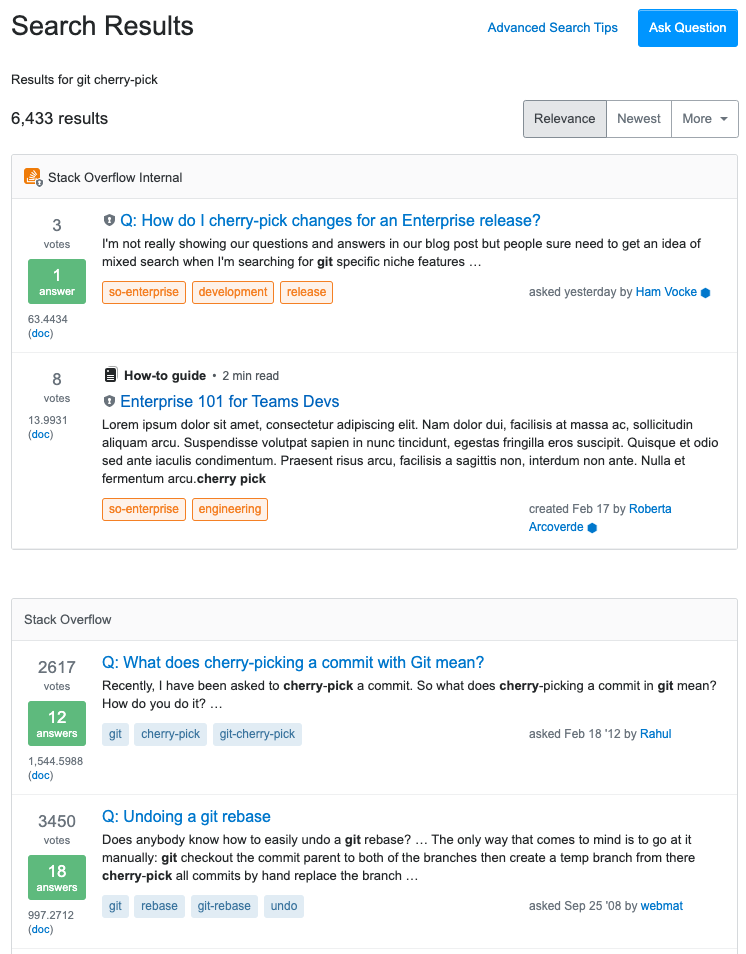
For larger Teams, we also offer hosting your stuff outside of our own data centers: on Azure or—if you're an Enterprise customer and prefer this—even on your own infrastructure. In both of these cases searching content from stackoverflow.com becomes a little more tricky. We can't just run a search query against Stack Overflow's Elasticsearch database as we do on Teams that are hosted on our own infrastructure. Elasticsearch is simply not accessible from your hosting environment.
Larger Teams customers kept asking us for a way to search their own private content and content from Stack Overflow in one swoop. Sometimes you're looking for information that might have been answered within your Team just as much as it might've been answered on stackoverflow.com. Being able to query both data sources from a single place would be comfortable. However, we didn't have a trivial way of allowing this. We can't just open up our data center for incoming connections from the cloud or our clients' own infrastructure to allow them to access Stack Overflow's Elasticsearch. So we needed to come up with a different way.
The discarded option: Searching via our public API
Stack Exchange sites offer a public API that you can use to fetch information from a site on the Stack Exchange network. The /search/advanced endpoint looks like a reasonable candidate for unified search. Whenever a user runs a site search on their Team we could send an extra HTTP request to our public API, pass the search query and show the results side by side with your local Team results.
There are several benefits to using the public-facing API.
First: We'd be eating our own dog food. Using your own public-facing APIs within your product is a great way to make sure that your API is in fact useful, reliable, and actively maintained. Another benefit is low coupling. The only communication between our Teams instance and stackoverflow.com would go through a well-defined public API. We would end up with two systems—Teams and public Stack Overflow—that could each live and be useful on their own without relying on intimate knowledge of each other. Each system could change independently and we wouldn't have to worry about breaking the other as long as we handle changes to the public API in a thoughtful and non-breaking way.
Unfortunately, we had to take a different approach.
