
Back in November of last year when the announcement was made that Ingress-NGINX was being retired, we, like many others, were caught a bit off guard. Ingress-NGINX had been handling our traffic routing since moving to Kubernetes. There were some discussions about the new Gateway API that supersedes Ingress, and whether it might be useful to move to it, but no serious amount of energy was invested. Ingress-NGINX was working fine, and we had plenty of other work to do. Now, with our hand being forced by the retirement, we needed to make a plan and fit it into the near term road map.
Coming up with a plan
With a vast landscape of options, we needed to limit the possibilities before we started installing some implementations and testing them. We were pretty sure we’d like to use this opportunity to move to Gateway API, rather than another Ingress controller, and take advantage of the new features and better role separation. We also needed to get this done quickly however, so moving to another Ingress implementation could also be an option, if there were headwinds moving to Gateway API.
With some initial research, we established some criteria to narrow the playing field to three Gateway implementations and two Ingress options as a backup.
Gateway API
- NGINX Gateway fabric
- Traefik
- Istio
Ingress
- F5 NGINX ingress
- Traefik
Our first criteria was that our replacement had to be on the list of fully-conformant implementations. This would give us a good baseline for comparison. We run in GCP and Azure, so that eliminated any cloud specific solutions. From there, we looked at the 1.4 feature matrix, a third-party benchmark, and some of the unique features of each implementation. This left us with the three aforementioned options.
Sadly, our old friend HAProxy was on the list of stale implementations when we started this project. We used HAProxy in the data center reliably for many years, before moving Stack Overflow to GKE. It definitely would have made the cut for testing. At the time of writing, it’s moved to fully conformant.
As far as backup options for sticking with Ingress, Traefik made a compelling case with its annotation compatibility with NGINX. In practice, most of the annotations we were using weren’t covered, so that option lost its luster. The F5 NGINX ingress implementation looked to potentially be a safe bet, but we found the advanced routing relied on implementation-specific resources rather than the standard Kubernetes types. This causes problems when you try to integrate other controllers that rely on the standard interfaces being used.
Ultimately, we couldn’t make the case for switching to another ingress, so we dropped these from testing pretty early.
Understanding our current usage patterns
In order to build out our use cases for testing, we dumped all of the ingress objects on our main production clusters to YAML files, and used Claude to analyze and sort them into different use case buckets. Most of our routing was very straightforward, with a few outliers. This left us with roughly half a dozen use case tests to write, along with two different scalability benchmarks to run.
Our testing environment
For the test setup, the main backend was an HTTPBin deployment. It’s a great tool for testing anything HTTP related, allowing you to introspect both the request and response from a test client. A good example of this: we have a case where we need to dynamically overwrite host headers for some specific traffic. HTTPBin has a /headers endpoint that will return the request headers back as a JSON response. That allows us to write a test case where we send host header X, and expect the server to get host header Y.
A second backend was deployed at perf.This was a very simple Go web server that should be able to respond to a large number of requests very quickly. This will allow us to push the request rate of the gateway very high to see where the performance limitations are. A parameter was added to the web server to allow us to pass in a latency value to simulate slower responses, in order to test performance where the number of connections and active requests begin to pile up. I was unaware, but HTTPBin has an endpoint with this same capability. I was unsure about the performance of HTTPBin under heavy load so the tests use the Go server instead. The testing setup looked like this.
What we found
Setup for the three implementations was fairly simple, though one initial annoyance I found with Traefik was the need to configure a Traefik “entrypoint”. This is a Traefik specific piece of configuration that sets up a TCP listener. If you don’t add this and create a gateway, the listeners you add to the gateway will throw an error. This breaks the gateway abstraction to some degree.
All three implementations were able to handle our use cases. Of the Gateway API features that were interesting to us, Istio checked the most boxes and Traefik the least. One thing we found out quickly is some of the Gateway API features looked good on paper, but lacked the depth we needed. For example, the header modification feature in HTTPRoute only handles static values. In the aforementioned case where we needed a dynamic regex, we had to fall back to each implementation’s extension points. These were all flexible enough to meet our needs and allowed referencing different behavior from the context of an xRoute or Gateway depending on your needs and the function performed. For the cases we tested, the Istio filters were significantly more complex syntactically than the NGINX or Traefik equivalent.
