
Warning: This post is long. While working through this massive server upgrade/migration process, tears were shed, many cuss words were uttered, along with a general feeling of frustration, which ultimately culminated into extreme happiness once the migration was completed. The scale and complexity of the implementation factor into the length of this post, and I’ll share my thought process on how this was executed, so here goes.
When we upgraded to SQL Server 2017 last year, we didn’t make any changes to the operating system on our main production servers. They were Windows Server 2012 (not R2), and we knew that moving to another operating system would be painful because it would involve tearing down each of the clusters, rebuilding them, and potentially having extended downtime - which we really can’t have. It sounded too difficult at the time, so it was punted…again.
When I was mapping out projects for 2019, at the top of my list was to move from Windows Server 2012 to Windows Server 2019, because ‘hey, it’s 2019 let’s move away from 7 year old OS’. From the start, it was obvious this would be extremely complicated, but why not start the new year off with a crazy project that gets us in a position to move to SQL Server 2019. I had never done anything like this before. In January, I started working out how we were going to upgrade our existing production SQL Servers from Windows 2012. And in this very long post I explain all the planning, testing, unexpected issues, and implementation of this move.
Reasoning
My first step was to identify the benefits of migration. I would be spending a considerable amount of time on the project, so it was important to know what we would gain from the upgrade. There were two obvious wins 1) moving away from a 7 year old operating system, and 2) the move also would allow us to move to SQL Server 2019 (yay… more upgrades). However, the biggest benefit we were hoping for was an improvement with our availability group log transport throughput. Our current production clusters each have 3 nodes - 2 (primary and local secondary) in the NYC area and 1 (remote secondary) in Colorado. We tend to see significant delays and non-synchronizing databases in Colorado. Upgrading from 2012 to Windows 2016+ would net us gains in performance, and hopefully reduce some of our syncing issues. For me, that would be a huge plus, as I wanted to avoid seeing stuff like this repeatedly during the week:

Phase 1: Lab Testing…All The Things
I’m incredibly lucky to have a lab environment to play with. At the start of this project, I had two lab Windows Server Failover Clusters (WSFC) - each with 2 nodes that were running Windows Server 2016, SQL Server 2017. Each cluster had availability groups (AG), as well as a distributed availability group (DAG) between the two clusters. Since I didn’t want to destroy these clusters for the test, I needed to create new servers for testing.
My goal was to replicate our production set-up on a much smaller scale. From there, I’d work through different scenarios to get to the final desired result. The 2012 production clusters looked like this:
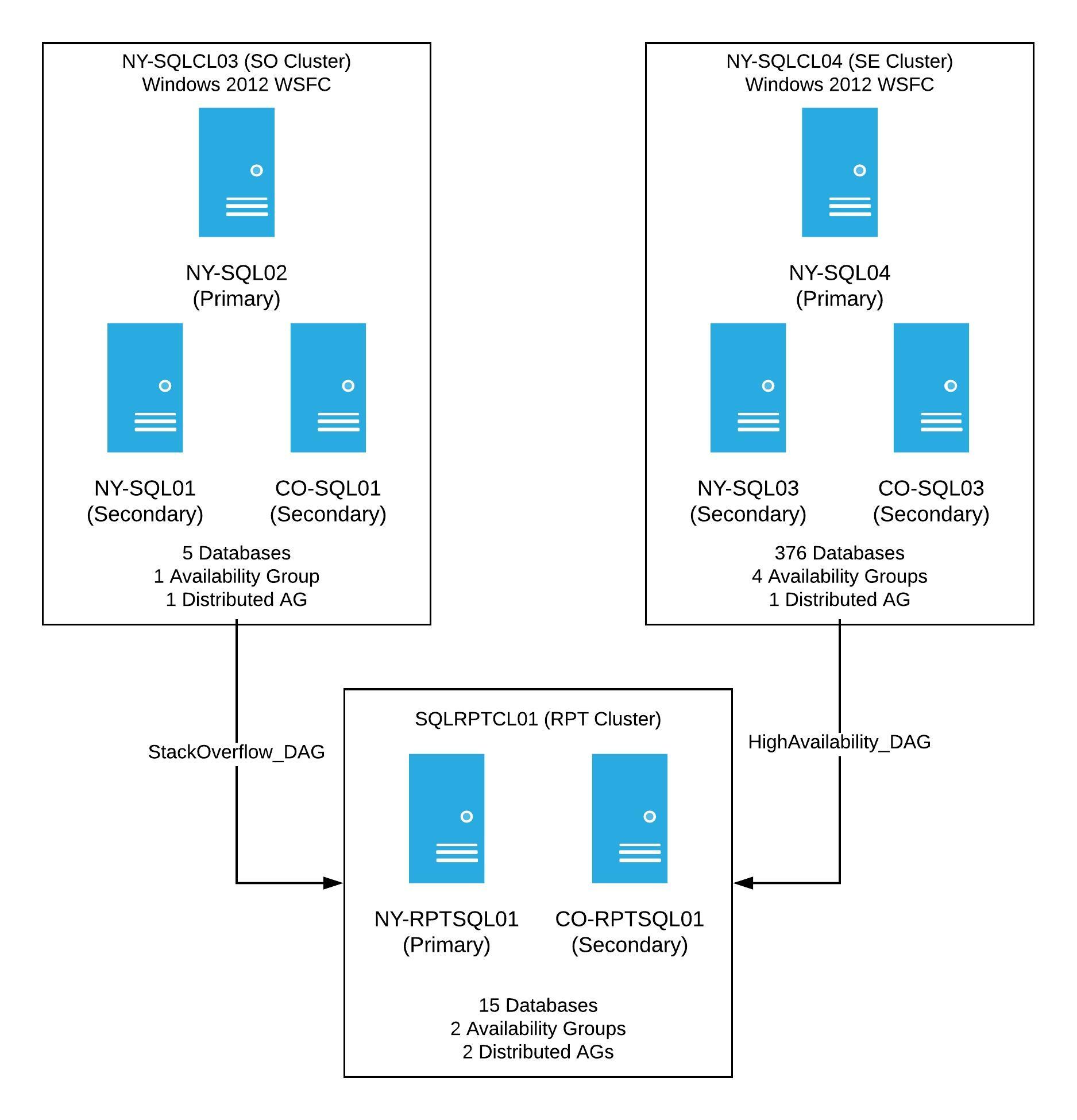
Production had two WSFCs running Windows Server 2012, each with 3 nodes. Both clusters have at least one availability group, as well as one distributed availability group going to a reporting cluster. Once this project was complete, the new clusters would look the same, however, these would have a new OS, new cluster names, and when finished, the primary SQL Server in each availability group would be the current NY Secondary.
In order to properly test, I needed 3 servers running Windows Server 2012. Well, guess what? We didn’t even have a way to install Windows Server 2012, and no longer had an image of the software. This left me hunting for a copy of it. Eventually I got one, but then our deployment process needed to be setup to work with 7 year old software. Once all those bits were in place, I was able to spin up my 3 servers to test with. At this point, I had a new 2012 cluster with 3 nodes (2 in NY, 1 in CO). All were running SQL Server 2017 with 2 availability groups, with one AG that was limited to this cluster, and a second AG that was modeled after one in a distributed availability group.

