
This post was written by Adrian Cockcroft, VP of Cloud Architecture Strategy at AWS. If you want to learn more he will be speaking at the AWS Chaos Engineering and Resiliency Series online event, taking place Oct 27-28th from 11am-2pm in the AEDT timezone.
I’ve been working on resilient systems for many years. In the 1990’s as a Distinguished Engineer at Sun Microsystems, I helped some of the first Internet sites through their early growth pains and joined eBay in 2004 with the title Distinguished Availability Engineer. In 2007 Netflix hired me to help them build scalable and resilient video streaming services and in 2010 I led their transition to a cloud-based architecture on AWS. For the last ten years, I’ve been building and talking about Chaos Engineering, multi-zone and multi-region cloud architectures, and modernizing development practices.
As applications move online and digital automation extends to control more of the physical world around us, software failures have an increasing impact on business outcomes and safety. We need to develop more resilient systems, and that can’t be left as an operational concern. Engineers need to architect resilience into the application code, and operability is one of the most important attributes of a resilient system. The operator experience needs to be clear and responsive, especially during a failure. We’ve seen many examples of small initial problems escalating, as poorly designed and tested error-handling code and procedures fail in ways that magnify the problem, and take out the whole system.
What can we do about this? To start with, it’s a shared responsibility across your technical teams to build and operate systems that are observable, controllable, and resilient. With the integration of roles from DevOps practices and the automation provided by cloud providers, we need to adapt common concepts and terminology that already exist in resilient systems design for cloud-native architectures.
What should your system do when something you depend on fails? There are three common outcomes. It could stop until whatever failed is restored; it could work around the failure and continue with reduced functionality; or it could fall over and cause an even bigger failure! Unfortunately, for many systems today, the third outcome is the default, either because they were not architected to survive or, more critically they were not tested regularly to prove that the architected solutions worked as intended.
There are many kinds of failure to think about, but I’m going to concentrate on what is usually called disaster recovery or business continuity. Many organizations have a backup datacenter strategy and a plan to fail over to the backup if there is a failure in their primary datacenter. However, when I ask people how often they exercise their application failover capability, they normally look embarrassed. Many organizations have never tested a failover, and some that do only do it as part of a time-consuming and painful annual audit process. My next question is whether they ever pull the plug on an entire datacenter at once, so all the applications have to fail over together. Most people are horrified by the idea of trying that as a test. The people who take this seriously have had it happen to them when an actual disaster caused a failover.
I call this state of affairs “availability theater.” You’ve gone through the motions and play-acted a disaster recovery scenario, but despite spending a lot on the production, it’s not real. What you have is a fairy tale: “Once upon a time, in theory, if everything works perfectly, we have a plan to survive the disasters we thought of in advance.” In practice, it’s more likely to be a nightmare.
When failovers fail
The Uptime Institute records public information about outages. Their 2018-19 report highlighted a trend: “Major publicly recorded outages are now more likely to be caused by IT and network problems than a year or two years ago, when power problems were a bigger cause.” The way we develop and operate systems is critical, so what can we do to improve the situation? To start, we should learn from people who have been studying failures and building more resilient systems for decades, adopt their terminology (rather than inventing new words for old concepts) and adapt their ideas to the problems of keeping applications running.
If we look at the kind of “IT and network problems...” that are causing outages, they are failures of complex systems. Published in 1984, Charles Perrow’s book Normal Accidents was inspired by the 1979 Three Mile Island accident, where a nuclear meltdown resulted from an unanticipated interaction of multiple failures in a complex system. The event was an example of a normal accident because it was "unexpected, incomprehensible, uncontrollable, and unavoidable.”
“Disasters and fatalities are outliers and aren’t part of the distribution of possible outcomes that most people consider and model because they are inherently unacceptable.”
Why are disasters unexpected? Todd Conklin’s 2017 book, Workplace Fatalities: Failure to Predict, points out that disasters and fatalities are outliers and aren’t part of the distribution of possible outcomes that most people consider and model because they are inherently unacceptable. We have a very topical example at the moment. I don’t think many organizations had “global pandemic” in their 2020 business plan, so it fits the pattern—unexpected, incomprehensible, uncontrollable, and unavoidable. We’ve also seen that governments that did have a well-tested plan expected the pandemic, understood it better, were able to control it, and avoided the worst consequences.