In some cases, implementation-specific behavior changed enough that we had to modify our applications to get it working. We’re currently using ngx_http_auth_request_module to forward requests to an authentication service. The other implementations have similar functionality, but Istio’s external authorization has significantly different behavior. Complex integrations like these are pain points and slow things down considerably when you have to migrate to a new solution.
Performance testing
I love performance analysis, so it’s very easy for me to go down rabbit holes and collect very detailed information. In this instance, with time and resources very limited, I had to be sure I was keeping things simple and practical. It’s likely at some scale, there would be very clear winners and losers. But we weren’t trying to perform a generic benchmark comparison. We simply needed to know if these implementations would meet our current scalability requirements.
We had two primary scaling factors we needed to test. For our public Stack Exchange network of sites, we needed to verify that each implementation could handle some multiple of our daily traffic with a reasonable number of replicas. For our enterprise product, each customer currently gets eight Ingress resources, so we want to test scaling the number of HTTPRoutes.
For the RPS benchmark against the gateways, we chose a target of 10,000 RPS, which would leave us some headroom above our normal steady state traffic. After some experimental rounds of testing, we set the test environment to have four replicas of each gateway, each on a separate node. These were e2-standard-4 GCP compute nodes. For the test client, we run K6 on a machine configured to handle the high number of connections. The client ran on an Azure Standard_DC8as_cc_v5 instance.
Initial RPS benchmark
We ran the tests with 0, 150, and 350ms of simulated server latency. All three implementations handled these initial tests without issue. The results from all the tests are relatively similar. Here are the results of the 150ms latency test run.
Traefik
http_req_duration..............: avg=188.27ms min=176ms
med=180.22ms max=820.56ms p(90)=195.11ms p(95)=219.31ms
NGINX
http_req_duration..............: avg=205.34ms min=176.15ms
med=183.13ms max=1.83s p(90)=244.14ms p(95)=297.59ms
Istio
http_req_duration..............: avg=186.73ms min=176.03ms
med=180.52ms max=3.48s p(90)=194.34ms p(95)=216.32ms
Route creation benchmark
Initially, we ran this test with a target of 5000 HTTPRoutes. While all three successfully handled converging on this number of routes, we find out later that our practical limit is much lower. I read in this third-party benchmark about a few problems with Traefik and NGINX and their handling of routing changes. We set up a similar test that created 5000 HTTPRoutes, each with a single path rule, and concurrently sent requests to those paths until they returned the correct response. This allowed us to see that they were all being routed correctly.
While we didn’t see the exact issues from the third-party tests where Traefik didn’t load all the routes, we did see it take significantly longer than the other two implementations. You can see here the original test failing for Traefik since it timed out after five minutes. Traefik did load all the routes, taking only slightly longer than the five minute timeout.
=== RUN TestRoutedPaths
=== RUN TestRoutedPaths/gw-nginx
gateway_test.go:443: 5000/5000 paths pending, retrying in 5s
gateway_test.go:443: 105/5000 paths pending, retrying in 5s
gateway_test.go:443: 105/5000 paths pending, retrying in 5s
gateway_test.go:443: 87/5000 paths pending, retrying in 5s
gateway_test.go:335: applied 5000 HTTPRoutes
gateway_test.go:443: 3/5000 paths pending, retrying in 5s
gateway_test.go:431: all 5000 routes converged in 42.047s
=== RUN TestRoutedPaths/gw-istio
gateway_test.go:443: 5000/5000 paths pending, retrying in 5s
gateway_test.go:443: 1167/5000 paths pending, retrying in 5s
gateway_test.go:443: 93/5000 paths pending, retrying in 5s
gateway_test.go:443: 93/5000 paths pending, retrying in 5s
gateway_test.go:443: 32/5000 paths pending, retrying in 5s
gateway_test.go:443: 32/5000 paths pending, retrying in 5s
gateway_test.go:335: applied 5000 HTTPRoutes
gateway_test.go:431: all 5000 routes converged in 41.981s
=== RUN TestRoutedPaths/gw-traefik
gateway_test.go:443: 5000/5000 paths pending, retrying in 5s
gateway_test.go:443: 4939/5000 paths pending, retrying in 5s
gateway_test.go:443: 4921/5000 paths pending, retrying in 5s
gateway_test.go:335: applied 5000 HTTPRoutes
gateway_test.go:443: 4871/5000 paths pending, retrying in 5s
gateway_test.go:443: 4856/5000 paths pending, retrying in 5s
gateway_test.go:443: 4833/5000 paths pending, retrying in 5s
gateway_test.go:443: 4827/5000 paths pending, retrying in 5s
gateway_test.go:443: 4823/5000 paths pending, retrying in 5s
gateway_test.go:443: 4820/5000 paths pending, retrying in 5s
gateway_test.go:443: 4816/5000 paths pending, retrying in 5s
gateway_test.go:443: 4811/5000 paths pending, retrying in 5s
...
