
Data scientists excel at creating models that represent and predict real-world data, but effectively deploying machine learning models is more of an art than science. Deployment requires skills more commonly found in software engineering and DevOps. Venturebeat reports that 87% of data science projects never make it to production, while redapt claims it is 90%. Both highlight that a critical factor which makes the difference between success and failure is the ability to collaborate and iterate as a team.
The goal of building a machine learning model is to solve a problem, and a machine learning model can only do so when it is in production and actively in use by consumers. As such, model deployment is as important as model building. As Redapt points out, there can be a “disconnect between IT and data science. IT tends to stay focused on making things available and stable. They want uptime at all costs. Data scientists, on the other hand, are focused on iteration and experimentation. They want to break things.” Bridging the gap between those two worlds is key to ensuring you have a good model and can actually put it into production.
Most data scientists feel that model deployment is a software engineering task and should be handled by software engineers because the required skills are more closely aligned with their day-to-day work. While this is somewhat true, data scientists who learn these skills will have an advantage, especially in lean organizations. Tools like TFX, Mlflow, Kubeflow can simplify the whole process of model deployment, and data scientists can (and should) quickly learn and use them.
The difficulties in model deployment and management have given rise to a new, specialized role: the machine learning engineer. Machine learning engineers are closer to software engineers than typical data scientists, and as such, they are the ideal candidate to put models into production. But not every company has the luxury of hiring specialized engineers just to deploy models. For today’s lean engineering shop, it is advisable that data scientists learn how to get their models into production.
In all this, another question looms — what is the most effective way to put machine learning models into production?
This question is critical, because machine learning promises lots of potential for businesses, and any company that can quickly and effectively get their models to production can outshine their competitors.
In this article, I’m going to talk about some of the practices and methods that will help get machine learning models in production. I’ll discuss different techniques and use cases, as well as the pros and cons of each method.
So without wasting any more time, let’s get to it!
From model to production
Many teams embark on machine learning projects without a production plan, an approach that often leads to serious problems when it's time to deploy. It is both expensive and time-consuming to create models, and you should not invest in an ML project if you have no plan to put it in production, except of course when doing pure research. With a plan in hand, you won’t be surprised by any pitfalls that could derail your launch.
There are three key areas your team needs to consider before embarking on any ML projects are:
- Data storage and retrieval
- Frameworks and tooling
- Feedback and iteration
Data storage and retrieval
A machine learning model is of no use to anyone if it doesn’t have any data associated with it. You’ll likely have training, evaluation, testing, and even prediction data sets. You need to answer questions like:
- How is your training data stored?
- How large is your data?
- How will you retrieve the data for training?
- How will you retrieve data for prediction?
These questions are important as they will guide you on what frameworks or tools to use, how to approach your problem, and how to design your ML model. Before you do anything else in a machine learning project, think about these data questions.
Data can be stored in on-premise, in cloud storage, or in a hybrid of the two. It makes sense to store your data where the model training will occur and the results will be served: on-premise model training and serving will be best suited for on-premise data especially if the data is large, while data stored in cloud storage systems like GCS, AWS S3, or Azure storage should be matched with cloud ML training and serving.
The size of your data also matters a lot. If your dataset is large, then you need more computing power for preprocessing steps as well as model optimization phases. This means you either have to plan for more compute if you’re operating locally, or set up auto-scaling in a cloud environment from the start. Remember, either of these can get expensive if you haven’t thought through your data needs, so pre-plan to make sure your budget can support the model through both training and production
Even if you have your training data stored together with the model to be trained, you still need to consider how that data will be retrieved and processed. Here the question of batch vs. real-time data retrieval comes to mind, and this has to be considered before designing the ML system. Batch data retrieval means that data is retrieved in chunks from a storage system while real-time data retrieval means that data is retrieved as soon as it is available.
Along with training data retrieval, you will also need to think about prediction data retrieval. Your prediction data is rarely as neatly packaged as the training data, so you need to consider a few more issues related to how your model will receive data at inference time:
- Are you getting inference data from webpages?
