
As of September 23rd, 2019, we’re applying static analysis to some of the code behind public Stack Overflow, Stack Overflow for Teams, and Stack Overflow Enterprise in order to pre-emptively find and eliminate certain kinds of vulnerabilities. How we accomplished this is an interesting story and also illustrative of advancements in .NET’s open source community.
But first...
What did we have before static analysis?
The Stack Overflow codebase has been under continuous development for around a decade, starting all the way back on ASP.NET MVC Preview 2. As .NET has advanced, we’ve adopted tools that encourage safe practice like Razor (which defaults to encoding strings, helping protect against cross site scripting vulnerabilities). We’ve also created new tools that encourage doing things the Right Way™, like Dapper, which handles parameterizing SQL automatically while still being an incredibly performant (lite-)ORM.
An incomplete, but illustrative, list of default-safe patterns in our codebase:
- Automated SQL parameterization with Dapper
- Default encoding strings in views with Razor
- Requiring cross site request forgery (XSRF) tokens for non-idempotent (ie. POST, PUT, DELETE, etc.) routes by default
- HMACs with default expirations and common validation code
- Adopting TypeScript—an ongoing process—which increases our confidence around shipping correct JavaScript
- Private data—for Teams and Enterprise— is on separate infrastructure with separate access controls
We were safe, at least in theory, from most classes of injection and cross-site-scripting attacks.
So, ...
What did static analysis give us?
In large part, confidence that we were consistently following our pre-established best practices. Even though our engineers are talented and our tooling is easy to use, we’ve had dozens of people working on Stack Overflow for 10+ years—inevitably, some mistakes slipped into the codebase. Accordingly, most fixes were just moving to doing something “the right way” and pretty minor. Things like “use our route registration attribute instead of [HttpPost]” or “remove old uses of SHA1 and switch to SHA256.”
The more “exciting” fixes required introducing new patterns and updating old code to use them. While we had no evidence that any of these were exploited, or even exploitable in practice, we felt it was best to err on the side of caution and address them anyway. We added three new patterns as part of adopting static code analysis:
We replaced uses of System.Random with an equivalent interface backed by System.Security.Cryptography.RandomNumberGenerator. It is very hard to prove a random number being predictable either is or isn’t safe, so we standardized on always hard to predict.
We now default to forbidding HTTP redirects to domains we do not control, requiring all exceptions be explicitly documented. The concern here is open redirects, which can be used for phishing or other malicious purposes. Most of our redirects were already appropriately validating this, but the checks were scattered across the codebase. There were a few missing or buggy checks, but we found no evidence of them being exploited.
We strengthened XSRF checks to account for cases where users move between unauthenticated and authenticated states. Our XSRF checks previously assumed there was a single token tied to a user’s identity. Since this changes during authentication, some of our code suppressed this check and relied on other validation (completing an OAuth flow, for example). Even though all cases did have some kind of XSRF prevention, having any opt-outs of our default XSRF checking code is risky. So we decided to improve our checks to handle this case. Our fix was to allow two tokens to be acceptable, briefly, on certain routes.
Our checks run on every PR for Stack Overflow and, additionally (and explicitly), on every Enterprise build—meaning we aren’t just confident that we’re following our best practices today, we’re confident we will keep following them in the future.
In terms of Open Web Application Security Project (OWASP) lists, we gained automatic detection of:
- SQL injection attacks [2017 #1]
- XML external entity (XEE) attacks [2017 #4]
- Cross site scripting (XSS) attacks [2017 #7]
- Insecure deserialization [2017 #8]
- XSRF attacks [2013 #8]
- Open redirects [2013 #10]
That wraps up what we found and fixed, but…
How did we add static code analysis?
This is boring because all we did was write a config file and add a PackageReference to SecurityCodeScan.
That’s it. Visual Studio will pick it up as an analyzer (so you get squigglies) and the C# compiler will do the same so you get warnings or errors as desired.
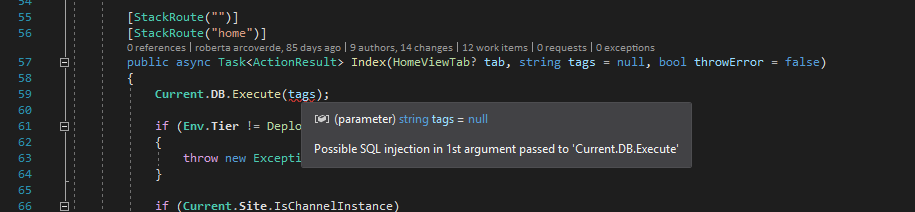
Far more interesting is all the open source stuff that made this possible:
- In 2014, Microsoft open sourced Roslyn, their C# and VB.NET compiler.
- Visual Studio 2015 ships with support of Roslyn analyzers.
- The authors of Security Code Scan start work in 2016.
- I contribute some minor changes to accommodate Stack Overflow peculiarities in 2019.
If you’d told me six years ago that we’d be able to add any sort of code analysis to the Stack Overflow solution trivially, for free, and in a way that contributes back to the greater developer community, I wouldn’t have believed you. It’s great to see “the new Microsoft” behavior benefit us so directly, but it’s even greater to see what the OSS community has built because of it.
We’ve only just shipped this, which begs the question...
What’s next with static code analysis?
Security is an ongoing process, not a bit you flip or a feature you add. Accordingly there will always be more to do and places we want to make improvements, and static code analysis is no different.
As I alluded to at the start, we’re only analyzing some of the code behind Stack Overflow. More precisely we’re not analyzing views or tracing through interprocedural calls—analyzing both is an obvious next step.
We’ll be able to start analyzing views once our migration to ASP.NET Core is complete. Pre-Core Razor view compilation doesn’t give us an easy way to add any analyzers, but that should be trivial once we’re upgraded. Razor's default behavior gives us some confidence around injection attacks, and views usually aren’t doing anything scary—but it will be nice to have stronger guarantees of correctness in the future.
Not tracing through interprocedural calls is a bit more complicated. Technically, this is a limitation of Security Code Scan, as there’s an issue for it. That we can’t analyze views reduces the value of interprocedural analysis today, as we almost always pass user-provided data into views. For now, we’re comfortable focusing on our controller action methods since basically all user-provided data passes through them before going onto views or other interprocedural calls.
The beauty of open source is that when we do come back and do these next steps (and any other quality of life changes), we’ll be making them available to the community so everyone benefits. It’s a wonderful thing to be able to benefit ourselves, our customers, and .NET developers everywhere—all at the same time.