I think we've finally arrived at a semi-stable network layout for running Stack Overflow and the rest of the trilogy. Here's a diagram of our current network layout:
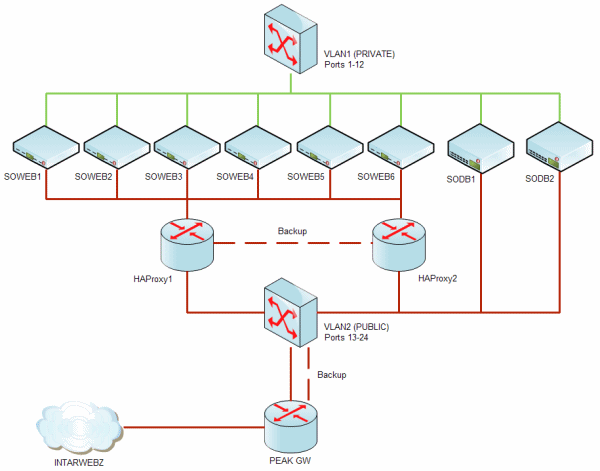
The most recent changes were all in the name of redundancy:
- move to dual HAProxy routing instances
- add a third Stack Overflow server to the HAProxy rotation to handle steadily growing site traffic
- push our static content (sstatic.net), which is shared amongst all Trilogy sites, to five different servers
- take advantage of our datacenter's ability to deliver dual switched connections to the internet
The last part is in reference to an unfortunate recent switch outage at PEAK, our datacenter provider. It was handled swiftly, but now there is no longer a single point of failure upstream of us at PEAK -- we're being served by two different switches on two different internet connections. Kudos to PEAK for not only handling this rapidly at the time, but also more permanently fixing it in a way that makes it less likely to happen next time. What motivated a lot of this was a little scare we had about a week ago. The single server that hosted our single HAProxy instance and the sstatic.net content experienced some kind of bizarre, one-time, and still-unexplainable (edit: now explained) networking issue. This sounds minor, and it should have been, but it was a major bummer in actuality because having that one server become unavailable on the network effectively took out every single site we run with the exception of Careers. We sure lost the server lottery on that one.

Not good, obviously. We redoubled our efforts to become more redundant. We recently added a sixth 1U web tier machine so our server rack is now completely full. We have way, way more server power than we need. That's 6 very capable web tier boxes and 2 beefy database tier boxes all told. Each ready and willing to dynamically share whatever load we want them to. We just had to figure out how to do it. We're big fans of HAProxy, which the guys at Reddit turned us on to. It has been working flawlessly for us in load balancing Stack Overflow between two -- and now three -- servers. We currently use IP-hash based routing to determine which server visitors to stackoverflow.com end up on. This helps improve local server cache hit ratios, as users "stick" to the same server for as long as they hold the same IP address. (No, we don't use a shared server farm memory cache like Memcached or Velocity quite yet.) While this works, it does lead to some slightly imbalanced loads, particularly when single-IP whales like Google thunder through your neighborhood. We found that going from two to three servers produced a surprisingly large improvement in server load balance, even with our less-than-optimal IP hash routing choice. HAProxy is a proven solution for us. But we needed some way of using two HAProxies -- on two different servers. Geoff did some research and came up with Heartbeat, which is a part of Linux-HA. This works by "sharing" one IP between two machines (in this case, two Linux virtual machines). It dynamically switches the IP from one server to the other when the heartbeat times out. We now have this set up and it works brilliantly; shut down one of the two VMs and within two ping -t cycles, that IP address is automagically and seamlessly switched to the other VM. There is a very brief interruption of service during this switchover, but it's no more than a few seconds. We also moved our sstatic.net shared content from living on a single webserver, to living on five different webservers. Our dual HAProxy instance is also responsible for routing sstatic.net traffic -- as visitors request sstatic.net files, those requests are served in perfect round-robin fashion by whichever of the 5 webservers HAProxy sees as alive at the moment. Given that these HAProxy instances are super-critical not only to Stack Overflow but every site in the trilogy (because they serve shared static content), we need constant reassurance that they're healthy. We already use Pingdom as an external monitor and alert service for our existing websites, so we added our HAProxy instances to the mix with an aggressive ping schedule. If something bad happens to either HAProxy instance, we should know about it within a few minutes. There might have been some momentary interruptions in service while we set this all up, so our apologies for that. But the net result is a more resilient, more reliable Stack Overflow and friends for you! We know the importance of building a secure, reliable network. Companies are continuously searching for the network experts to manage this crucial task. Check out our listings for the latest network engineer jobs.