
👋Hello! I’m Donna, the Community Design Lead at Stack Overflow.
Welcome to CHAPTER #1 of The Loop, a new blog series from the Stack Overflow Community team. This post is a deep-dive into our research approach: what it used to be, what it is now, and how it continues to evolve.
Learn more about The Loop in CHAPTER #0 (yes, our chapters are zero-based).
If you work on a product that’s ever benefited from research – whether that’s talking directly to users, analyzing experiment data, or any number of other research methods – you know how indispensable these inputs are for making the right decisions.
But how do you decide which methods to use and when? How do you know if you’re spending the right amount of time on research? How do you know when it’s time to change your research methods?
These are questions that the Community team has been grappling with, particularly in the last year. While we certainly don’t have all the answers, I’d like to share:
- What our research used to be
- What it is now
- How it continues to evolve
The early days
If you’ve been with us for a long time, you may remember when our research process looked something like this.
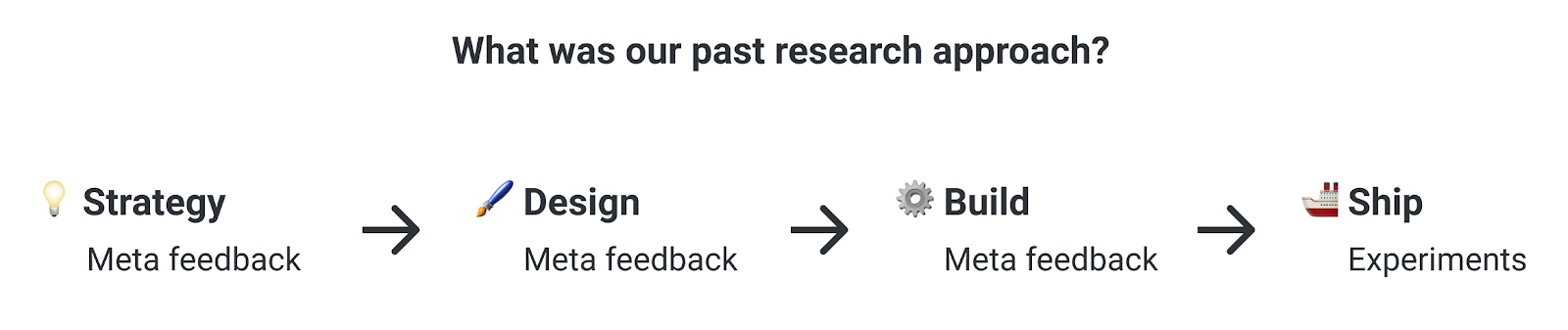
Meta feedback involved direct exchanges between users and staff members on Meta, a site where users discussed the site, shared ideas, gave feedback, and talked to staff. These conversations led to the Stack Overflow that many of us are familiar with, and we learned a lot while working with this small group of highly motivated users for many years.
Our current approach: scrappy and mixed-method
As our community has grown, our research needs have become more complex. With 50 million people coming to the site every month – all with unique needs and backgrounds – our team and its research approach have evolved to keep up with this ever-growing complexity. We’ve added folks to the team with specialized research skills, like UX researchers and data scientists, while people like product managers, designers, community managers, marketers, and developers contribute research as well.
Together, we conduct mixed-methods research that helps us create a holistic picture of how we’re doing. This collective research seeks to answer questions like:
- What do users need?
- What do customers need?
- Are our ideas and decisions on the right track?
- How are our products and features performing?
This mixed-method approach allows us to hear from a variety of inputs throughout the life cycle of a product or feature, from early conception to post-launch.
