
So…caching. What is it? It’s a way to get a quick payoff by not re-calculating or fetching things over and over, resulting in performance and cost wins. That’s even where the name comes from, it’s a short form of the “ca-ching!” cash register sound from the dark ages of 2014 when physical currency was still a thing, before Apple Pay. I’m a dad now, deal with it.
Let’s say we need to call an API or query a database server or just take a bajillion numbers (Google says that’s an actual word, I checked) and add them up. Those are all relatively crazy expensive. So we cache the result – we keep it handy for re-use.
Why Do We Cache?
I think it’s important here to discuss just how expensive some of the above things are. There are several layers of caching already in play in your modern computer. As a concrete example, we’re going to use one of our web servers, which currently houses a pair of Intel Xeon E5-2960 v3 CPUs and 2133MHz DIMMs. Cache access is a “how many cycles” feature of a processor, so by knowing that we always run at 3.06GHz (performance power mode), we can derive the latencies (Intel architecture reference here – these processors are in the Haswell generation):
- L1 (per core): 4 cycles or ~1.3ns latency - 12x 32KB+32KB
- L2 (per core): 12 cycles or ~3.92ns latency - 12x 256KB
- L3 (shared): 34 cycles or ~11.11ns latency - 30MB
- System memory: ~100ns latency - 8x 8GB
Each cache layer is able to store more, but is farther away. It’s a trade-off in processor design with balances in play. For example, more memory per core means (almost certainly) on average putting it farther away on the chip from the core, and that has costs in latency, opportunity costs, and power consumption. How far electrons have to travel has substantial impact at this scale; remember that distance is multiplied by billions every second.
And I didn’t get into disk latency above because we so very rarely touch disk. Why? Well, I guess to explain that we need to…look at disks. Ooooooooh shiny disks! But please don’t touch them after running around in socks. At Stack Overflow, anything production that’s not a backup or logging server is on SSDs. Local storage generally falls into a few tiers for us:
These numbers are changing all the time, so don’t focus on exact figures too much. What we’re trying to evaluate is the magnitude of the difference of these storage tiers. Let’s go down the list (assuming the lower bound of each, these are best case numbers):
- L1: 1.3ns
- L2: 3.92ns (3x slower)
- L3: 11.11ns (8.5x slower)
- DDR4 RAM: 100ns (77x slower)
- NVMe SSD: 120,000ns (92,307x slower)
- SATA/SAS SSD: 400,000ns (307,692x slower)
- Rotational HDD: 2–6ms (1,538,461x slower)
- Microsoft Live Login: 12 redirects and 5s (3,846,153,846x slower, approximately)
If numbers aren’t your thing, here’s a neat open source visualization (use the slider!) by Colin Scott (you can even go see how they’ve evolved over time – really neat):
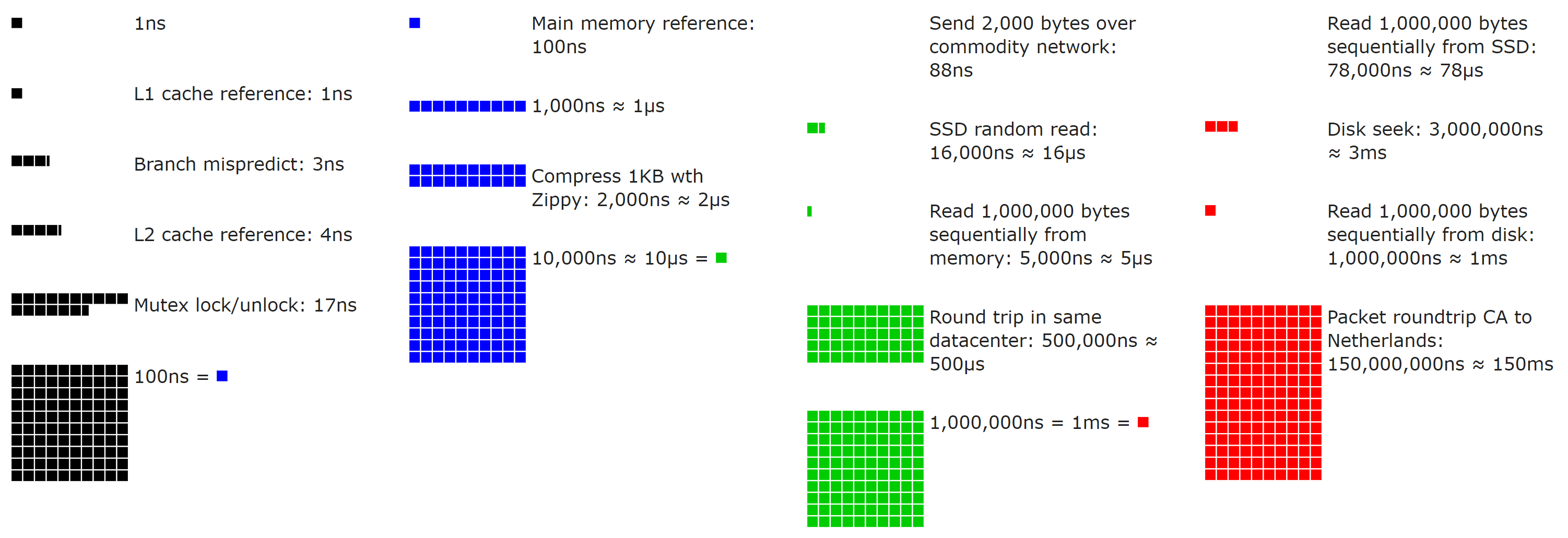
