
We tend to rely on caching solutions to improve database performance. Caching frequently-accessed queries in memory or via a database can optimize write/read performance and reduce network latency, especially for heavy-workload applications, such as gaming services and Q&A portals. But you can further improve performance by pooling users' connections to a database.
Client users need to create a connection to a web service before they can perform CRUD operations. Most web services are backed by relational database servers such as Postgres or MySQL. With PostgreSQL, each new connection can take up to 1.3MB in memory. In a production environment where we expect to receive thousands or millions of concurrent connections to the backend service, this can quickly exceed your memory resources (or if you have a scalable cloud, it can get very expensive very quickly).
Because each time a client attempts to access a backend service, it requires OS resources to create, maintain, and close connections to the datastore. This creates a large amount of overhead causing database performance to deteriorate.
Consumers of your service expect fast response times. If that performance deteriorates, it can lead to poor user experiences, revenue losses, and even unscheduled downtime. If you expose your backend service as an API, repeated slowdowns and failures could cause cascading problems and lose you customers.
Instead of opening and closing connections for every request, connection pooling uses a cache of database connections that can be reused when future requests to the database are required. It lets your database scale effectively as the data stored there and the number of clients accessing it grow. Traffic is never constant, so pooling can better manage traffic peaks without causing outages. Your production database shouldn’t be your bottleneck.
In this article, we will explore how we can use connection pooling middleware like pgpool and pgbouncer to reduce overhead and network latency. For illustration purposes, I will use pgpool-II and pgbouncer to explain concepts of connection pooling and compare which one is more effective in pooling connections because some connection poolers can even affect database performance.
We will look at how to use pgbench to benchmark Postgres databases since it is the standard tool provided by PostgreSQL.
Different hardware provides different benchmarking results based on the plan you set. For the tests below, I’m using these specifications.
Specs of my test machine:
- Linode Server: Ubuntu 16 - 64 bit ( Virtual Machine)
- Postgres version 9.5
- Memory: 2GBDatabase size: 800MB
- Storage: 2GB
Also it is important to isolate the Postgres database server from other frameworks like logstash shipper and other servers for collecting performance metrics because most of these components consume more memory and will affect the test results.
Creating a pooled connection
Connecting to a backend service is an expensive operation, as it consists of the following steps:
- Open a connection to the database using the database driver.
- Open a TCP socket for CRUD operations
- Perform CRUD operations over the socket.
- Close the connection.
- Close the socket.
In a production environment where we expect thousands of concurrent open and close connections from clients, doing the above steps for every single connection can cause the database to perform poorly.
We can resolve this problem by pooling connections from clients. Instead of creating a new connection with every request, connection poolers reuse some existing connections. Thus there is no need to perform multiple expensive full database trips by opening and closing connections to backend service. It prevents the overhead of creating a new connection to the database every time there is a request for a database connection with the same properties (i.e name, database, protocol version).
Pooling middleware like pgbouncer comes with a pool manager. Usually, the connection pool manager maintains a pool of open database connections. You can not pool connections without a pool manager.
A pool contains two types of connections:
- Active connection: In use by the application.
- Idle connection: Available for use by the application.
When a new request to access data from the backend service comes in, the pool manager checks if the pool contains any unused connection and returns one if available. If all the connections in the pool are active, then a new connection is created and added to the pool by the pool manager. When the pool reaches its maximum size, all new connections are queued until a connection in the pool becomes available.
Although most databases do not have an in-built connection pooling system, there are middleware solutions that we can use to pool connections from clients.
For a PostgreSQL database server, both pgbouncer and pgpool-II can serve as a pooling interface between a web service and a Postgres database. Both utilities use the same logic to pool connections from clients.
pgpool-II offers more features beyond connection pooling, such as replication, load balancing, and parallel query features.
How do you add connection pooling? Is it as simple as installing the utilities?