The concept of using failover to increase resilience is that there should be more than one way to succeed and a way to switch between them. It’s relatively easy to add redundancy to a system, to verify that the extra capacity exists, and to justify the extra cost of redundancy against the cost of failure. It’s much harder to build and test the ability to successfully fail over. For a system to truly be resilient, the failover switch needs to be far more reliable than the alternatives it’s switching between; otherwise, failures of the switch itself dominate overall system reliability. A system configuration that includes failover is more complex and has more opportunities to fail than a simpler system. This is why the best practice is to get to a mature level of operational excellence in a simpler system before adding failover mechanisms.
Unfortunately, the failover switching mechanism and related management processes are often the least tested parts of the system, which is why systems often collapse when they attempt to fail over. To fix this, we need to move from custom-built, painful, annual disaster recovery test processes to automated and continuously tested resilience. The reason this is possible now is that cloud computing provides consistent automation, together with chaos engineering techniques and tools, that allow us to standardize and productize failover capabilities.
What are chaos engineering techniques? Defined simply they are experiments to ensure that the impact of failure is mitigated. You need to run experiments that introduce failures, to show that your system can handle those failures without causing user-visible problems.
When you look at a complex system through the lens of chaos engineers, you can think of it as links in a chain. A chain is only as strong as the weakest link, so outages are often triggered by the one thing that you overlooked or hadn’t got around to fixing yet. The other way of thinking about it is a rope with many strands, some frayed and some broken. The many strands of a rope form a capacity margin, but if you don’t pay attention to the number of strands that are broken, you will eventually “drift into failure” as Sydney Dekker discussed in his book of the same name.
In this way of thinking, the last strand that broke when the failure occurred isn’t the “cause of the failure.” The systematic neglect of the frayed cable over time is the cause. To be topical again, a lightning strike may trigger a specific forest fire, but preventing that one lightning strike may not have prevented a fire from being triggered by something else. If the forest is dried out and full of dead trees because of climate change, then that’s a systematic cause of forest fires.
Applying this thinking to applications needing to fail over without falling over, we need to build in and maintain some safety margin, so that individual small failures don’t escalate and cause disasters. The concepts of “defense in depth” and “checks and balances” are useful, and need to be applied to all the layers of the system. However, they need to be tested frequently to be sure that the checks and safety margin are present and having the desired effect.
Engineering a safer world
The characteristics of a resilient system can be divided into four layers:
- Experienced staff - Use “game days” to understand how the system behaves when it’s managing failures, and know how to quickly observe and control problems.
- Robust applications - Have been tested using fault injection and chaos testing tools.
- Dependable switching fabric - An application framework that compensates for faults by routing around them
- Redundant service foundation - Redundant automated services that carefully maintain isolation so that failures are independent
If we are trying to make our normal accidents less “unexpected, incomprehensible, uncontrollable, and unavoidable,” then we can start by doing a hazard analysis. Understanding what accidents are possible should result in fewer unexpected accidents. We can increase observability and in particular improve the operator’s user experience during accidents to make them less incomprehensible. Then we can look at how to make the system more controllable during an accident. Finally, since accidents are unavoidable, the most general capability we can develop is speed of detection and response to minimize their impact.
I saw this play out in my time at Netflix. We built a system that became quite robust over time, and most of the normal things that go wrong were being handled, so we had very few customer impacting incidents. Unfortunately, the incidents we did have were ones we hadn’t seen before. We got rid of the easy and common incidents and were left with infrequent incidents that were unexpected, incomprehensible, uncontrollable, and unavoidable.
To make sure everyone practiced what to do during an incident, and to catch problems quickly, Netflix increased the frequency of game day failover tests from once a quarter to every two weeks. This way, we could catch any new problems early, and strengthen the lynchpin of our resilient system, experienced staff, by making them more familiar with accidents.
A Theory of Accidents: Planes, Trains, and Nuclear Missiles
As I look for new ways to help prevent failures from becoming fall overs, I’ve been exploring System Theoretic Process Analysis (STPA), which is part of a broader set of techniques called System Theoretic Accident Model and Processes (STAMP). This is described in the book Engineering a Safer World by Nancy G. Leveson of MIT.