With those performance numbers and a sense of scale in mind, let’s add some numbers that matter every day. Let’s say our data source is X, where what X is doesn’t matter. It could be SQL, or a microservice, or a macroservice, or a leftpad service, or Redis, or a file on disk, etc. The key here is that we’re comparing that source’s performance to that of RAM. Let’s say our source takes…
- 100ns (from RAM - fast!)
- 1ms (10,000x slower)
- 100ms (100,000x slower)
- 1s (1,000,000x slower)
I don’t think we need to go further to illustrate the point: even things that take only 1 millisecond are way, way slower than local RAM. Remember: millisecond, microsecond, nanosecond – just in case anyone else forgets that a 1000ns != 1ms like I sometimes do…
But not all cache is local. For example, we use Redis for shared caching behind our web tier (which we’ll cover in a bit). Let’s say we’re going across our network to get it. For us, that’s a 0.17ms roundtrip and you need to also send some data. For small things (our usual), that’s going to be around 0.2–0.5ms total. Still 2,000–5,000x slower than local RAM, but also a lot faster than most sources. Remember, these numbers are because we’re in a small local LAN. Cloud latency will generally be higher, so measure to see your latency.
When we get the data, maybe we also want to massage it in some way. Probably Swedish. Maybe we need totals, maybe we need to filter, maybe we need to encode it, maybe we need to fudge with it randomly just to trick you. That was a test to see if you’re still reading. You passed! Whatever the reason, the commonality is generally we want to do <x> once, and not every time we serve it.
Sometimes we’re saving latency and sometimes we’re saving CPU. One or both of those are generally why a cache is introduced. Now let’s cover the flip side…
Why Wouldn’t We Cache?
For everyone who hates caching, this is the section for you! Yes, I’m totally playing both sides.
Given the above and how drastic the wins are, why wouldn’t we cache something? Well, because every single decision has trade-offs. Every. Single. One. It could be as simple as time spent or opportunity cost, but there’s still a trade-off.
When it comes to caching, adding a cache comes with some costs:
- Purging values if and when needed (cache invalidation – we’ll cover that in a few)
- Memory used by the cache
- Latency of access to the cache (weighed against access to the source)
- Additional time and mental overhead spent debugging something more complicated
Whenever a candidate for caching comes up (usually with a new feature), we need to evaluate these things…and that’s not always an easy thing to do. Although caching is an exact science, much like astrology, it’s still tricky.
Here at Stack Overflow, our architecture has one overarching theme: keep it as simple as possible. Simple is easy to evaluate, reason about, debug, and change if needed. Only make it more complicated if and when it needs to be more complicated. That includes cache. Only cache if you need to. It adds more work and more chances for bugs, so unless it’s needed: don’t. At least, not yet.
Let’s start by asking some questions.
- Is it that much faster to hit cache?
- What are we saving?
- Is it worth the storage?