- Are you receiving prediction requests from APIs?
- Are you making batch or real-time predictions?
and so on.
If you’re getting data from webpages, the question then is what type of data? Data from users in webpages could be structured data (CSVs, JSON) or unstructured data (images, videos, sound), and the inference engine should be robust enough to retrieve, process, and to make predictions. Inference data from web pages may be very sensitive to users, and as such, you must take into consideration things like privacy and ethics. Here, frameworks like Federated Learning, where the model is brought to the data and the data never leaves webpages/users, can be considered.
Another issue here has to do with data quality. Data used for inference will often be very different from training data, especially when it is coming directly from end-users not APIs. Therefore you must provide the necessary infrastructure to fully automate the detection of changes as well as the processing of this new data.
As with retrieval, you need to consider whether inference is done in batches or in real-time. These two scenarios require different approaches, as the technology/skill involved may be different. For batch inference, you might want to save a prediction request to a central store and then make inferences after a designated period, while in real-time, prediction is performed as soon as the inference request is made.Knowing this will enable you to effectively plan when and how to schedule compute resources, as well as what tools to use.
Raising and answering questions relating to data storage and retrieval is important and will get you thinking about the right way to design your ML project.
Frameworks and tooling
Your model isn’t going to train, run, and deploy itself. For that, you need frameworks and tooling, software and hardware that help you effectively deploy ML models. These can be frameworks like Tensorflow, Pytorch, and Scikit-Learn for training models, programming languages like Python, Java, and Go, and even cloud environments like AWS, GCP, and Azure.
After examining and preparing your use of data, the next line of thinking should consider what combination of frameworks and tools to use.
The choice of framework is very important, as it can decide the continuity, maintenance, and use of a model. In this step, you must answer the following questions:
- What is the best tool for the task at hand?
- Are the choice of tools open-source or closed?
- How many platforms/targets support the tool?
To help determine the best tool for the task, you should research and compare findings for different tools that perform the same job. For instance, you can compare these tools based on criteria like:
Efficiency: How efficient is the framework or tool in production? A framework or tool is efficient if it optimally uses resources like memory, CPU, or time. It is important to consider the efficiency of Frameworks or tools you intend to use because they have a direct effect on project performance, reliability, and stability.
Popularity: How popular is the tool in the developer community? Popularity often means it works well, is actively in use, and has a lot of support. It is also worth mentioning that there may be newer tools that are less popular but more efficient than popular ones, especially for closed-source, proprietary tools. You’ll need to weigh that when picking a proprietary tool to use. Generally, in open source projects, you’d lean to popular and more mature tools for reasons I’ll discuss below.
Support: How is support for the framework or tool? Does it have a vibrant community behind it if it is open-sourced, or does it have good support for closed-source tools?How fast can you find tips, tricks, tutorials, and other use cases in actual projects?
Next, you also need to know whether the tools or framework you have selected is open-source or not. There are pros and cons to this, and the answer will depend on things like budget, support, continuity, community, and so on. Sometimes, you can get a proprietary build of open-source software, which means you get the benefits of open source plus premium support.
One more question you need to answer is how many platforms/targets does your choice of framework support? That is, does your choice of framework support popular platforms like the web or mobile environments? Does it run on Windows, Linux, or Mac OS? Is it easy to customize or implement in this target environment? These questions are important as there can be many tools available to research and experiment on a project, but few tools that adequately support your model while in production.
Feedback and iteration
ML projects are never static. This is part of engineering and design that must be considered from the start. Here you should answer questions like:
- How do we get feedback from a model in production?
- How do you set up continuous delivery?
Getting feedback from a model in production is very important. Actively tracking and monitoring model state can warn you in cases of model performance depreciation/decay, bias creep, or even data skew and drift. This will ensure that such problems are quickly addressed before the end-user notices.
Consider how to experiment on, retrain, and deploy new models in production without bringing that model down or otherwise interrupting its operation. A new model should be properly tested before it is used to replace the old one. This idea of continuous testing and deploying new models without interrupting the existing model processes is called continuous integration.
