
[Ed. note: While we take some time to rest up over the holidays and prepare for next year, we are re-publishing our top ten posts for the year. Please enjoy our favorite work this year and we’ll see you in 2022.]
They say there’s a kernel of truth behind every joke. In the case of our recent April Fools gag, it might be more like an entire cob, perhaps a bushel of truth. We wanted to embrace a classic Stack Overflow meme and tweak one of our core principles. Our company was inspired by the founders frustration with websites that kept answers to coding questions behind paywalls. What would the world look like if we suddenly decided to monetize the act of copying code from Stack Overflow?
Ok, jokes over, hope everyone had a good laugh and no one got too freaked out. But wait, there’s more. Once we set up a system to react every time someone typed Command+C, we realized there was also an opportunity to learn about how people use our site. We were able to catalog every copy command made on Stack Overflow over the course of two weeks, and here’s what we found.
You are not alone
One out of every four users who visits a Stack Overflow question copies something within five minutes of hitting the page. That adds up to 40,623,987 copies across 7,305,042 posts and comments between March 26th and April 9th. People copy from answers about ten times as often as they do from questions and about 35 times as often as they do from comments. People copy from code blocks more than ten times as often as they do from the surrounding text, and surprisingly, we see more copies being made on questions without accepted answers than we do on questions which are accepted.
So, if you’ve ever felt bad about copying code from our site instead of writing it from scratch, forgive yourself! Why recreate the wheel when someone else has done the hard work? We call this knowledge reuse - you’re reusing what others have already learned, created, and proven. Knowledge reuse isn't a bad thing - it helps you learn, get working code faster, and reduces your frustration. Our whole site runs on knowledge reuse - it’s the altruistic mentorship that makes Stack Overflow such a powerful community.
You can stand on the shoulders of giants and use their prior lessons learned to build new things of value. You should still follow some basic best practices to prevent bugs or safety issues from sneaking into your code when copying, so make sure you educate yourself before grabbing and pasting. And of course, be aware that some code requires a certain license to use. Beyond that, we encourage everyone to share in the benefits of what the community has created.
That’s the high level TL;DR, but for folks who want a deep dive into all the things we learned while studying the copy data, please read on for some marvelous insights and charts from David Gibson, a data analyst on our product marketing team. If you want to hear about how we built the software modal and physical keyboard behind our April Fools joke, check out the podcast below.
As someone who has been unapologetically copying from Stack Overflow for years, I was not surprised to see the millions of copy events rolling in. What did surprise me was the number of questions we could finally answer. How many people really are copying from Stack Overflow? Are people just copying code? Are people more likely to copy the accepted answer?
To add some direction to the analysis, the team and I came up with a list of questions that we wanted to answer. What started as a joke has snowballed into a worthwhile exploration, producing new insights and sparking many internal conversations about how we can continue to innovate our public platform and bring more value to Stack Overflow for Teams.
The data
Using our homegrown web tracking tool, we created custom events to capture when a user copied from the site. With these events we were able to capture many different attributes; tags, question answer or comment, code block or plain text, copier reputation and post score, region, and if the post was accepted or not. We pretty much captured everything except the actual text being copied.

We collected data for two full weeks, from March 26th 2021 to April 9th 2021. The following analysis is based on the behavior during that time.
Questions
Ben already mentioned some of the high-level stats that quickly proved what people had long joked about: everyone is copying from Stack Overflow. We also quickly realized that the overall copy behavior closely followed what we already knew about our site traffic. Most copies occurred during the work week and during working hours. Our largest geographies make up the majority of copies; Asia 33%, Europe 30%, and North America 26%. Finally, 86% of all copies came from anonymous users, aka users with 0 rep.
Things started to become more interesting when we asked more detailed questions about who was copying and what they were copying.
Are higher rep users copying more?
To start, we wanted to see if our higher reputation users are copying more.