The techniques were refined out of many hazard analysis projects, including systems used for inflight refueling systems, US air traffic control, and nuclear missile launch systems. STPA is based on a functional control diagram of the system, and the safety constraints and requirements for each component in the design. A common control diagram we can use for IT systems is divided into three layers: the data plane that is the business function itself, the control system that manages that business function, and the human operators that watch over the control system.
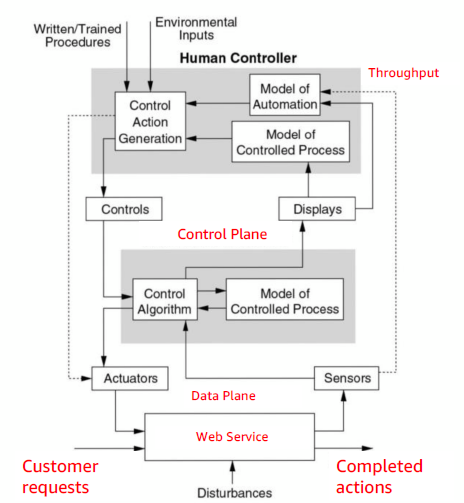
The focus is on understanding the connections between components and how they are affected by failures. In a “boxes and wires” diagram, most people focus on specifying the boxes and their failure modes and are less precise about the information flowing between boxes. With STPA, there is a focus on the wires, what control information flows across them, what happens if those flows are affected, and the models that consume the information and drive control actions.
There are two main steps that form good checklists for thinking about your own design. First, identify the potential for inadequate control of the system that could lead to a hazardous state. This state may result from inadequate control or enforcement of the safety constraints. For the second step, each potentially hazardous control action is examined to see how it could occur. Evaluate controls and mitigation mechanisms, looking for conflicts and coordination problems. Consider how controls could degrade over time, using techniques like change management, performance audits and incident reviews to surface anomalies, and problems with the system design.
If we take the general STPA model and map it to a specific application, such as a financial services API that collects customer requests and performs actions, then the human controller monitors the throughput of the system to make sure it’s completing actions at the expected rate. The automated controller could be an autoscaler that is looking at the CPU utilization of the controlled process, scaling up and down the number of instances that are supporting the traffic to maintain CPU utilization between a fixed minimum and maximum level.
If the service CPU utilization maxes out and throughput drops sharply, the human controller is expected to notice and decide what to do about it. The controls available to them are to change the autoscaler limits, restart the data plane or control plane systems, or to roll back to a previous version of the code.
The hazards in this situation are that the human controller could do something that makes it worse instead of better. They could do nothing, because they aren’t paying attention. They could reboot all the instances at once, which would stop the service completely. They could freak out after a large drop in traffic caused by many customers deciding to watch the Superbowl on TV and take an action before it is needed. They could do something too late, like notice eventually after the system has been degraded for a while and increase the autoscaler maximum limit. They could do things in the wrong order, like reboot or rollback before they increase the autoscaler. They could stop too soon, by increasing the autoscaler limit, but not far enough to get the system working again, and go away assuming it’s fixed. They could spend too long rebooting the system over and over again. The incident response team could get into an argument about what to do, or multiple people could make different changes at once. In addition, the runbook is likely to be out of date and contain incorrect information about how to respond to the problem in the current system. I’m sure many readers have seen these hazards in person!
Each of the information flows in the system should also be examined to see what hazards could occur. In the observability flows, the typical hazards are a little different than the control flows. In this case, the sensor that reports throughput could stop reporting and get stuck on the last value seen. It could report zero throughput, even though the system is working correctly. The reported value could numerically overflow and report a negative or wrapped positive value. The data could be corrupted and report an arbitrary value. Readings could be delayed by different amounts so they are seen out of order. The update rate could be set too high so that the sensor or metric delivery system can’t keep up. Updates could be delayed so that the monitoring system is showing out of date status, and the effect of control actions aren’t seen soon enough. This often leads to over-correction and oscillation in the system, which is one example of a coordination problem. Sensor readings may degrade over time, perhaps due to memory leaks or garbage collection activity in the delivery path.
