[Ed. note: While we take some time to rest up over the holidays and prepare for next year, we are re-publishing our top ten posts for the year. Please enjoy our favorite work this year and we’ll see you in 2022.]
As a Java developer, I have spent most of my professional life working on the parts of software systems that most people don’t see. The so-called back-end of the software stack. But lately I have found myself wanting to branch out, and dabbling more in HTML and UI development.
A couple of years ago, this natural curiosity led me to start a new side project. My project was meant to be a hobby application that would only be used by me and a few friends, so I didn’t spend too much time thinking about a long term roadmap or requirements. The main goal was to get it working fast.
I settled on JHipster, a development platform for building web applications using modern technology: Angular, React or Vue for the client side, and Spring plus Gradle or Maven for the server side. It’s been around for years, is very well documented, and has great community support.
Within a few weeks I had a functioning application that met all my needs. But a funny thing happened soon after I launched. Other people started using the application. Knowing I had created something useful for a large audience was really satisfying. And so I did what any other developer who is already stretched thin and trying to balance a full time job and a family and hobby projects would do: I spent my nights, weekends, and every free moment I had working on it.
However, the more I tried to improve it, the harder things got. I spent a lot of time looking up how to do new things that weren’t part of the boilerplate setup. I was learning some of the limitations that now felt like major roadblocks. And after a few months, it became clear to me that my choice of technologies was becoming a hindrance to making the application better. Ultimately, I decided to re-write most of it using frameworks that were more familiar to me.
I want to pause here and clarify: JHipster and Angular are not bad platforms. Far from it. I’d recommend them in heartbeat for the right project.
When I say they were becoming a hindrance, what I really mean is that my lack of knowledge of the technologies had come back to bite me. For all the reasons I had chosen them, there were plenty of other reasons that might have made me think differently, had I known about them.
It was a classic developer lament: I didn’t know what I didn’t know.
And what I came to realize is that my application was suffering in several key areas that were a direct result of the platforms I had chosen. Things like SEO, social sharing, and caching. Features that didn’t matter for a hobby application, but were vital to the long term success of a growing product.
Even though I ultimately ended up re-writing the application and it has continued to thrive, I think it’s important to reflect back on the early days of the project. There are so many lessons to learn from both success and failures. I wanted to dive into some of the things I learned the hard way when I wrote my first single-page app, and hopefully help others who find themselves in the same boat.
Anatomy of a single-page application
Before diving into some of the issues I ran into, it’s worth breaking down the basic principles of a single-page app. This is meant to be a high level overview and not a technical deep dive on any specific platform.
Web browsers work using a traditional client-server model. A web browser (the client) sends a request for some page to a web host (the server). The server sends back some HTML to the web browser. That HTML includes structured text along with links to other files such as images, CSS, JavaScript, etc. The combination of the HTML, along with these other files, allows the web browser to render a meaningful web page for the user.
And thus the world turns. You click a link, your web browser sends the request to the server, and the server sends back some HTML. Every response back from the server is the full HTML document required to render a web page.
A single-page app breaks this paradigm. The web browser sends the initial request and still gets back some HTML. But the response from the server is just a bare bones HTML document with no real content. On its own, this HTML is generic and doesn’t represent anything specific about the web site.
Instead, it contains a handful of placeholder elements, along with some links to JavaScript files. These JavaScript files are the heart and soul of the single-page app. Once loaded, they send back requests to the server to fetch content, and then dynamically update the HTML in the web browser to create a meaningful web page.
By all outward appearances, the application behaves like a traditional web site. The user sees HTML with images and buttons and interacts the exact same way. But under the hood things are very much different.
Search engine optimization
Search engine optimization (SEO) is the process of formatting web page content so that is easy for web crawlers to understand it.
Just like a web browser, Google and other web crawlers request the HTML contents for pages on a web site. But instead of rendering it like a web browser would, it analyzes the HTML to semantically understand what the web page is about.
And that’s where I ran into my first problem. HTML is structured and easy for computers and bots to understand, but they don’t necessarily understand JavaScript. While there are plenty of articles that debate whether or not Google’s crawler executes JavaScript when crawling a website, my experience was that it did not.