- Is it worth the cleanup of said storage (e.g. garbage collection)?
- Will it go on the large object heap immediately?
- How often do we have to invalidate it?
- How many hits per cache entry do we think we’ll get?
- Will it interact with other things that complicate invalidation?
- How many variants will there be?
- Do we have to allocate just to calculate the key?
- Is it a local or remote cache?
- Is it shared between users?
- Is it shared between sites?
- Does it rely on quantum entanglement or does debugging it just make you think that?
- What color is the cache?
All of these are questions that come up and affect caching decisions. I’ll try and cover them through this post.
Layers of Cache at Stack Overflow
We have our own “L1”/”L2” caches here at Stack Overflow, but I’ll refrain from referring to them that way to avoid confusion with the CPU caches mentioned above. What we have is several types of cache. Let’s first quickly cover local and memory caches here for terminology before a deep dive into the common bits used by them:
- “Global Cache”: In-memory cache (global, per web server, and backed by Redis on miss)
- Usually things like a user’s top bar counts, shared across the network
- This hits local memory (shared keyspace), and then Redis (shared keyspace, using Redis database 0)
- “Site Cache”: In-memory cache (per site, per web server, and backed by Redis on miss)
- Usually things like question lists or user lists that are per-site
- This hits local memory (per-site keyspace, using prefixing), and then Redis (per-site keyspace, using Redis databases)
- “Local Cache”: In-memory cache (per site, per web server, backed by nothing)
- Usually things that are cheap to fetch, but huge to stream and the Redis hop isn’t worth it
- This hits local memory only (per-site keyspace, using prefixing)
What do we mean by “per-site”? Stack Overflow and the Stack Exchange network of sites is a multi-tenant architecture. Stack Overflow is just one of many hundreds of sites. This means one process on the web server hosts all the sites, so we need to split up the caching where needed. And we’ll have to purge it (we’ll cover how that works too).
Redis
Before we discuss how servers and shared cache work, let’s quickly cover what the shared bits are built on: Redis. So what is Redis? It’s an open source key/value data store with many useful data structures, additional publish/subscriber mechanisms, and rock solid stability.
Why Redis and not <something else>? Well, because it works. And it works well. It seemed like a good idea when we needed a shared cache. It’s been incredibly rock solid. We don’t wait on it – it’s incredibly fast. We know how it works. We’re very familiar with it. We know how to monitor it. We know how to spell it. We maintain one of the most used open source libraries for it. We can tweak that library if we need.
It’s a piece of infrastructure we just don’t worry about. We basically take it for granted (though we still have an HA setup of replicas – we’re not completely crazy). When making infrastructure choices, you don’t just change things for perceived possible value. Changing takes effort, takes time, and involves risk. If what you have works well and does what you need, why invest that time and effort and take a risk? Well…you don’t. There are thousands of better things you can do with your time. Like debating which cache server is best!
We have a few Redis instances to separate concerns of apps (but on the same set of servers), here’s an example of what one looks like:

For the curious, some quick stats from last Tuesday (2019-07-30) This is across all instances on the primary boxes (because we split them up for organization, not performance…one instance could handle everything we do quite easily):
- Our Redis physical servers have 256GB of memory, but less than 96GB used.
- 1,586,553,473 commands processed per day (3,726,580,897 commands and 86,982 per second peak across all instances – due to replicas)
- Average of 2.01% CPU utilization (3.04% peak) for the entire server (< 1% even for the most active instance)
- 124,415,398 active keys (422,818,481 including replicas)
- Those numbers are across 308,065,226 HTTP hits (64,717,337 of which were question pages)
Note: None of these are Redis limited – we’re far from any limits. It’s just how much activity there is on our instances.
There are also non-cache reasons we use Redis, namely: we also use the pub/sub mechanism for our websockets that provide realtime updates on scores, rep, etc. Redis 5.0 added Streams which is a perfect fit for our websockets and we’ll likely migrate to them when some other infrastructure pieces are in place (mainly limited by Stack Overflow Enterprise’s version at the moment).
To read the rest of this post, head over to Nick's blog.
It is also #5 in a very long series of posts on Stack Overflow’s architecture. Previous post (#4): Stack Overflow: How We Do Monitoring - 2018 Edition