This post offers a technical perspective on how Articles - our brand new content type - came to life. We’ll explore some of the challenges, trade-offs, and implementation details of this exciting new feature. But first, let’s take a look at articles from a product perspective, briefly describing its features and what they look like.
Articles allows for the creation and sharing of long-form content within Teams. While we believe that questions and answers are still the best mechanism when soliciting “in the moment” knowledge, Articles allow users to share information with fellow team members proactively and in much greater detail. Sometimes, the narrative of how and why decisions were made adds another layer of understanding to the creation and maintenance of software. And having your longer form content in the same place as your Q&A means less context switching.
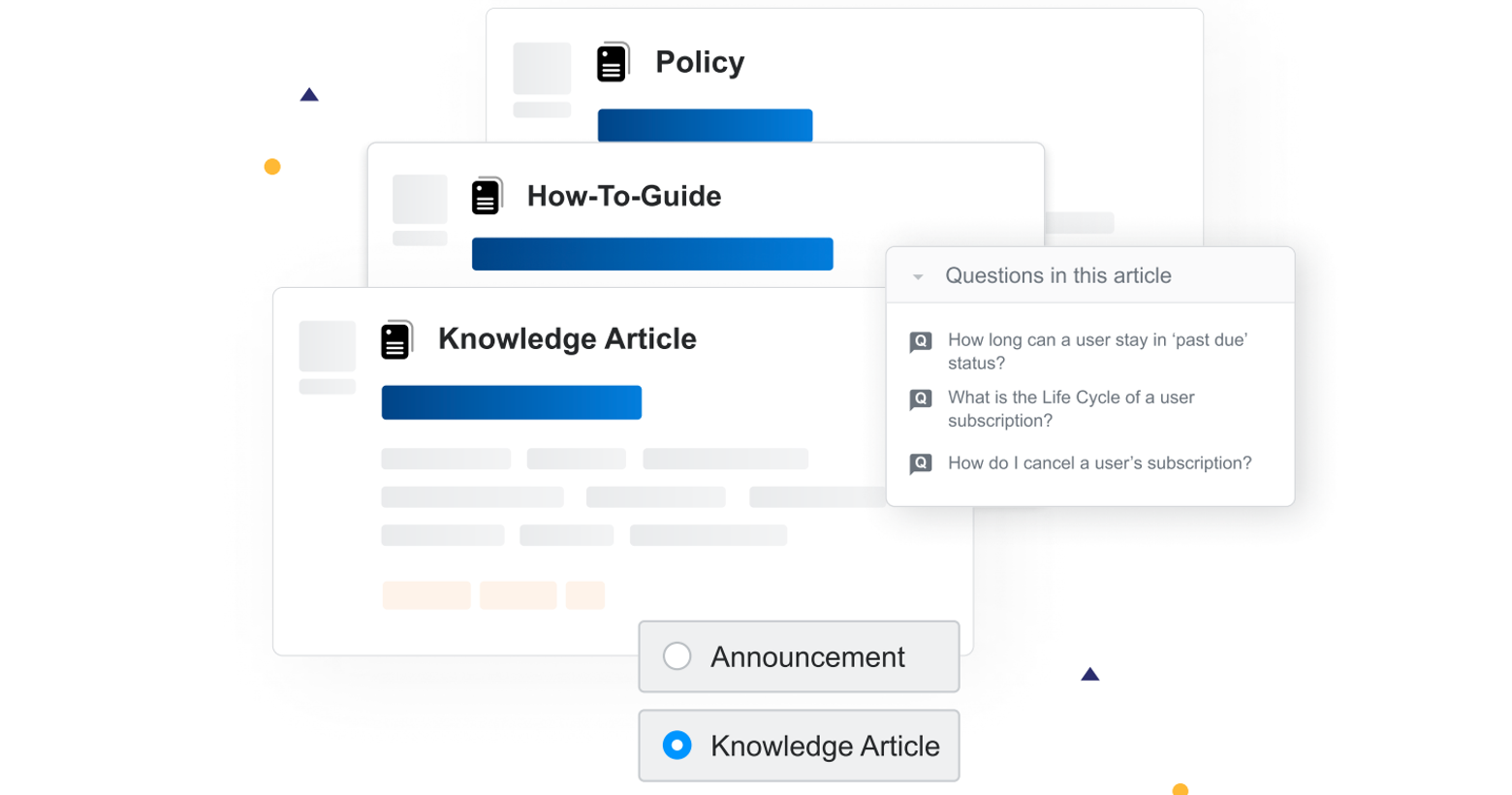
Articles and Q&A share a lot of functionalities: they have tags, comments, voting scores, and are included in your Team search results. Additionally, Articles have a piece of information that we call “types”. When creating a new article, users can give it a specific type that best suits the kind of content included in that article. We highlight article types in the different contexts where articles may appear: search