The reason I knew this is because Google was telling me that it didn’t understand my content. When I looked at the search analytics for my site, it was ranking for exactly one keyword. And that keyword had nothing to do with my website.
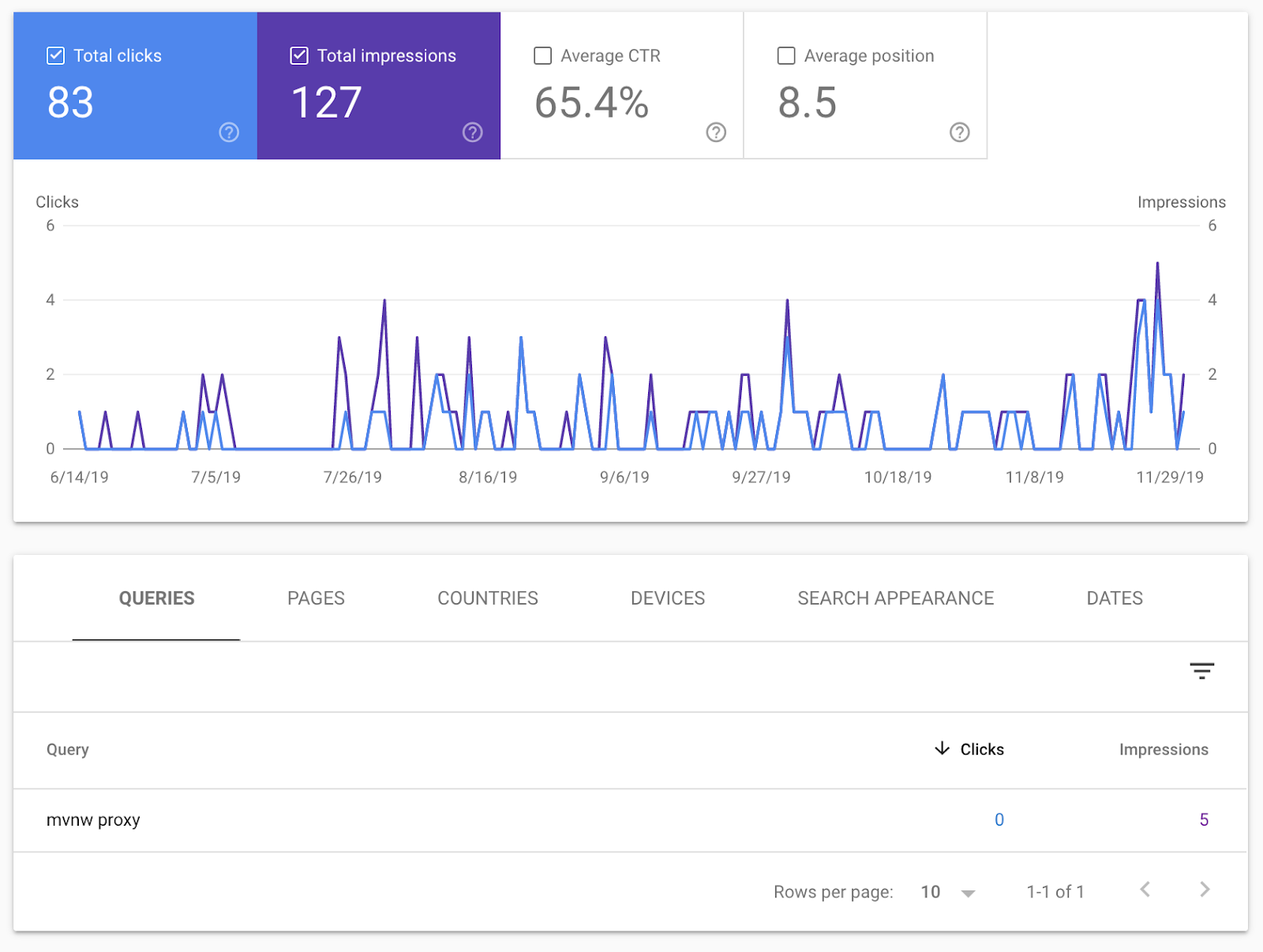
As the graphic shows, Google thought my website was related to Maven proxy configuration. Needless to say, my hobby project was not in any way related to the open source Apache project.