The "Will This Even Work" Test
Before I started breaking this new test cluster, we had the idea of creating another server with Windows Server 2019 to see if it would work with the new lab cluster - basically, a test to see if the data would sync. I spun up another new server; this time it was on a fancy new operating system, Windows Server 2019, with SQL Server 2017 and was all ready to start testing. The goal was to insert the 2019 server into the mix with 2012, so it would receive data from the old server cluster. I wanted it to look like this:
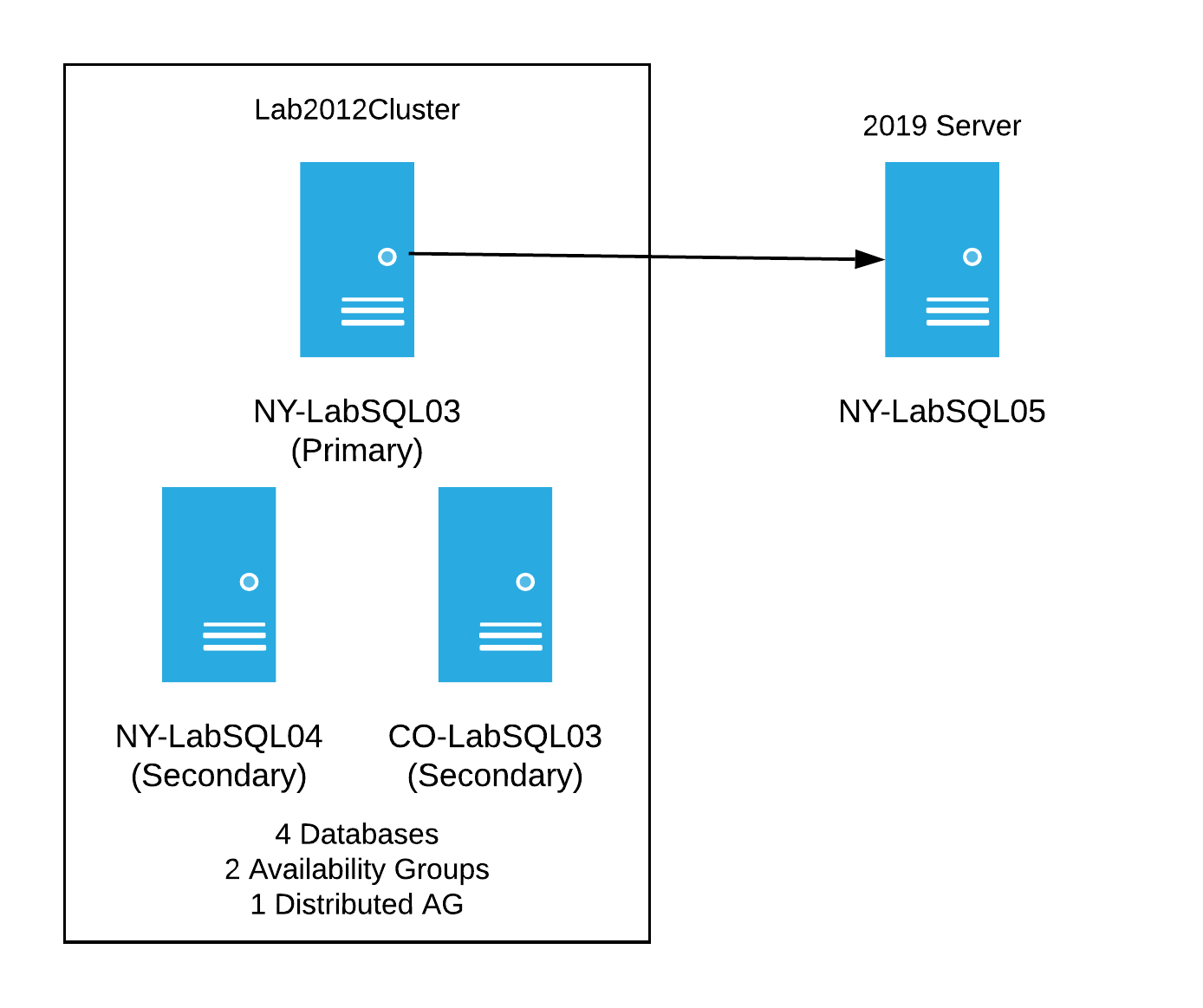
I tried many things to get this to work. I even tried things I knew wouldn’t work just to cross it off the list of things tested. Here’s a brief list of some of the things I tried:
- Putting the 2019 server into the existing 2012 cluster - as expected, this fails due to the operating systems being different.