results, collections, or the list of articles itself. In the future, we may also use article types for enabling different behaviors and functionalities. For example, we could allow users to create custom templates for certain article types or add special notifications when articles of a particular type are created. Currently, we support the following choices for article types:
- Knowledge Article
- Announcement
- How-To Guide
- Policy

Implementation
Articles data model
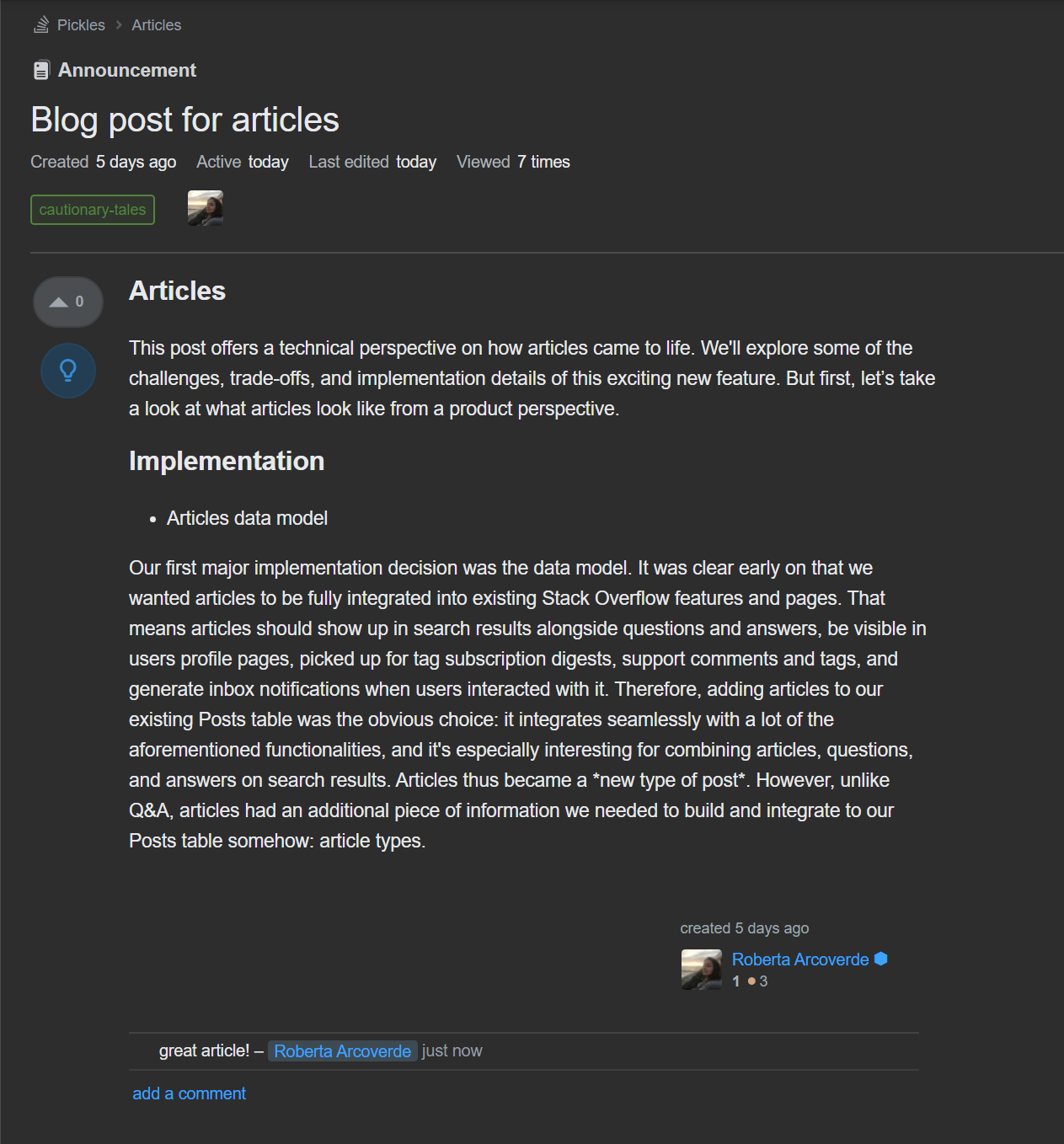
Our first major implementation decision was the data model. Where are articles going to be stored and how are we modeling their relationships with other system entities? It was clear early on that we wanted articles to fully integrate into existing Stack Overflow for Teams features and pages. That means articles should show up in search results alongside questions and answers, be visible in users profile pages, get picked up in tag subscription digests, support comments and tags, appear in our external integrations, and generate inbox notifications. Whew! Currently, all questions, answers, and wikis are stored in a single table called Posts (if you’re interested, you can check out our database schema and even run custom queries on https://data.stackexchange.com/).
Adding articles to the existing Posts table was thus the obvious choice. This decision is particularly beneficial when you want to combine articles, questions, and answers on search results; since they’re all Posts, the logic is quite simplified. Articles thus became a *new type of post* rather than a unique entity of their own.
However, unlike Q&A, articles had an additional piece of information we needed to build and integrate into our data model somehow: article types.
Article types: special kind of tags
Our main challenge for building this feature was deciding where article types should be stored. We considered different approaches, like creating a new table and even leveraging our brand-new Collections feature for modeling types as new, pre-seeded collections. In the end, however, we settled on a simpler solution that would require less code intervention and work as-is with our existing Elasticsearch posts index: articles types as tags.
Sounds simple, right? Well, not just regular content tags, but *special* tags: because we needed to be able to tell, from a list of tags, which one was the article type. We also needed to make them required when creating articles and protect them from deletion. Our solution involved adding a new column to the Tags table for indicating they are an “article required tag” and creating the new article tags on-demand when articles are enabled on a given Team.