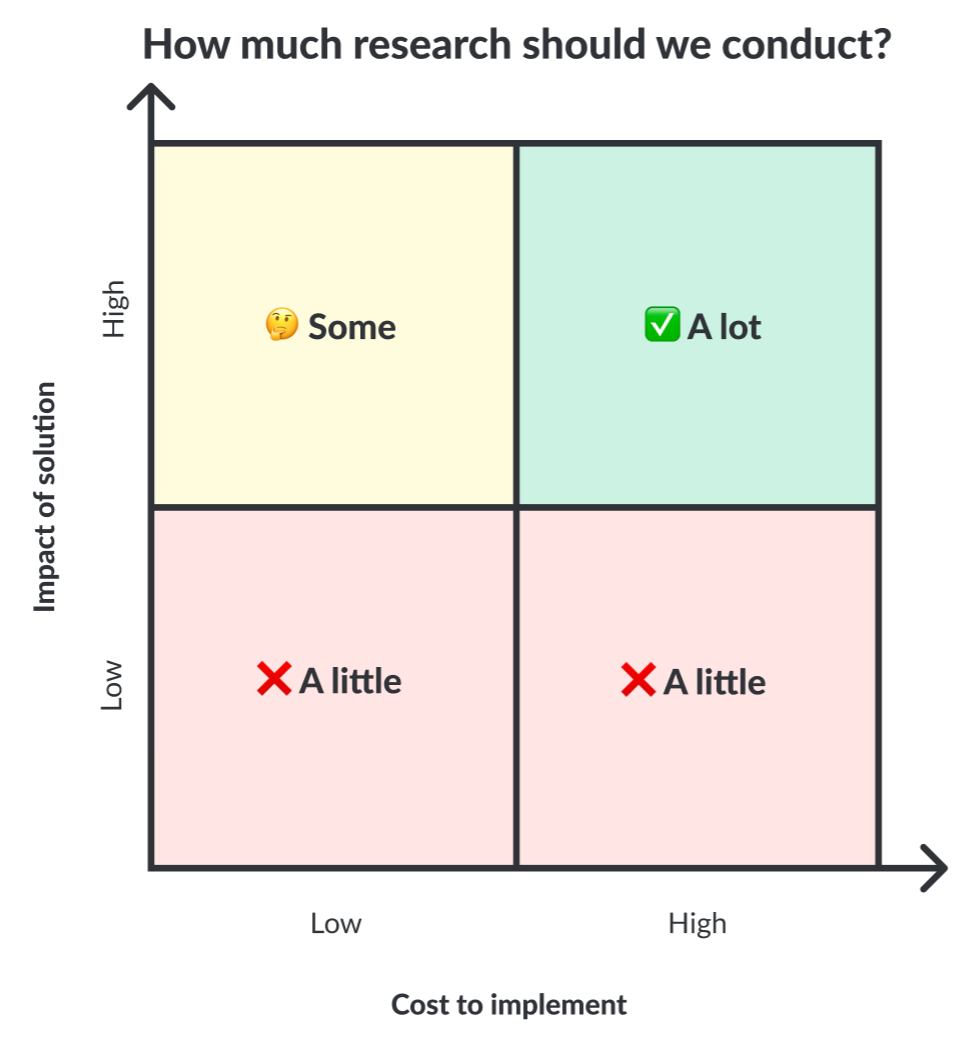
However, our small team can’t always conduct all of the research we’d like – which is where the “scrappy” element of our research approach comes in. Generally, the greater the cost and impact of a project, the more research energy we’ll devote to it. This matrix visualizes how we might decide the amount of research that goes into a project.
Today, our research process might look something like this for a high-impact, high-cost project.
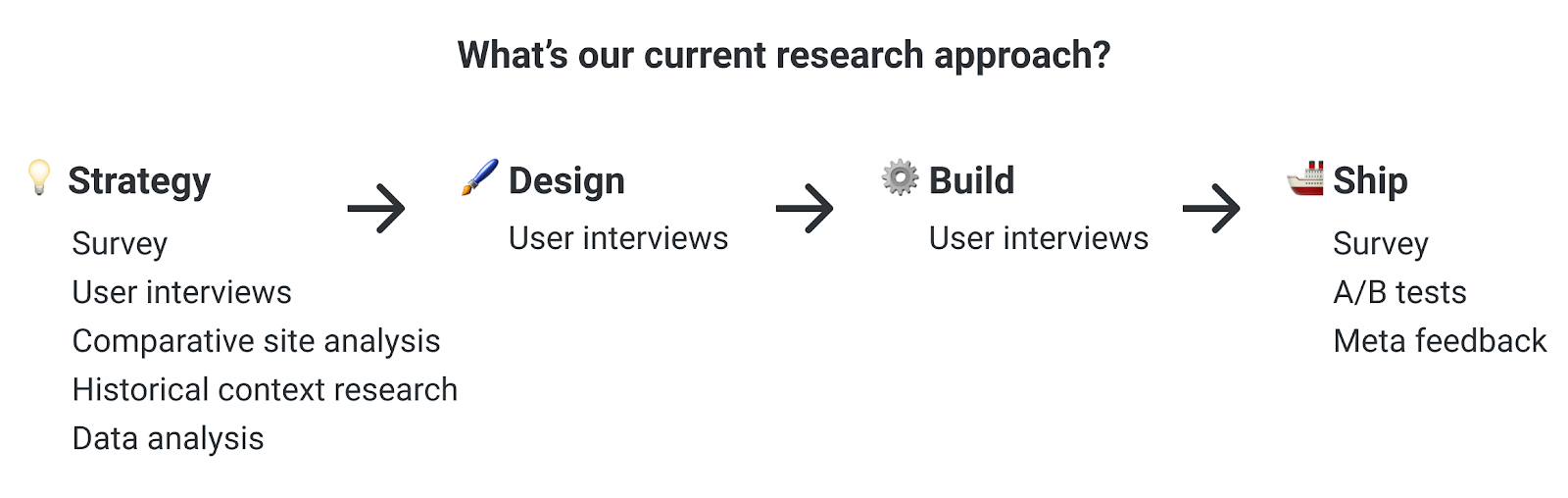
Think of each method as a puzzle piece, and the outcome as the completed puzzle. I’ll talk more in detail below about our methods and why we use them.