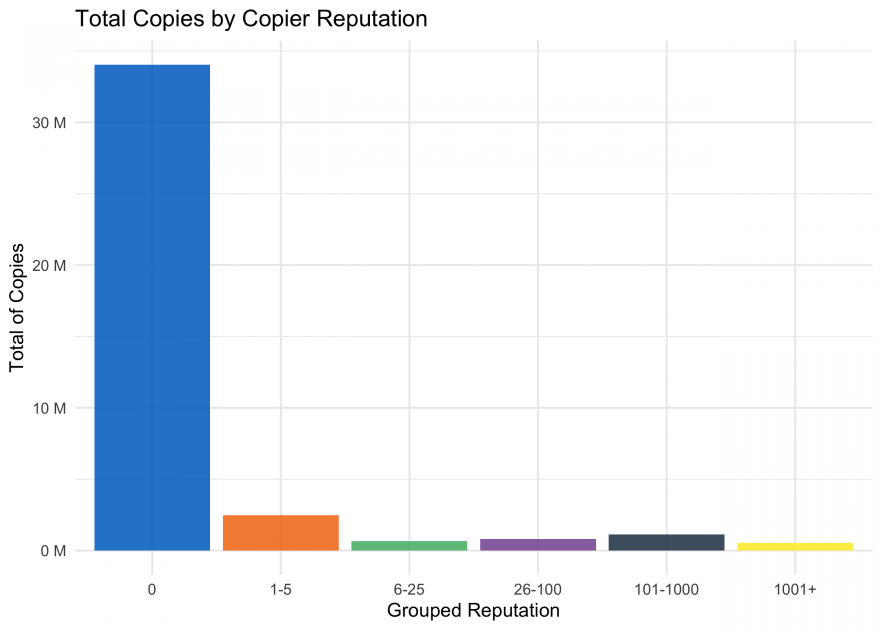
We can see that the majority of copies are coming from users with 0 reputation. These are our anonymous users because you immediately get 1 rep by creating an account. It is possible that some of these copies are from users with an account but are not logged in. Unfortunately, there is not a way for us to test this theory.
Since the majority of the users on our platform have a lower rep, let’s remove the groupings to see if we can normalize our data. By looking at Count of Copies Per User instead of Total Copies, we can see the average number of copies a user makes by their reputation.
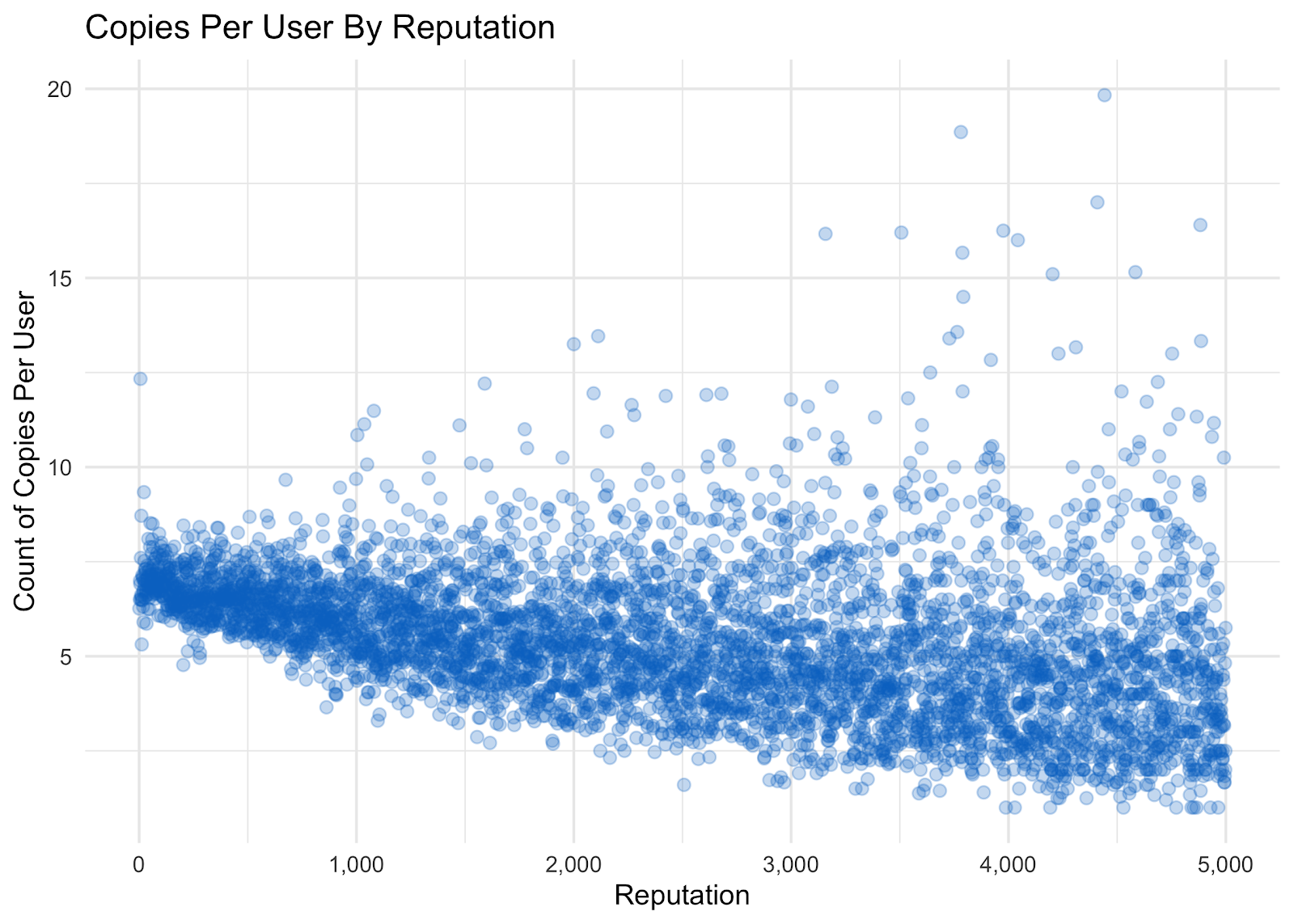
When looking at this visualization, it appears that as Reputation increases, the Count of Copies Per User decreases. So the higher a user’s reputation, the less often they are copying. This relationship is present but is not very strong, so I am not confident in saying either higher or lower reputation users copy more. Developers who