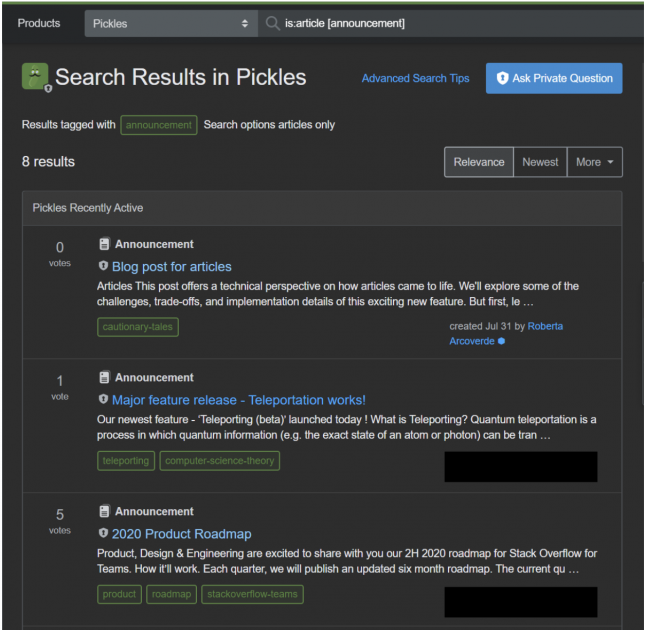
The interesting bit here is that article types are only special when rendering an article: they are treated like regular content tags both in our posts search index and when denormalized in the Posts table. Therefore, searching for all articles of a given article type is as simple as running a custom tag search. We also added support for the is:article operator, which filters search results coming from our Elasticsearch index to articles-only. If a user wanted to search for all policies of a Team, for example, they would use the query is:article [policy]
Another big advantage of adding articles as posts and types as tags is that we didn't have to add any new fields to our post’s search index. The code that runs the public Stack Overflow service and sites is largely the same as the code that runs our private Teams. Therefore, whenever we make changes to the structure of indexed documents, we need to rebuild our indexes across all sites and Teams - a process which may take a significant amount of time and risk downtime for search. We all know how the developers react when the public Stack Overflow website is down, and we want to avoid any outages with our paying customers as well. Last but not least, adding a special field just for article types would be wasteful and confusing on sites that don't have Articles enabled.
Voting and feedback
Just as we allow users the ability to vote on questions and answers, we felt users should have a way to provide feedback to article authors - both praise and suggested improvements. In addition to upvotes, users can give contextualized and private feedback to the authors and editors of an article via a feature we call suggestions.
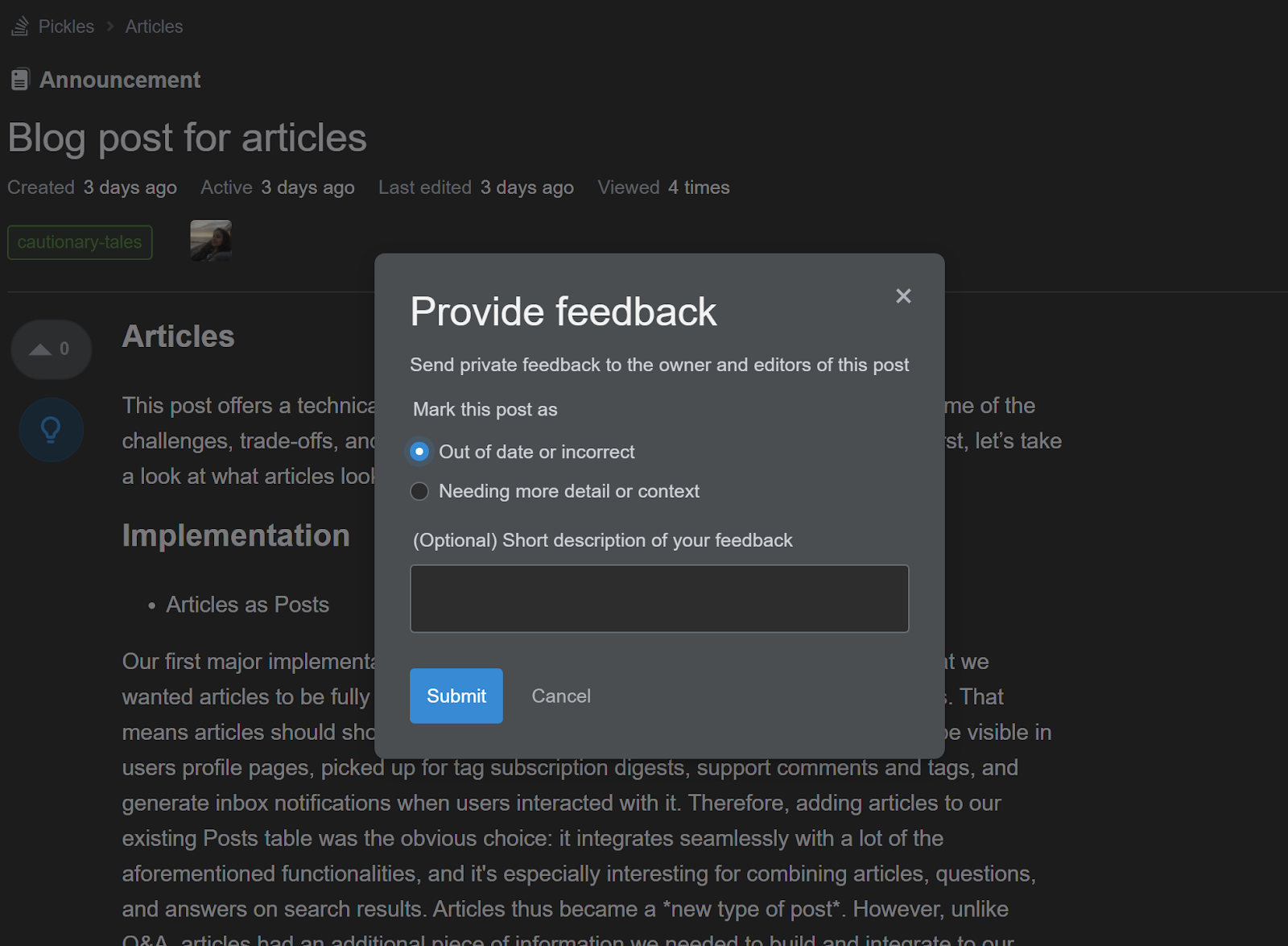
We built suggestions on top of our comments data model. Suggestions are very similar to regular post comments except that they 1) are private and 2) can have one of two types: ”article needs more details” or “is outdated”. We rewrote part of our post comments code to reflect those requirements and added new functionality so article authors could “resolve” suggestions.
We spent a decent amount of time considering different design approaches - should suggestions have their own table? Should we add them as custom flags? Adding support for private comments seemed to be a good idea, but how can we make that change in a way that makes sense across the codebase and can be reused for other things in the future? These considerations were key for reaching our final design - adding the concept of types to regular post comments, creating two comment types for the two different kinds of suggestions, and filtering those out of all SELECT queries touching the post comments table. It looks simple in hindsight, but this change alone saved us a lot of time testing, measuring and writing code that would have been necessary had we decided to create a brand new suggestions table.