The third area of focus is to think about the models that make up the system, remembering the maxim “All models are wrong, some models are useful.” An autoscaler contains a simple model that decides what control action is needed based on reported utilization. This is a very simple view of the world, and it works fine as long as CPU utilization is the primary bottleneck. For example, let’s assume the code is running on a system with four CPUs and a software update is pushed out that contains changes to locking algorithms that serialize the code so it can only make use of one CPU. The instance cannot get much more than 25% busy, so the autoscaler will scale down to the minimum number of instances, but the system will actually be overloaded with poor throughput. Here, the autoscaler fails because its model doesn’t account for the situation it’s trying to control.
The other important model to consider is the internal mental model of whoever is operating the system. That model is created by training and experience with the system. The operator gets an alert and looks at throughput and utilization and will probably be confused. One fix could be to increase the minimum number of instances. If they are also able to see when new software was pushed out and that this correlates with the start of the problem, then they could also roll back to a previous release as the corrective control action.
Some questions we could ask: is the model of the controlled process looking at the right metrics and behaving safely? What is the time constant and damping factor for the control algorithm? Will it oscillate, ring, or take too long to respond to inputs? How is the human controller expected to develop their own models of the controlled process and the automation, then understand what to expect when they make control inputs? How is the user experience designed so that the human controller is notified quickly and accurately with enough information to respond correctly, but without too much data to wade through or too many false alarms?
Failover without collapsing in practice
The autoscaler example provides an easy introduction to the concepts, but the focus of this story is how to fail over without falling over, and we can apply STPA to that situation as well. We should first consider the two failover patterns that are common in cloud architectures, cross zone and cross region.
Availability zones are similar to datacenter failover situations where the two locations are close enough together that data can be replicated synchronously over a fairly low latency network. AWS limits the distance between availability zones to under 100 kilometers, with latency of a few milliseconds. However, to maintain independent failure modes, availability zones are at least ten kilometers apart, in different flood zones, with separate network and power connections. Data that is written in one location is automatically updated in all zones, and the failover process is usually automatic, so an application that is running in three zones should be able to keep running in two zones without any operator input. This maintains application availability with just a few glitches and retries for some customers and no loss of data.
The other pattern is cross region. Regions are generally far enough apart that latency is too high to support synchronous updates. Failovers are usually manually initiated and take long enough that they are often visible to customers.
The application and supporting service configurations are different in the two cases, but the essential difference from a hazard analysis point of view is what I want to focus on. I will assume zone failovers are triggered automatically by the control plane, and region failovers are triggered manually by an operator.
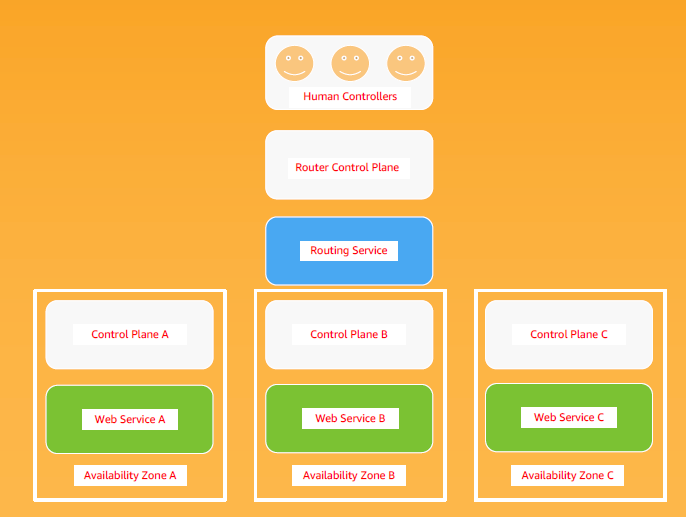
In an automated cross-zone failover situation, what is likely to happen? An in-rush of extra traffic from the failed zone and extra work from a cross-zone request-retry storm causes the remaining zones to struggle and triggers a complete failure of the application. Meanwhile, the routing service that sends traffic to the zones and acts as the failover switch also has a retry storm and is impacted. Confused human controllers disagree among themselves about whether they need to do something or not, with floods of errors, displays that lag reality by several minutes, and out of date runbooks. The routing control plane doesn’t clearly inform humans whether everything is taken care of, and the offline zone delays and breaks other metrics with a flood of errors.
