If you put a textbox on the Internet, someone will put spam in it. If you put a textbox on a site that gets millions of hits a day, lots of someones will put lots of spam in it. If you put lots of textboxes on that site... you get the point.
Spam protection is like ogres—it has layers
Many large web applications are deployed in layers. When your browser sends a HTTP request to bigsite.example.com, it might hit a CDN first (like Cloudflare), then get forwarded to a proxy or load balancer, then to a single server, which might in its turn have a reverse proxy, then a web server, and only then does your request actually make it to the application itself. I won't go into exactly how Stack Exchange is deployed, because Nick Craver can explain it much better than I can.
Each of those layers can be tuned to help block spam. If you use Cloudflare, that'll do a lot of automatic spam protection for you without needing to think about it; there are a number of other CDNs that do likewise. A load balancer can have a simple IP blocking mechanism added to it. A reverse proxy can be configured to drop requests from suspicious origins—and that's all before you get to the application, where more sophisticated protection measures can be built in.
Stack Exchange makes use of a bunch of these layers to help alleviate the spam problem. Some of them are deliberately secretive, to avoid making it too easy to get around them; others are much more public knowledge. The bits I'm talking about here are the more public parts, which are generally in the lower layers of the request's path.
Unlucky spammers get HTTP errors
If one day I suddenly decide to take a new career path and try to make my fortune spamming Stack Exchange, I might start off by thinking that I'll just copy the HTTP request that happens when I post a new question, and write some code to repeat it really fast with spam in every post.
I would be an unlucky spammer, because I would very quickly hit the first level of spam protection: a 429. For those unfamiliar with HTTP status codes, 429 is Too Many Requests. The threshold here is deliberately not made public, but when Stack Exchange notices that you've been sending way too many requests to be humanly possible, it cuts you off and send you this charming message:
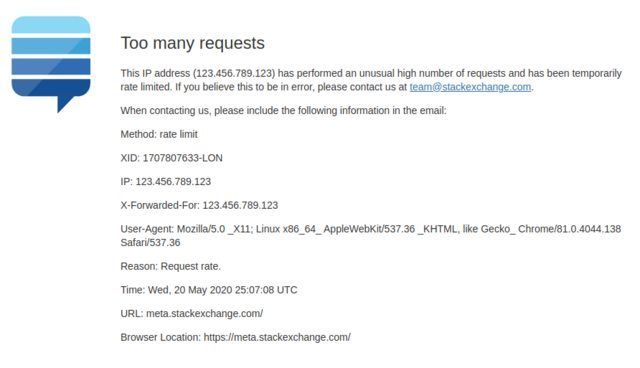
Now given that I've written some code to do this, the likelihood is that I'll never see that error page, and my script will just keep on... and on... and on. At some point, a Stack Exchange SRE might have a look while they're doing the rounds and decide I'm being a pest, and (figuratively) route any requests from my IP to /dev/null.
That I might notice.
"But aha," I hear you say, "you can just get a new IP!" Which I could, until I got that banned too.
"But aha, you can just use Tor!" Which sounds like a good idea on the face of it, until you realise that the list of Tor exit nodes is public and that's not changing any time soon. In other words, Stack Exchange can tell when you're using Tor, and if you're being a pest, can simply... turn Tor access off.
Lucky spammers get IP-blocked anyway
Once a HTTP request makes it to the Stack Exchange application, there's another roadblock in front of any potential spammers: SpamRam.
SpamRam is Stack Exchange's custom-built spam-prevention system. It monitors all incoming new posts, squints at them suspiciously to decide whether they're spam, and knocks them for six if they are. It's... really good at it:
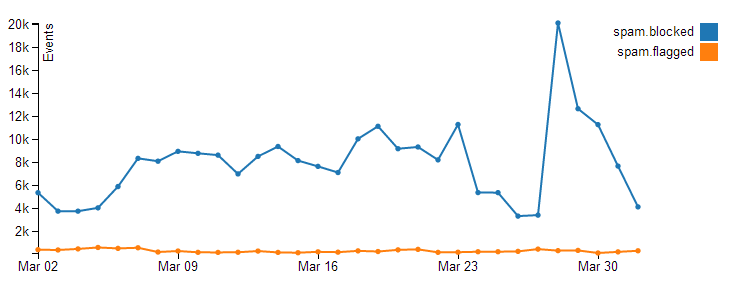
Admittedly that's an old graph, but it's indicative of how good SpamRam is at getting rid of the crap before it even hits the sites.
Part of why it's so good is that once it's identified spam, it feeds directly into IP blocking mechanisms. If a post gets blocked as potential spam, the IP address it came from can be blocked completely, hobbled (i.e. severely rate-limited), or prevented from posting—that's the source of the "You can't post due to the volume of spam/abuse originating from your network" message, complaints about which pop up on meta every now and then.
So what about that orange line? That's the stuff that gets through—that's the spam that users actually see. These posts get flagged as spam by users, which also feeds back into SpamRam and helps, again, to inform IP blocks. Actions that moderators take can help fuel the system—moderators can flag spam too, of course, but they can also destroy users and specifically state that they're doing so because the user is a spammer, which is a strong signal to SpamRam that the IP address it came from is bad news.
So how do folks find these posts to flag? That's where this last bit comes in.
Really lucky spammers get spam-flagged to death
If you're a crafty, sneaky, very lucky spammer, you might get some spam through and have it successfully land on a site without being blocked. Congratulations! Now you hit the last line of defence—the community's defence mechanisms.
I mentioned spam flagging—anyone with over 15 reputation can do that. If you see a spam post while browsing around the sites, you can spam-flag it. Six of these spam flags will automatically delete the post, mark it as spam (including hiding the contents), and feed it and its author to SpamRam.