Final thoughts: simplicity is key
When I started writing this article (see what I did there?), I admit I was a bit afraid of not having many intricate, complicated things to explain. But the beauty of designing this new feature was in its simplicity. We spent a lot of time considering different possibilities, thinking about the right architecture, and making sure it was thorough, reusable, and easy to plug into all of our subsystems. Articles had to be a special content type within our existing infrastructure, not a custom foreign entity. Taking the time to carefully think that design choice through also meant less time spent building, testing, measuring, and debugging.
We started thinking about Articles from a technical perspective back in March 2020. We knew from the beginning that we wanted to keep things simple so we could iterate and incorporate feedback progressively. We could have easily fallen into the scope creep or over-engineering traps had we not taken the time to design these features with simplicity and reusability in mind.
We applied the same principles of careful thinking for designing the product itself. We knew the most important thing would be to get articles out there as soon as possible, and observe how it was being used before adding tons of new features. With that in mind, we have been dogfooding articles internally for a few weeks now, which has been a lot of fun. Many teams have migrated procedures, guides and policies from wikis and external documents into articles already, and having a single place to search and find relevant content has been a huge win and true time saver for us. Most importantly, it validated our decision to start with a simple, well rounded feature, built in a way that was easy to maintain, extend, and evolve.
PS: there's another major win that I deliberately didn't mention here because it deserves its own blog post: articles are launching with a brand new, revamped editor. Moving all posts to CommonMark was a big part of developing this new editor, and you can learn more about it on this amazing meta post from our developer Ham. Stay tuned for more updates on the new editor and the challenges and decisions we faced while building it.