In cross-zone failovers, human controllers should not need to do anything! However, confused and working separately, they try to fix different problems. Some of their tools don’t get used often and are broken or misconfigured to do the wrong thing. They eventually realize that the system has fallen over. The first few times you try this in a game day, this is what you should expect to happen. After fixing the observability issues, tuning out the retry storms, implementing zoned request scoping to avoid non-essential cross-zone calls, and setting up alert correlation tools, you should finally be able to sit back and watch the automation do the right thing without anyone else noticing.
If you don’t have the operational excellence in place to operate frequent successful zone failure game days, then you shouldn’t be trying to implement multi-region failover. It’s much more complex, there are more opportunities for failure, and you will be building a less reliable system.
What’s likely to happen during a cross-region fail-over? The failed region creates a flood of errors and alerts, these delays breaks other metrics, and the cross-region routing control plane doesn’t clearly inform humans that a region is unusable. Human controllers should initiate failover! As stated above for the zone level failover, they are confused, and disagree among themselves. In fact, the problem is worse because they have to decide whether this is a zone level failure or a region level failure, and respond appropriately.
Operators then decide to initiate failover but they redirect traffic too quickly, extra work from a cross-region request-retry storm causes other regions to struggle, and triggers a complete failure of the application. Meanwhile, the routing service also has a retry storm and is impacted, so the operators lose control of the failover process. Sounds familiar? Some readers may have PTSD flashbacks at this point. Again, the only way you can be sure that a failover will work when you need it is to run game days frequently enough that operators know what to do. Ensure retry storms are minimized, alerts floods are contained and correlated, and observability and control systems are well tested in the failover situation.
Your operators need to constantly maintain their mental model of the system. This model is created by experience operating the system and supported by documentation and training. However, with continuous delivery and a high rate of change in the application, documentation and training isn’t going to be up to date. When cross-zone and cross-region failovers are added to the operating model, it gets far more complex. One way to reduce complexity is to maintain consistent patterns that enforce symmetry in the architecture. Anything that makes a particular zone or a region different is a problem, so deploy everything automatically and identically in every zone and region. If something isn’t the same everywhere, make that difference as visible as possible. The Netflix multi-region architecture we deployed in 2013 contained a total of nine complete copies of all the data and services (three zones by three regions), and by shutting down zones and regions regularly, anything that broke that symmetry would be discovered and fixed.
Failover is made easier by the common services that AWS provides, but gets much more complex if each application has a unique failover architecture, and there is little commonality across the AWS customer base. The AWS Well Architected Guide Reliability Pillar contains lots of useful advice, and it also supports common practices and languages across accounts and customers, which socializes a more consistent model across more human controllers. This standardization of underlying services and human operator model by AWS is a big help in building confidence that it will be possible to fail over without falling over.
Where should you start? I think the most effective first step is to start a regular series of game day exercises. Train your people to work together on incident calls, get your existing dashboards and controls together, and you will have a much faster and more coordinated response to the next incident. Create your own control diagrams, and think through the lists of hazards defined by STPA. Gradually work up from game days using simulated exercises, to test environments, to hardened production applications fixing things as you go.
If you’d like to learn more about this topic, I’m the opening speaker in the AWS Chaos Engineering and Resiliency Series online event, taking place Oct 27-28th from 11am-2pm in the AEDT timezone. Best wishes, and I hope the next time you have to fail over, you don’t also fall over!
References
Paper: Building Mission Critical Financial Services Applications on AWS
By Pawan Agnihotri with contributions by Adrian Cockcroft
Well Architected Guide - Reliability Pillar:
https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/welcome.html
Related blog posts by @adrianco
https://medium.com/@adrianco/failure-modes-and-continuous-resilience-6553078caad5
Response time variation: https://dev.to/aws/why-are-services-slow-sometimes-mn3
Retries and timeouts: https://dev.to/aws/if-at-first-you-don-t-get-an-answer-3e85
Source for various slide decks at: https://github.com/adrianco/slides
Book recommendations, reading list at: http://a.co/79CGMfB
The Stack Overflow blog is committed to publishing interesting articles by developers, for developers. From time to time that means working with companies that are also clients of Stack Overflow’s through our advertising, talent, or teams business. When we publish work from clients, we’ll identify it as Partner Content with tags and by including this disclaimer at the bottom.