Mostly for two reasons:
- Confidentiality vs. abuse prevention: The content in Teams is confidential. And if you try to search for it, you're likely using search queries that are confidential, too. Our users store private knowledge about their organization, their products, or whatever else is important to them. We don't want to see that information—ever. Our public API, however, needs to have a couple of mechanisms in place to prevent abuse. We see a lot of jokers out there trying to slam our API or hit it with nonsense requests. Diligent logging is a necessity to deal with these scenarios. If we sent Teams users' requests to our public API, we'd risk having their confidential search queries end up in our logs. Sure, we could come up with ways to exclude those queries from ever being logged. But what if we accidentally missed an edge case and ended up with confidential queries in our API logs? This was a risk that was unacceptable to us and opposed to the confidentiality we promise to our customers.
- Lack of information & simplicity: The data returned by our
/searchendpoint is limited (Here's all the data we include). While this is great for most applications, for our site search we rely on more information than we expose via our search API. Of course, we could go and expose all those required data points on our public API, but this would be bad for the API's simplicity and usability—some data points are highly technical and related to our underlying Elasticsearch. Exposing these data points only for our own search queries would be possible but completely undermine the idea of having a public API.
Software architecture is about trade-offs. You'll often face multiple options with different flaws and have to pragmatically decide for the one that sucks the least. Using the public API would've come with some convincing benefits and part of me is still sad that we didn't get to use this approach. But ultimately we decided to do something else:
The winning option: Setting up a new Elasticsearch cluster
After coming to terms with the fact that the public API was not the right way to go, we found a different approach: We'd spin up a new Elasticsearch cluster that holds Stack Overflow's questions and answers. This cluster would be queried by all cloud- and on-premise-hosted Enterprise and Teams instances for the purpose of unified search. For private content, they would query their local private Elasticsearch instances respectively.

Thanks to flexible cloud hosting, setting up a new Elasticsearch cluster is not nearly as daunting as it would be if we were to host one in our own data center. Since we've used Elasticsearch before, we got a lot of pieces in place that we need to shove our questions and answers into an Elasticsearch instance, so with a few modifications, we could reuse a lot of the data transfer code we already had.
We saw a few key benefits to spinning up a separate Elasticsearch cluster for unified search. Most importantly this approach solves the risk of accidentally leaking confidential search queries into our server logs. The unified search cluster is set up in a way that we don't store query information, only operational metrics like the number of requests, query duration, index size, and anything else we might need. Secondly, directly querying Elasticsearch without going through a higher-level API allows us to use the same logic for querying your private Elasticsearch content as well as public stackoverflow.com content stored in the unified search cluster. It's all just a bunch of queries to Elasticsearch's REST API. Another benefit is a little more fundamental: With a new search cluster in the cloud, we avoid having a dependency from our cloud infrastructure into our own data center. This way we can continue to keep the most of our data center infrastructure within our perimeter without exposing it to the public internet.
There were two more than welcome side effects to this approach. The first one was rather pragmatic: Currently, we're in the process of moving a bunch of our infrastructure into the cloud. A new Elasticsearch cluster was a self-contained and low-risk piece that we could use to gain experience with what it takes to define, provision, and maintain cloud infrastructure. The second one was more product-focused: A new search cluster allows us to do some experimentation when it comes to how we store our data without affecting our existing site search for our Stack Exchange sites. We used this to sneak in a new way of presenting search results that we've started experimenting with a long time ago but never fully completed: Showing search results as nested questions and answers.
Experimenting with nested search results
Public search results in unified search look different than regular search results—they look a little better if you ask me but hey, I'm obviously biased.
Imagine you're using our site search to figure out how to maneuver yourself out of this mess you made in your local git branch. You enter git undo commit into our search bar and see a bunch of search results coming up:
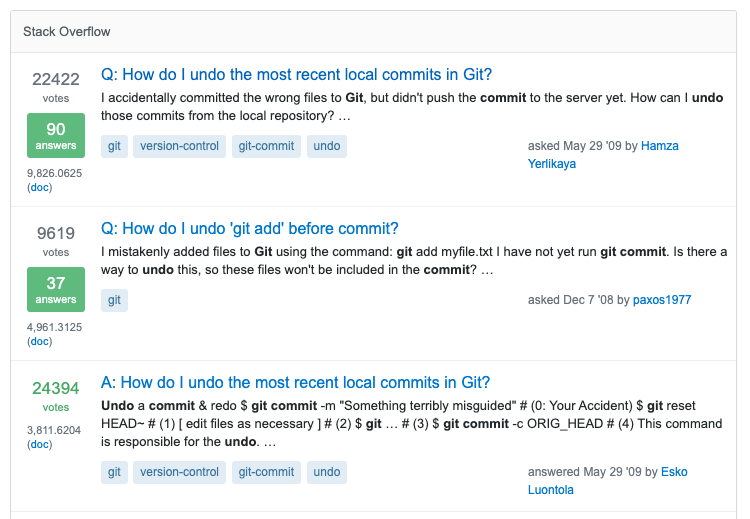
That's what our site search looks like today. You're likely to get reasonable results. But one thing stands out: We're showing questions and answers as separate results. See the first and the third result? Both belong to the same question. The first one (prefixed with Q:) points to the actual question while the third result (prefixed with A:) points to one of its answers. There are moments where this works well and there are other moments where this is pretty confusing.