Two ways to integrate a connection pooler
There are two ways of implementing connection pooling for PostgreSQL application:
- As an external service or middleware such as pgbouncer
Connection poolers such as pgbouncer and pgpool-II can be used to pool connections from clients to a PostgreSQL database. The connection pooler sits in between the application and the database server. Pgbouncer or pgpool-II can be configured in a way to relay requests from the application to the database server.
- Client-side libraries such as c3p0
There exist libraries such as c3p0 which extend database driver functionality to include connection pooling support.
However, the best way to implement connection pooling for applications is to make use of an external service or middleware since it is easier to set up and manage. In addition external middleware like pgpool2 provides other features such as load balancing apart from pooling connections.
Now let’s take a deeper look at what happens when a backend service connects to a Postgres database, both with and without pooling.
Scaling database performance without connection pooling
We do not need a connection pooler to connect to a backend service. We can connect to a Postgres database directly. To examine how long it takes to execute concurrent connections to a database without a connection pooler, we will use pgbench to benchmark connections to the Postgres database.
Pgbench is based on TPC-B. TPC-B measures throughput in terms of how many transactions per second a system can perform. Pgbench executes five SELECT, INSERT, and UPDATE commands per transaction.
Based on TPC-B-like transactions, pgbench runs the same sequence of SQL commands repeatedly in multiple concurrent database sessions and calculates the average transaction rate.
Before we run pgbench, we need to initialize it with the following command to create the pgbench_history, pgbench_branches, pgbench_tellers, and pgbench_accounts tables. Pgbench uses the following tables to run transactions for benchmarking.
pgbench -i -s 50 database_name
Afterward, I executed the command below to test the database with 150 clients
pgbench -c 10 -j 2 -t 10000 database_name
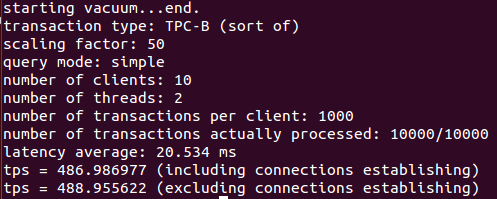
As you see, in our initial baseline test, I instructed pgbench to execute with ten different client sessions. Each client session will execute 10,000 transactions.
From these results, it seems our initial baseline test is 486 transactions per second.
Let’s see how we can make use of connection poolers like pgbouncer and pgpool to increase transaction throughput and avoid a ‘Sorry!, too many clients already’ error.
Scaling database performance with pgbouncer
Let’s look at how we can use pgbouncer to increase transaction throughput.
Pgbouncer can be installed on almost all Linux distributions. You can check here how to set up pgbouncer. Alternatively, you can install pgbouncer using package managers like apt-get or yum.
If you find it difficult to authenticate clients with pgbouncer, you can check GitHub on how to do so.
Pgbouncer comes with three types of pooling:
- Session pooling: One of the connections in the pool is assigned to a client until the timeout is reached.
- Transaction pooling: Similar to session polling, it gets a connection from the pool. It keeps it until the transaction is done. If the same client wants to run another transaction, it has to wait until it gets another transaction assigned to it.
- Statement pooling: Connection is returned to the pool as soon as the first query is completed.
We will make use of the transaction pooling mode. Inside the pgbouncer.ini file, I modified the following parameter:
max_client_conn = 100
The max_client_conn parameter defines how many client connections to pgbouncer (instead of Postgres) are allowed.
default_pool_size = 25
The default_pool_size parameter defines how many server connections to allow per user/database pair.
reserve_pool_size = 5
Thereserve_pool_size parameter defines how many additional connections are allowed to the pool.