There are many other issues when getting a model into production, and this article is not law, but I’m confident that most of the questions you’ll ask falls under one of the categories stated above.
An example of machine learning deployment
Now, I’m going to walk you through a sample ML project. In this project,you’re an ML engineer working on a promising project, and you want to design a fail-proof system that can effectively put, monitor, track, and deploy an ML model.
Consider Adstocrat, an advertising agency that provides online companies with efficient ad tracking and monitoring. They have worked with big companies and have recently gotten a contract to build a machine learning system to predict if customers will click on an ad shown on a webpage or not. The contractors have a large volume dataset in a Google Cloud Storage (GCS) bucket and want Adstocrat to develop an end-to-end ML system for them.
As the engineer in charge, you have to come up with a design solution before the project kicks off. To approach this problem, ask each of the questions asked earlier and develop a design for this end-to-end system.
Data concerns
First, let’s talk about the data. How is your training data stored?
The data is stored in a GCS bucket and comes in two forms. The first is a CSV file describing the ad, and the second is the corresponding image of the ad. The data is already in the cloud, so it may be better to build your ML system in the cloud. You’ll get better latency for I/O, easy scaling as data becomes larger (hundreds of gigabytes), and quick setup and configuration for any additional GPUs and TPUs.
How large is your data?
The contractor serves millions of ads every month, and the data is aggregated and stored in the cloud bucket at the end of every month. So now you know your data is large (hundreds of gigabytes of images), so your hunch of building your system in the cloud is stronger.
How will you retrieve the data for training?
Since data is stored in the GCS bucket, it can be easily retrieved and consumed by models built on the Google Cloud Platform. So now you have an idea of which cloud provider to use.
How will you retrieve data for prediction?
In terms of inference data, the contractors informed you that inference will be requested by their internal API, as such data for prediction will be called by a REST API. This gives you an idea of the target platform for the project.
Frameworks and tools for the project
There are many combinations of tools you can use at this stage, and the choice of one tool may affect the others. In terms of programming languages for prototyping, model building, and deployment, you can decide to choose the same language for these three stages or use different ones according to your research findings. For instance, Java is a very efficient language for backend programming, but cannot be compared to a versatile language like Python when it comes to machine learning.
After consideration, you decide to use Python as your programming language, Tensorflow for model building because you will be working with a large dataset that includes images, and Tensorflow Extended (TFX), an open-source tool released and used internally at Google, for building your pipelines. What about the other aspects of the model building like model analysis, monitoring, serving, and so on? What tools do you use here? Well, TFX pretty much covers it all!
TFX provides a bunch of frameworks, libraries, and components for defining, launching, and monitoring machine learning models in production. The components available in TFX let you build efficient ML pipelines specifically designed to scale from the start. These components has built-in support for ML modeling, training, serving, and even managing deployments to different targets.