A good while ago we came up with an idea to group search results that belong to the same question. All answer results would be displayed in the context of their respective question in a nested way. We've run a few internal experiments but never really got this new approach shipped because it was quite a drastic change not only to the visual representation of our search results but also to the way we store and query our data in Elasticsearch. Now that we’re moving a bunch of stuff around with unified search anyways, we decided that this might be a good occasion to get this experiment out of the door and to display the new public search results in unified search in a nested way. Our designers came up with a really neat way of presenting this information so that the relationship between questions and answers becomes much more obvious.
Here's what the new nested search results look like:
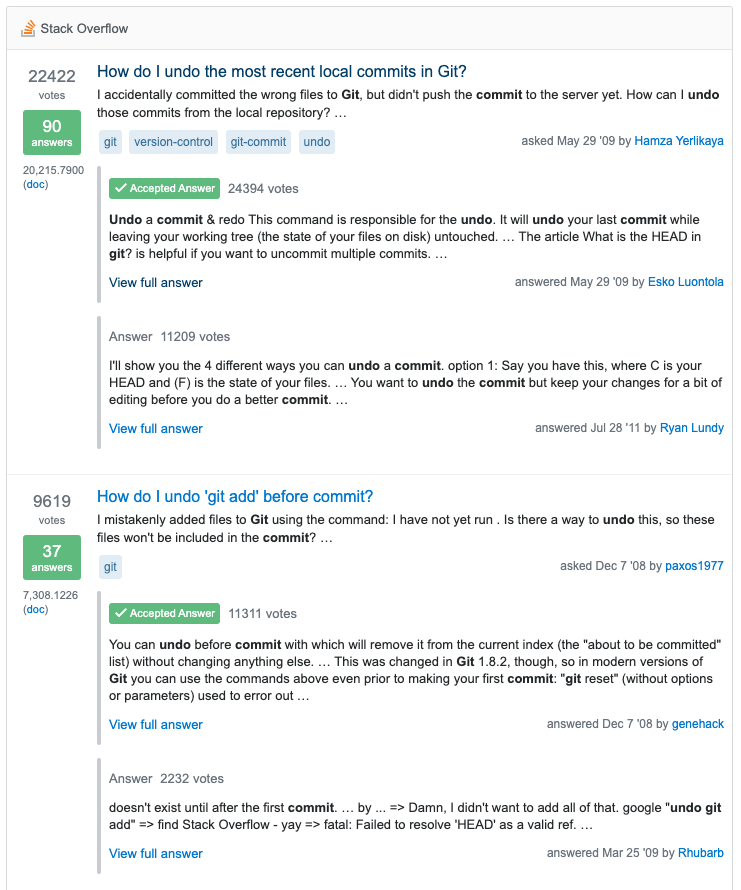
This is not only a new way of displaying search results. We changed the schema of our data stored in Elasticsearch to properly represent the relationship between questions and answers via nested document structures. We used to have a flat document structure with a separate document for each question and answer before. The nested document structure allows us to always fetch information about the question that an answer is referring to alongside the answer in a single query. This way we can display answer search results in the context of its question without having to do an extra lookup. Our hypothesis is that this new structure should give us a better search relevance but this is something we'll have to carefully monitor and verify.
Chances are that this new way of querying and presenting search results is a good candidate to be used in our regular site search. Before we can do that, we have to look at query performance, relevance and number of successful searches and see if this proves to be an actual overall improvement.
A smoother search experience
For the longest time, finding content from Stack Overflow when searching for answers on Teams has been exclusively available to Teams instances hosted on stackoverflow.com. The way our architecture is set up made it trivial to provide this feature to Teams customers but impossible for the more isolated hosting models that some of our Enterprise customers require. We’re happy that unified search can bring a similarly smooth search experience to our Enterprise customers and help them find questions and answers from stackoverflow.com right within their cloud or on-premise hosted Teams instances.