- Attempting to add it to the existing AGs when not being in a cluster - this fails because it’s not in a cluster.
- Creating a separate single node cluster for the 2019 server and attempted to add as a replica to the AG. This failed as well.
None of these things worked. I was beginning to wonder how we were going to do this. My next test was to create a new distributed availability group for each existing availability group, using that as a way to insert the 2019 server into the mix. I finally hit on something that worked for the single server. After creating a new DAG between the 2012 and 2019 cluster, I had data syncing between two clusters on different operating systems. I was ecstatic to get this to work with one server, but how would I do this with the 3 servers in a single cluster, with all the AGs and distributed AGs already in play?
The Mock-up Production Test
Once I knew I could have clusters with different operating systems, synchronizing data via distributed AGs, I needed to attempt this with the new 2012 lab cluster. Since it was already working as a stand-alone cluster with SQL Server running, I wanted to set up a test that was as close as possible to what we have in production. I needed a replica of our reporting cluster. A bell went off in my head, ‘Ding! Ding!’ I had an existing 2016 cluster in my original lab environment - that would be perfect in this case.
My plan of attack for this test was to first setup a DAG between the 2012 cluster and the original lab cluster running on 2016. This would be similar to what we had in production at the time. Basically we’d have the following:
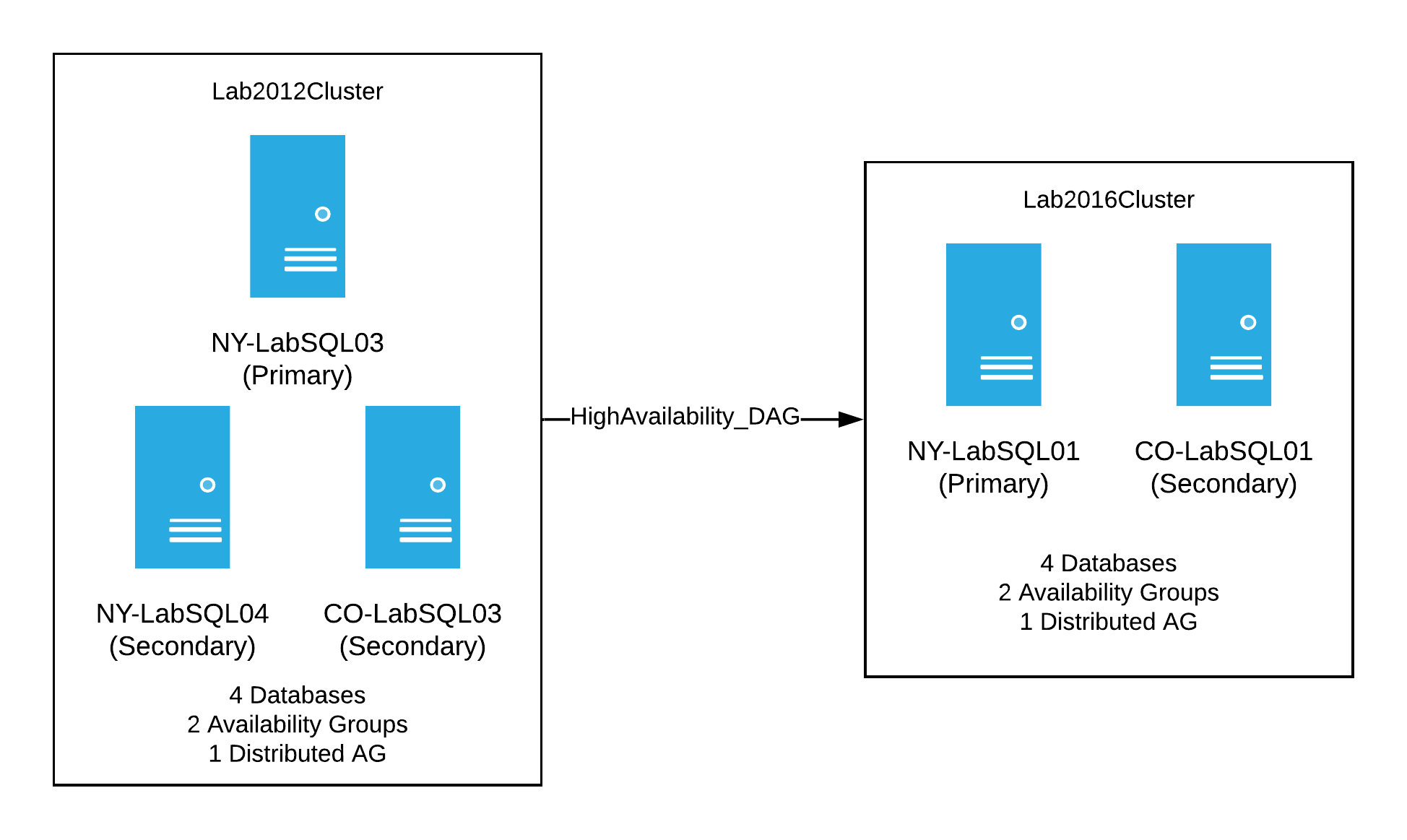
When that was setup and synchronizing, I had a decent, albeit, small version of our production setup. It was now time to start breaking things. My thinking was to start with the NY secondary server and perform the following steps:
- Evict it from the existing 2012 cluster
- Rebuild it with the Windows Server 2019
- Create a new WSFC with one node
- Install SQL Server 2017
- Finally, create new distributed AGs from the old cluster to the new one to sync the databases with that AG