--- FAIL: TestRoutedPaths (441.53s)
--- PASS: TestRoutedPaths/gw-nginx (56.68s)
--- PASS: TestRoutedPaths/gw-istio (79.96s)
--- FAIL: TestRoutedPaths/gw-traefik (304.88s)
--- FAIL: TestRoutedPaths (410.94s)
--- PASS: TestRoutedPaths/gw-nginx (60.82s)
--- PASS: TestRoutedPaths/gw-istio (46.98s)
--- FAIL: TestRoutedPaths/gw-traefik (303.13s)Handling traffic during route updates
Once we had the gateway loaded with 5000 routes, we discovered this was too ambitious a target. Running the previous K6 benchmark that generated 10k RPS through the gateway failed miserably. Latency times were incredibly high and the number of active requests would climb until the test client exploded. Since we’d probably never need more than 1,000 routes on a single gateway, we revised this target down and reran the K6 benchmark again. This time response times were similar to our original results.
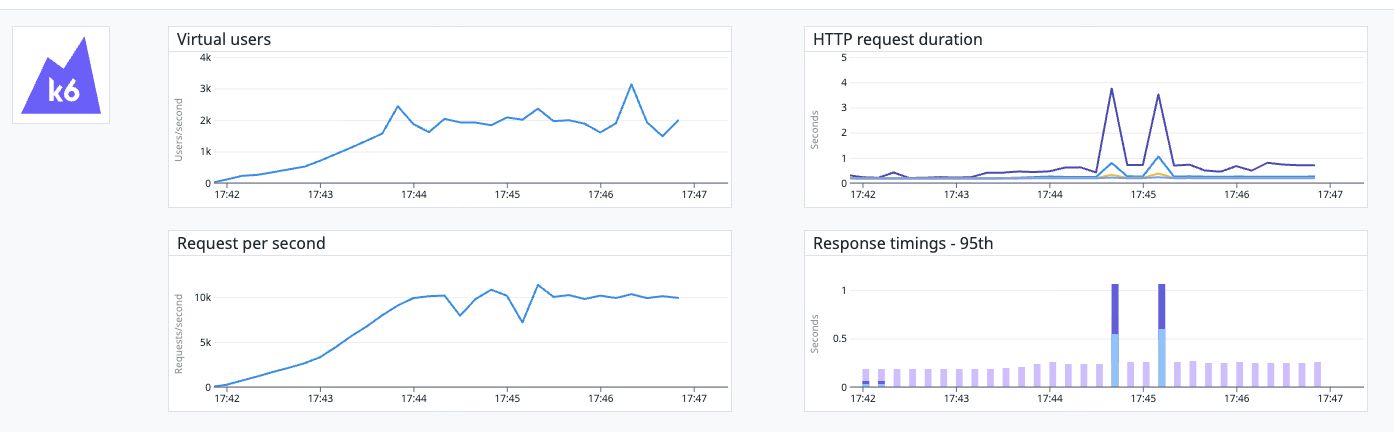
We also tested modifying the routes while the K6 traffic test ran. Istio and Traefik remained unaffected, but NGINX saw significant latency spikes when even a single HTTPRoute was updated, when there were 1,000 routes configured. You can see in the graph the two large latency spikes that occurred during route updates.
NGINX route update 10kRPS 150ms simulated latency
Our decision
After performing all of our testing and analyzing the features and characteristics of these three implementations, we have decided to move forward with Istio. The primary factor being Istio’s stability and performance through all of the testing. I believe we could be successful with any of the options, but in the end Istio seemed the most solid of the three. The fact that it has many advanced features beyond our current use case is also interesting.
In the coming weeks we’ll be performing the migration. If we run into anything of note I’ll be glad to write a follow-up post to share what we found.