are learning often have a lower reputation and are looking for things that can accelerate their learning and get them started quickly. As developers build their expertise, they also build their reputation, and they focus on more precise challenges, things that may not be possible to copy from Stack Overflow.
Are accepted posts copied more?
When we think of an accepted answer, we may think it is the best one, and infer it is copied much more than non-accepted answers. Looking at the data, however, we find 52.4% of copies come from answers that are not accepted. But on average, accepted answers get seven copies per unique post while non-accepted answers get five copies per unique post. So more copies come from non-accepted answers, but there is higher knowledge reuse from accepted answers. At Stack Overflow, we define knowledge reuse as reusing what others have already learned, created, and proved.

It is worth noting that a question may not even have an accepted answer. Take this answer: it has almost 4,984 up-votes and was copied 7,943 unique times during our study, but is not accepted. Actually, none of the answers have been accepted. It could be because the question poster has not been seen since 2010, but also many of the other answers are valid.
Are higher scored posts copied more?
So if accepted answers are not copied more, then answers with a higher score answers must be copied more, right? Let’s find out!
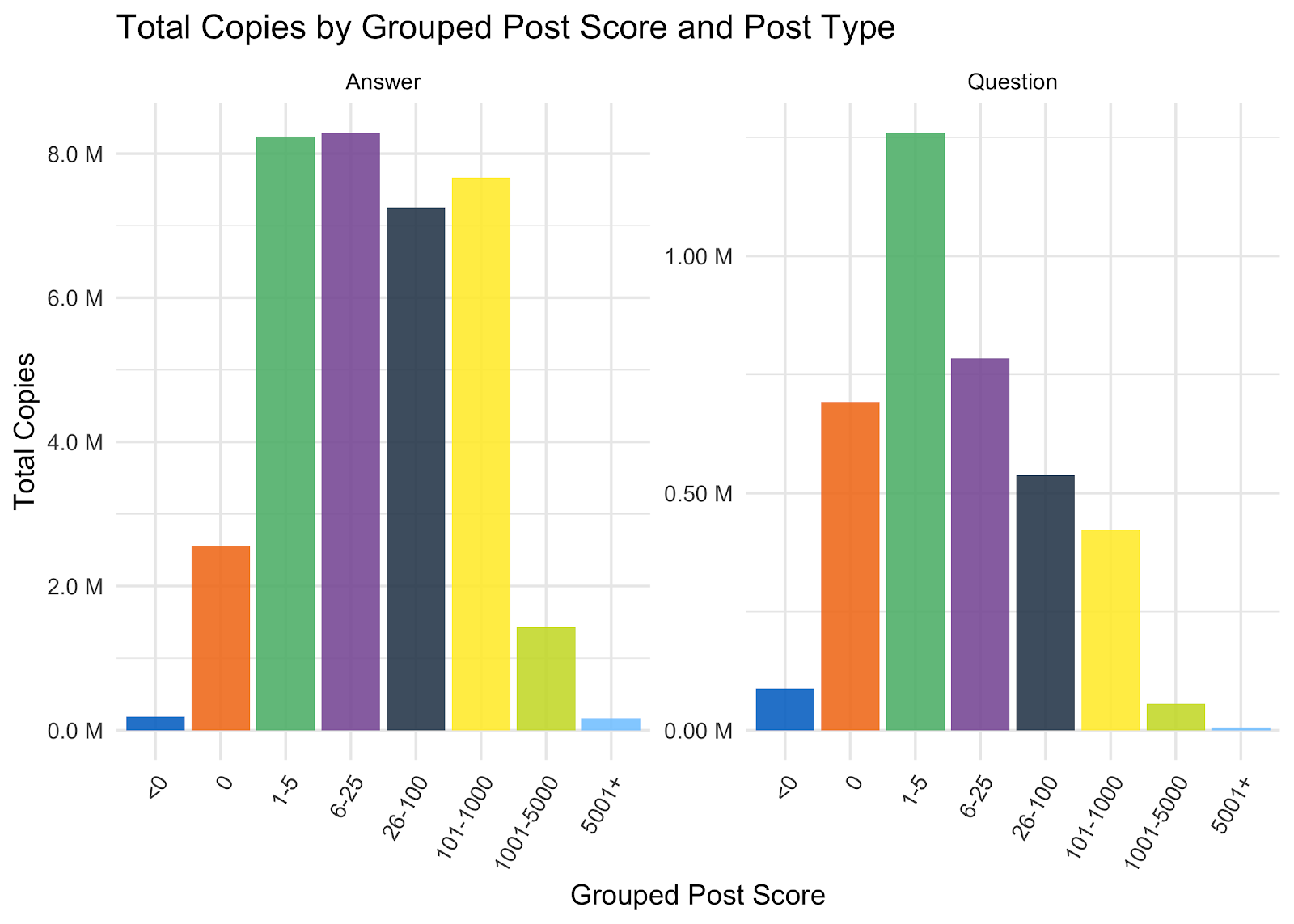
We see for Answers it seems to be pretty evenly split across our defined score groupings from 1 to 1000. As for questions, the majority of copies are from posts with 1-5 points. I suspect that is because users are copying the question to reproduce it and eventually post an answer.
Similar to when looking at user reputation, the majority of posts on the site have a lower score. To normalize this, let’s look at the copies per post.
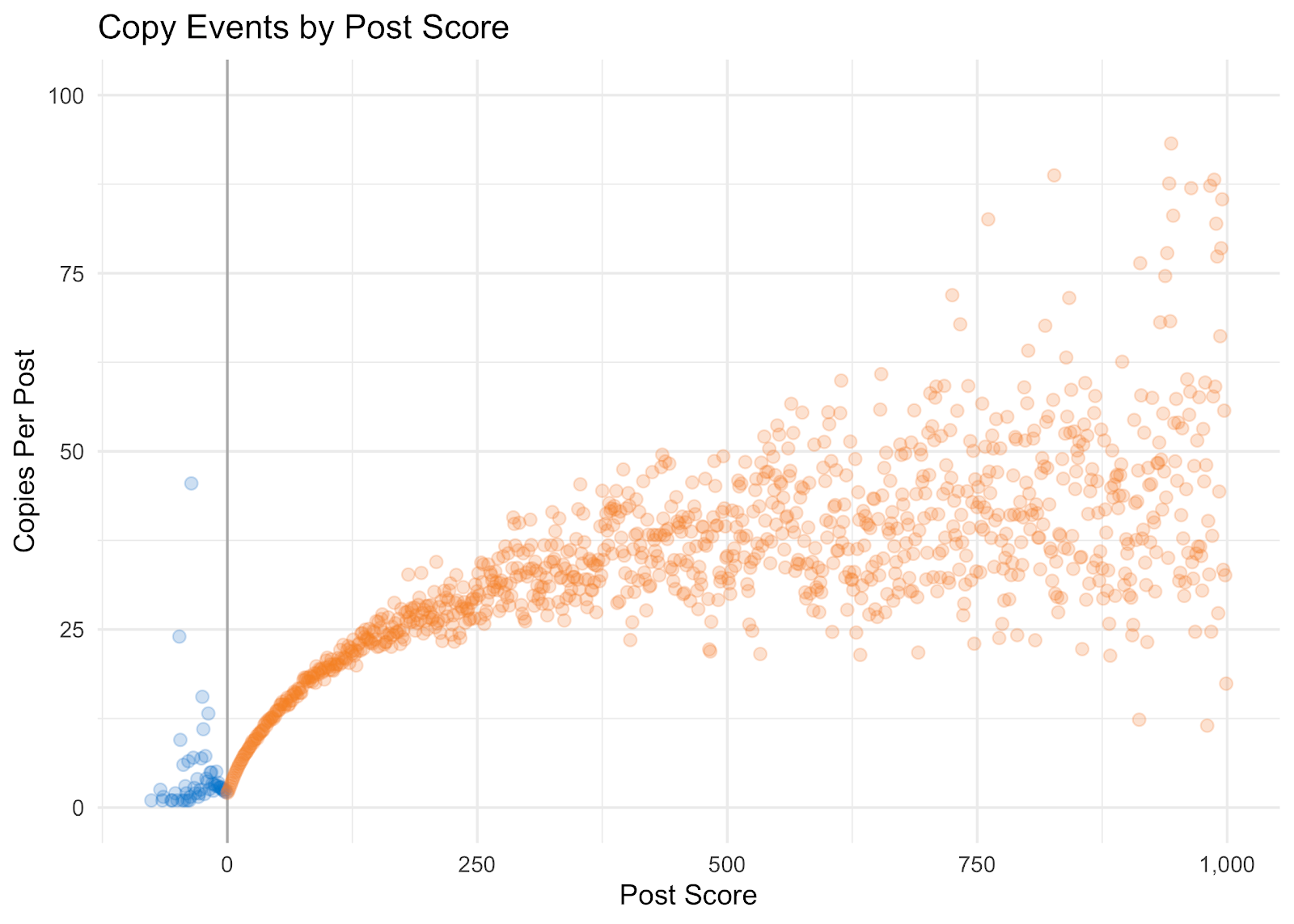
We can plainly see that as a post increases in Post Score so does the Copies Per Post. This makes sense because as a post increases in score it is more likely that the knowledge is being reused by our community.
Do people copy downvoted answers?
But what about those blue dots with a negative score? Why would anyone copy down-voted answers? Well, we never want to judge a book by its cover.
Take a look at this answer. It was our most copied down-voted answer with a score of -2 and a total of 288 copies. Looking closer, it appears to be a more concise version of the accepted answer above it that has a score of 29 and had a total of 493 copies. Although our negative score post did not have more copies, it is the perfect example of a “too long didn’t read” post.
What are the most copied tags?
Now for the question I was most excited to answer: what tags are being copied the most? Unfortunately, due to the scale of the data and available resources, I was unable to parse out nested tags. For example, the html tag will not include posts within the |html|css| tag grouping.