Method #1: surveys
Surveys are one of our favorite sources of both qualitative and quantitative feedback. We currently use surveys for:
- General site satisfaction. This is used to gauge trends in satisfaction and helps us identify directional improvements. We use this data to inform our roadmap.
- The beginning of a project. This helps us vet early ideas and point us in the right direction. We use survey data, as well as other inputs, to help us identify requirements and design.
- The end of a project. Once we ship, we can see how people are feeling about the new feature and identify changes for future iterations.
⚠️Why surveys? Surveys are a great way to get a high volume of qualitative feedback, which we can use to understand macro trends as well as micro issues for things like usability and copy. We can also target surveys to specific audiences, so that we are gathering data from people who’d be affected by the outcome of a particular project.
Method #2: user research
Qualitative research helps us understand the why and how of user behavior, allowing us to getdeeper insights than we might through other methods. Generally, these are semi-structured discussions that take place by video call or in writing – where we’ll talk in-depth with users about a specific topic, feature, or design. We generally conduct these throughout the beginning and middle phases of projects. We use a few different sub-methods, depending on the project:
- User interviews. We have conversations with people who may be affected by a given change. Since Stack Overflow is an online community where groups of people interact with each other, our conversations are not limited to the end user. For example, if we are updating the question asking form, not only do we talk to people asking questions, but also those answering and moderating questions.
- Meta feedback. We monitor Meta for bug reports and small usability/copy issues after shipping changes to the site. Note that this may change based on what the next iteration of Meta looks like, as mentioned in the previous chapter of The Loop.
⚠️Why user research? We get deeper insights than we might through other methods. Like surveys, we can target user research to specific audiences, and will talk to a range of groups affected by a given product change.
Method #3: quantitative data
While qualitative data helps us understand why, quantitative data helps us understand how many. We use data analysis and A/B tests to provide insight into how our decisions scale, as well as how changes we make contribute to site usage and overall performance goals. Sub-methods include:
- General data analysis. This is used to understand patterns in site usage across various user segments.
- A/B tests. We test as much as we can, particularly areas that impact core interactions on the site.
⚠️Why quantitative data? Statistical analysis allows us to see how (or if) earlier research insights scale and how the changes we make impact top-line performance goals.
Method #4: secondary research
Today’s Stack Overflow doesn’t exist in a vacuum. When we consider changes to the site, we want to understand the broader contexts of our users, as well as any historical insights that led us to the current state of the site. This helps ensure that we’re not reinventing the wheel or ignoring hard-learned lessons from the past. Sub-methods include:
- Comparative site analysis. We look at other sites to understand patterns and standards that users are learning offsite. This awareness helps us understand how to make a user’s entry into Stack Overflow as seamless as possible.
- Archive research. We scour Meta and talk to various staff, particularly community managers and developers, to learn how and why a feature arrived at its current state.
⚠️Why secondary research? We can learn from broader offsite patterns as well as research from previous iterations on the product.
Reflection
How we talk to and learn from our users has changed a lot over the years. By broadening our research approach, we’ve lost some of the trust and familiarity of regular, frequent exchanges with a small, passionate, and generous group of people on Meta. At the same time, we’ve brought more rigor and precision into our research approach, which means we have more confidence when making decisions.
Our research approach is constantly evolving. As Sara and Juan wrote in their latest blog post, we’re expanding our research toolbelt to include a working group (a hand-selected group of folks we’ll gather feedback from regularly). We want to continue not just listening to our users, but improving how we do so.
How does your organization conduct research? How has your organization’s research changed over time, and what have you learned from these changes?
✋Opt-in to our Research email list (must have a Stack Overflow account). You’ll receive invitations to participate in surveys, user interviews, and more. You’ll receive up to a few emails per year and can opt-out at any time.
📖Read CHAPTER #0 of The Loop, where Sara and Juan talk about our plans to improve how we listen to users.