As in the previous test I executed pgbench with ten different client sessions. Each client executes 1000 transactions as shown below.
pgbench -c 10 -p -j 2 -t 1000 database_name
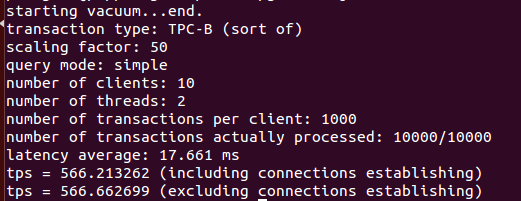
As you see, transaction throughput increased from 486 transactions per second to 566 transactions per second. With the help of pgbouncer, transaction throughput improved by approximately 60%.
Now let’s see how we can increase transaction throughput with pgpool-II since it comes with connection pooling features.
Unlike pgbouncer, pgpool-II offers features beyond connection pooling. The documentation provides detailed information about pgpool-II features and how to set it up from source or via a package manager
I changed the following parameters in the pgpool.conf file to make it route clients connections from pgpool2 to Postgres database server.
connection_cache = on
listen_addresses = ‘postgres_database_name’’
port = 5432 Setting the connection_cacheparameter to on activates pgpool2 pooling capability.
Like the previous test, pgbench executed ten different client sessions. Each client executes 1000 transactions to the Postgres database server. Thus we expect a total of 10,000 transactions from all clients.
gbench -p 9999 -c 10 -C -t 1000 postgres_database
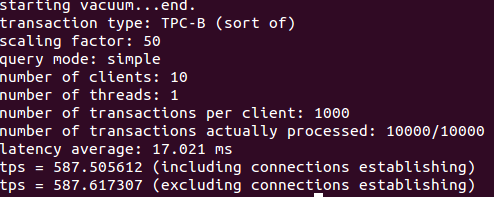
In the same way we increased transaction throughput with pgbouncer, it seems pgpool2 also increased transaction throughput by 75% as compared to the initial test.
Pgbouncer implements connection pooling ‘out of the box’ without the need to fine-tune parameters while pgpool2 allows you to fine-tune parameters to enhance connection pooling.
Choosing a connection pooler: pgpool-II or pgbouncer?
There are several factors to consider when choosing a connection pooler to use. Although pgbouncer and pgpool-II are great solutions for connection pooling, each tool has its strengths and weaknesses.
Memory/resource consumption
If you are interested in a lightweight connection pooler for your backend service, then pgbouncer is the right tool for you. Unlike pgpool-II, which by default allows 32 child processes to be forked, pgbouncer uses only one process. Thus pgbouncer consumes less memory than pgpool2.
Streaming Replication
Apart from pooling connections, you can also manage your Postgres cluster with streaming replication using pgpool-II. Streaming replication copies data from a primary node to a secondary node. Pgpool-II supports Postgres streaming replication, while pgbouncer does not. It is the best way to achieve high availability and prevent data loss.
Centralized password management
In a production environment where you expect many clients/applications to connect to the database through a connection pooler concurrently, it is necessary to use a centralized password management system to manage clients' credentials.
You can make use of auth_query in pgbouncer to load clients’ credentials from the database instead of storing clients’ credentials in a userlist.txt file and comparing credentials from the connection string against the userlist.txt file.
Load balancing and high availability
Finally, if you want to add load balancing and high availability to your pooled connections, then pgpool2 is the right tool to use. pgpool2 supports Postgres high availability through the in-built watchdog processes. This pgpool2 sub-process monitors the health of pgpool2 nodes participating in the watchdog cluster as well as coordinating between multiple pgpool2 nodes.
Conclusion
Database performance can be improved beyond connection pooling. Replication, load balancing, and in-memory caching can contribute to efficient database performance.
If a web service is designed to make a lot of read and write queries to a database, then you have multiple instances of a Postgres database in place to take care of write queries from clients through a load balancer such as pgpool-II while in-memory caching can be used to optimize read queries.
Despite the pgpool-II ability to function as a loader balancer and connection pooler, pgbouncer is the preferred middleware solution for connection pooling because it is easy to set up, not too difficult to manage, and primarily serves as a connection pooler without any other functions.