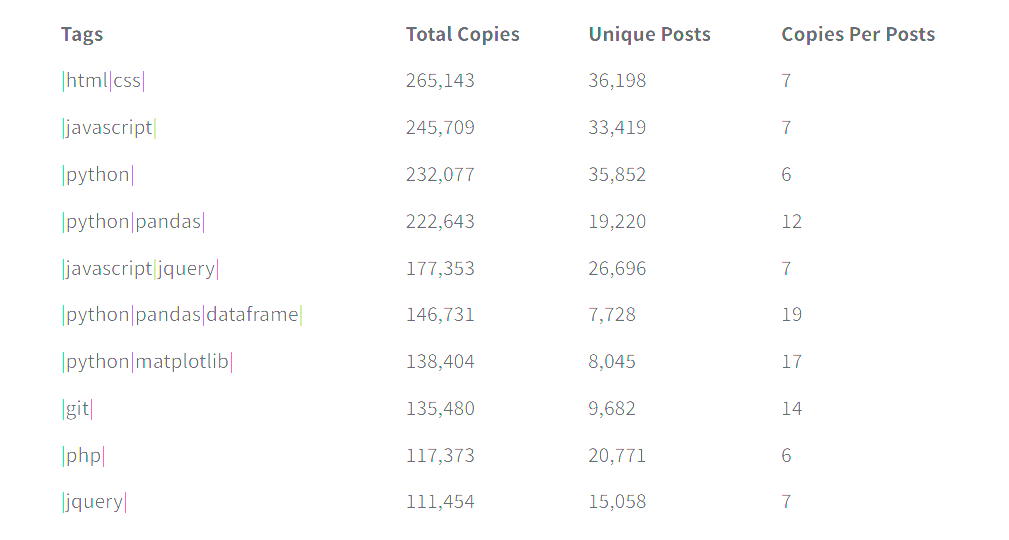
Top ten tags copied
Not to my surprise, the tags receiving the most copies are some of the most popular and active tags on Stack Overflow. The one thing that jumped out to me is python appears in four of the top tag groupings. Three of them are data analytics specific tag groups; |python|pandas|, |python|pandas|dataframe| and |python|matplotlib|. As a data nerd myself I love to see more people learning these tools.
Top ten tags with most copies per post
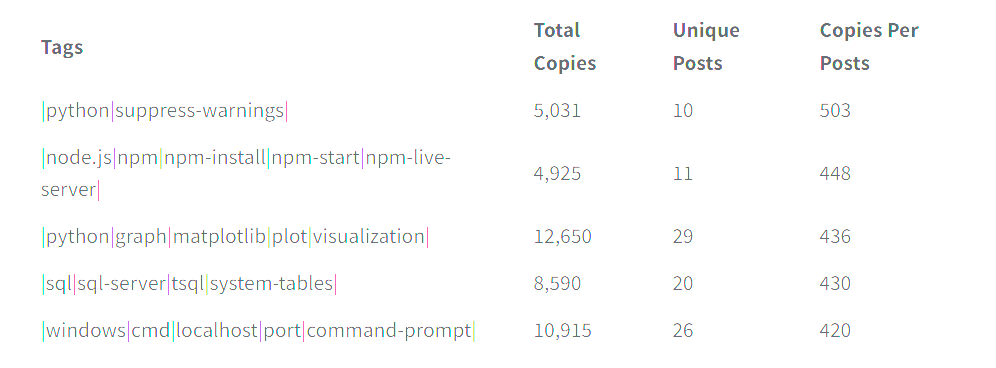
In addition to looking at the tags with the most copies, I wanted to see what tags have the highest copies per post. Filtering for tags with at least ten unique posts, we can plainly see as tags become more specific, they receive more Copies Per Post.
What are the most copied posts?
Now to answer the question I am sure many of you are interested in. What post received the most copies?
Answer with code block
With a post score of 3,497 and 11,829 copies, I am happy to announce that How to iterate over rows in a DataFrame in Pandas received the most copies. Answered in 2013, this question continues to help thousands of people each week.
Answer plain text
As for the most copied answer with plain text, we have TypeError: this.getOptions is not a function [closed] with a post score of 218 and 1,570 total copies. Although we were unable to confirm this I suspect that the `sass-loader@10.1.1` is being copied.
Question code block
And the most copied question with a post score of 2,147 and 3,665 copies, we have How to create an HTML button that acts like a link?
Question plain text
Finally, the most copied question with plain text with a post score of 322 and 261 copies, we have Updates were rejected because the tip of your current branch is behind its remote counterpart. This one is a little tricky because there are a handful of git commands not in code blocks that could easily be the copied part of the question. But as we are not capturing the actually copied text, we cannot confirm this.
Comment
It’s important that answers are not everything on Stack Overflow. Sometimes all you need is one useful comment. Here are the most copied comments!
https://stackoverflow.com/questions/332289/#comment47852929 - Comment score: 938, Copies: 4,924
https://stackoverflow.com/questions/41182205/#comment71717506 - Comment score: 5, Copies: 492
The first comment is our most copied comment across the site, and the second comment is our “unsung hero” as it only has a post score of five but was our sixth most copied comment.
UPDATE: There has been a lot of interest in purchasing a real life version of our prank. The good news is we anticipated this might happen and we’ve been working on something along these lines. Stay tuned for more!