My next step was to do the same thing with the CO secondary in the 2012 cluster. The difference being, it could just be added as a node to the new WSFC, and as a replica to the AGs in the new cluster. At this point in the process, I’d have the old 2012 cluster with a single server sending data to two clusters - the mocked up 2016 reporting cluster and the new 2019 cluster. Visually it’d look like this:

Before upgrading the last 2012 server, I would need to perform a failover of the distributed AGs from the 2012 cluster to the new 2019 cluster. In looking at this, there was one glaring problem…the reporting cluster. If I performed a failover of the distributed AGs to the new 2019 cluster, the reporting cluster would stop getting data. I saw there were two options:
- Perform the failover and let the reporting cluster fall out of sync until I could get it everything back in place
- Move the reporting cluster and it’s distributed AGs to the receive data before I failed over to the new 2019 cluster and “hope” things just starting syncing again.
Either way, the databases on the reporting cluster were going to fall out of sync, so I chose the first option for the lab.
Now that the decision was made, it was easy peasy to finish the move in the lab. There was only one server left in the old cluster, so my steps were to failover the distributed AGs to the new 2019 cluster (yes, I tested failing back just in case), destroy the 2012 cluster, rebuild the server with Windows 2019, add it to the 2019 WSFC, install SQL Server, and add it as a replica to all the AGs. Yay, everything was done! What’s left was just a bit of clean up of the reporting cluster distributed AGs, and then I was ready to move to production with the plan.
I spent the next week writing up all the steps to move to production. There were a lot of moving pieces for production. I had to move the following:
- 2 WSFC
- 6 servers with new OS, fresh SQL Server installs
- 5 availability groups with a total of about 385 databases
- 5 AGs means 5 temporary distributed AGs to help with the move
This also meant we needed new IP addresses for the clusters, AG listeners, as well as new names for the clusters, AGs, distributed AGs, and listeners. During my testing, I discovered that you can’t use the same names for these objects, even when they’re on different servers, which resulted in a lot of legwork to get prepped for the move to production, but I was ready…or so I thought.
Phase 2: The Part Where I Broke Dev
To read the rest of this post, head over to Taryn's blog.