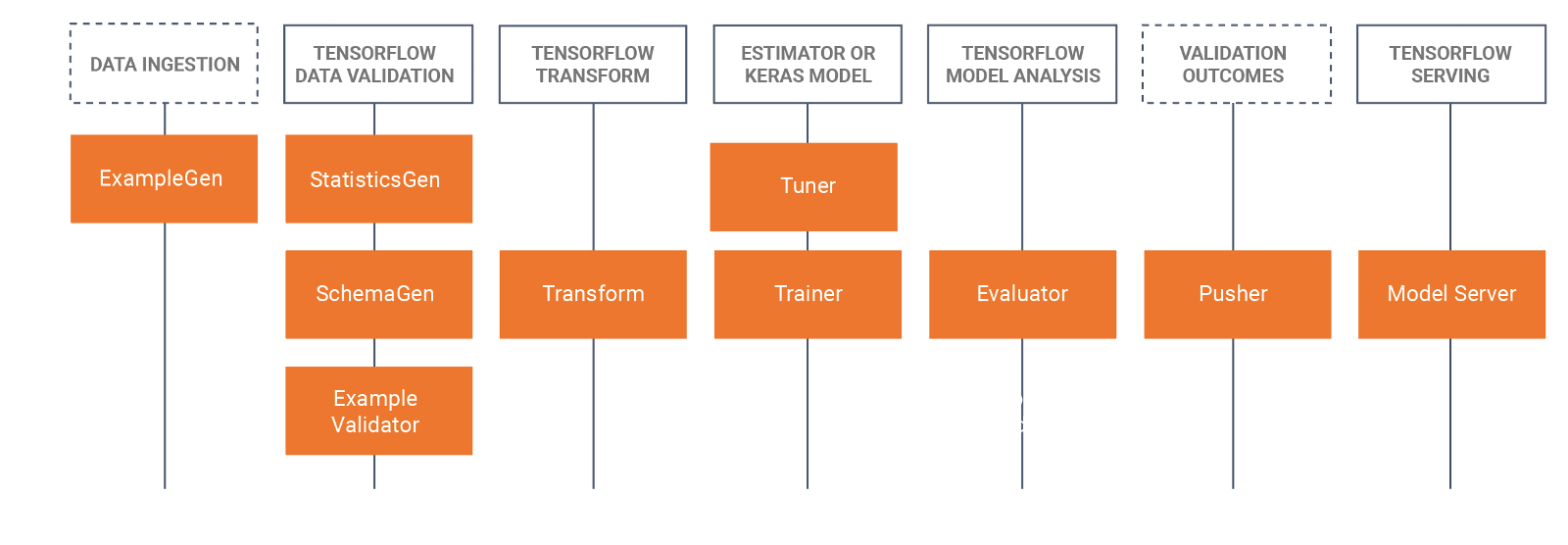
TFX is also compatible with our choice of programming language (Python), as well as your choice of deep learning model builder (Tensorflow), and this will encourage consistency across your team. Also, since TFX and Tensorflow were built by Google, it has first-class support in the Google Cloud Platform. And remember, your data is stored in GCS.
If you want the technical details on how to build a complete end-to-end pipeline with TFX, see the links below:
TensorFlow Extended (TFX) | ML Production Pipelines
Build and manage end-to-end production ML pipelines. TFX components enable scalable, high-performance data processing…www.tensorflow.org
Creating Sounds Of India: An on device, AI powered, musical experience built with TensorFlow August 14, 2020 - Posted…blog.tensorflow.org
Are the choice of tools open-source or closed?
Python and TFX and Tensorflow are all open-source, and they are the major tools for building your system. In terms of computing power and storage, you are using all GCP which is a paid and managed cloud service. This has its pros and cons and may depend on your use case as well. Some of the pros to consider when considering using managed cloud services are:
- They are cost-efficient
- Quick setup and deployment
- Efficient backup and recovery
Some of the cons are:
- Security issue, especially for sensitive data
- Internet connectivity may affect work since everything runs online
- Recurring costs
- Limited control over tools
In general, for smaller businesses like startups, it is usually cheaper and better to use managed cloud services for your projects.
How many platforms/targets support the tool?
TFX and Tensorflow run anywhere Python runs, and that’s a lot of places. Also, models built with Tensorflow can easily be saved and served in the browsers using Tensorflow.js, in mobile devices and IoT using Tensorflow lite, in the cloud, and even on-prem.
Feedback and Iteration concerns
How do we get feedback from a model in production?
TFX supports a feedback mechanism that can be easily used to manage model versioning as well as rolling out new models. Custom feedback can be built around this tool to effectively track models in production. A TFX Component calledTensorFlow Model Analysis (TFMA)allows you to easily evaluate new models against current ones before deployment.
Looking back at the answers above, you can already begin to picture what your final ML system design will look like. And getting this part before model building or data exploration is very important.
Conclusion
Effectively putting an ML model in production does not have to be hard if all the boxes are ticked before embarking on a project. This is very important in an ML project you’ll embark on and should be prioritized!
While this post is not exhaustive, I hope it has provided you with a guide and intuition on how to approach an ML project to put it in production.
Thanks for reading! See you again another time.