That relies on folks seeing spam while casually browsing. For the most part, that works pretty well, especially on the higher-traffic sites, but particularly on smaller sites, spam can linger for a while before it collects enough flags. Fortunately, this is a problem that some folks in the community recognised a long time ago, and started a project aimed at solving it. Enter:

Charcoal is the organisation that runs SmokeDetector, which, fundamentally, is a bot that looks for spam and feeds it into chatrooms where waiting users can follow the link and spam-flag it.
Technically, it does this by listening to a Stack Exchange websocket and requesting the same action that's used to feed the realtime page. This gets us every new and edited question or answer, everywhere on the network. Each of these posts gets scanned, which involves running its content through an unholy amount of regular expressions and some heuristic tests, and seeing if any come back true. The vast majority, of course, aren't spam, but there's a significant volume that are—and those get posted to chat to be flagged into ignominy.
Doing things this way means we catch a lot of posts that aren't spam too (false positives). That's okay—because there's a human reviewing each post before flagging it, we're not aiming for a 0% false positive rate, but a 0% false negative rate—in other words, we're trying not to miss any spam, even if that means occasionally mistakenly identifying a good post as spam.
Sometimes, though, humans aren't enough. No matter how quickly spam can get flagged and deleted, there's always more. It often comes in waves, and the volume of spam coming in at the peak of a wave can easily overwhelm human flaggers and take some time to catch up on and get everything deleted. That said—there's a theme here—there's a solution for that too.
Arm the robot and set it loose
When the flagging gets tough, the tough... hand over the reins to the computers and let them do the work.
When Smokey decides that a post is spam, it sends it over to our web dashboard, metasmoke. Metasmoke is one of those applications that was originally really simple—just keep a record of the posts—but over time it's grown, and now it handles a whole lot of stuff. Stuff like:
- Keep a record of the posts
- Record any feedback that posts get—true positive, false positive, not an answer, etc.
- Run review queues to get feedback on posts that nobody's looked at yet
- Record and classify websites that have been used in spam
- Coordinate multiple SmokeDetector instances and manage failover
- Display all the pretty graphs
- Host an API for other things (like userscripts) to integrate with it
- Perhaps most importantly, run autoflagging.
In November-December 2016, we built a system into metasmoke that identifies the posts most likely to be spam as they come in. We tested it for a while on dry-run (not casting any flags), then we tested again, casting flags using one lucky victim volunteer's account. It exceeded our expectations—the accuracy was through the roof, and it was catching almost all of the blatantly obvious spam. In February, we launched the system publicly and included an appeal for flaggers to lend us their flags, that is, to sign up with metasmoke so that the system can flag posts in their name. Not long after that, we moved the system from casting a single automatic flag on each post, to casting three automatic flags on each post. We saw an almost instant reduction in time to deletion in both cases:
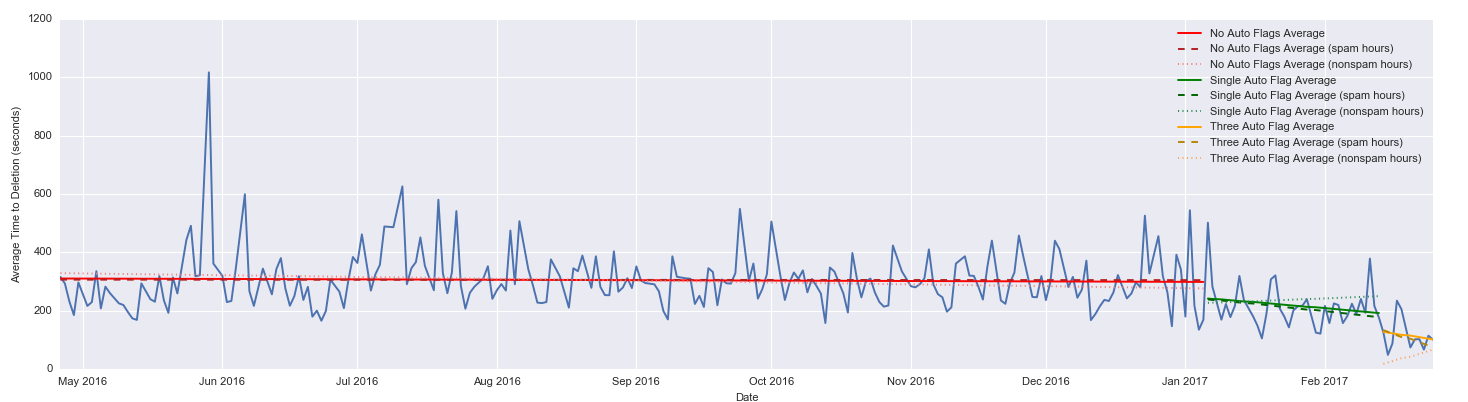
In the time since then, we've continued to make improvements to the system, ultimately resulting in moving up again to four flags on the posts that the system is most confident are spam. We've also started casting one autoflag on every post from the SmokeDetector account to help moderators identify posts that were affected by this system, which has the handy side effect of letting us monitor accuracy from SmokeDetector's flag history. Spoiler alert: it's stupidly accurate.
Charcoal and SmokeDetector are, effectively, the last line of defence against spam on Stack Exchange. With all these systems in combination, Stack Exchange does a ridiculously good job of protecting itself against spam.
So what's next?
For Stack Exchange? Who knows—there are always improvements that can be made to spam detection systems. For Charcoal? We'll carry on tweaking the system and updating our detection rules, always looking for more spam to delete.
If you're interested in finding out more about Charcoal, you can have a look around the website, our GitHub organisation, or you can drop into chat with us. We're always looking for new faces to help out—whether you're just mildly interested or you think you could work on the next big feature, we'd love to have you.