So what was happening? My website had hundreds, if not thousands, of unique web pages with varying content. Yet, Google only showed it in search results to people searching for the words “mvnw proxy”. Even if SEO wasn’t a main focus of mine, after a few months Google should have been able to ascertain that my site wasn’t about Maven proxy configuration.
The problem was that Google’s crawler was not executing the required JavaScript files that made my single-page application function. It was loading the template HTML file and scanning its structure for hints about what my site was actually about.
And like most single-page apps, the default HTML included lots of helpful developer information that is intended to be used for trouble-shooting, but never actually displayed in a web browser when things are working properly. Even worse, the template is the same for all URLs on the site, so Google got the same (wrong) interpretation for every page it crawled.
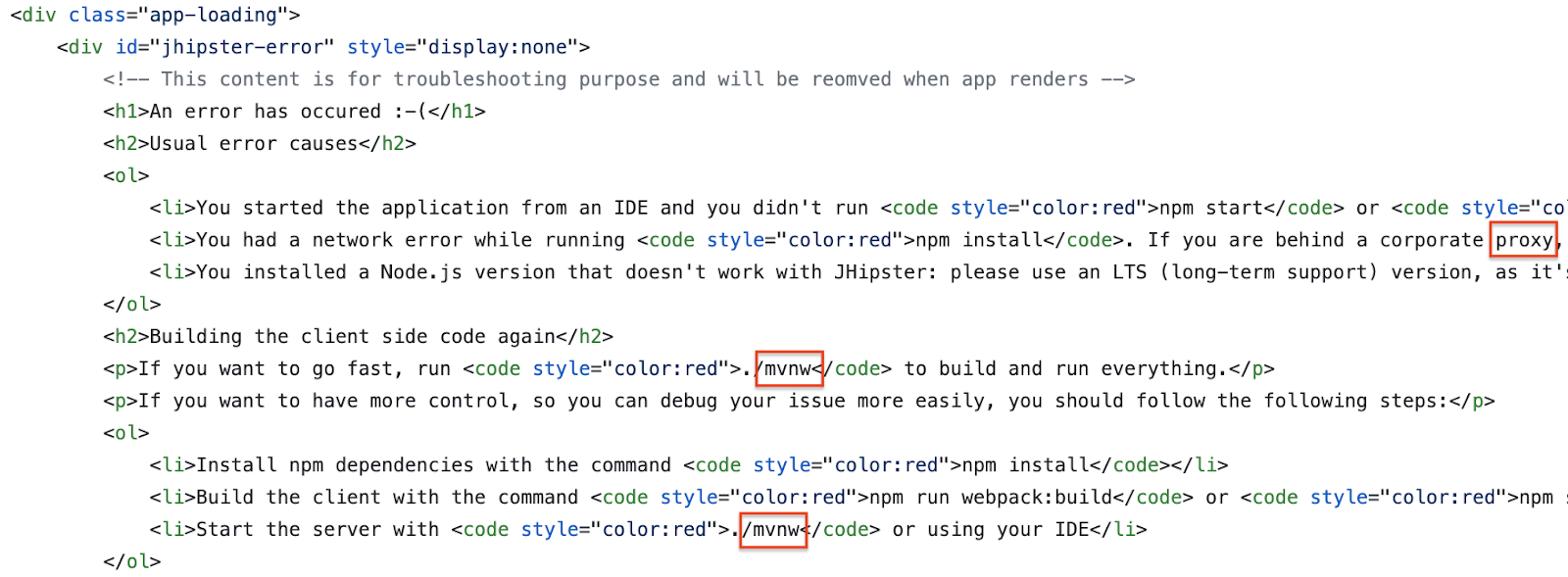
Above is a snippet from the HTML template. You can see the words mvnw and proxy show up in various places, and Google was using these signals to interpret my website. Had Google’s crawler correctly applied the associated JavaScript, it would have seen that every URL on the site had a lot more unique and meaningful content.
Social Sharing
Another area I ran into problems with was social sharing. My website allowed users to create dynamic content, and also included lots of static content that others might find useful. And in the early days of launching, I indeed saw that people were sharing links to my websites across various social media platforms:
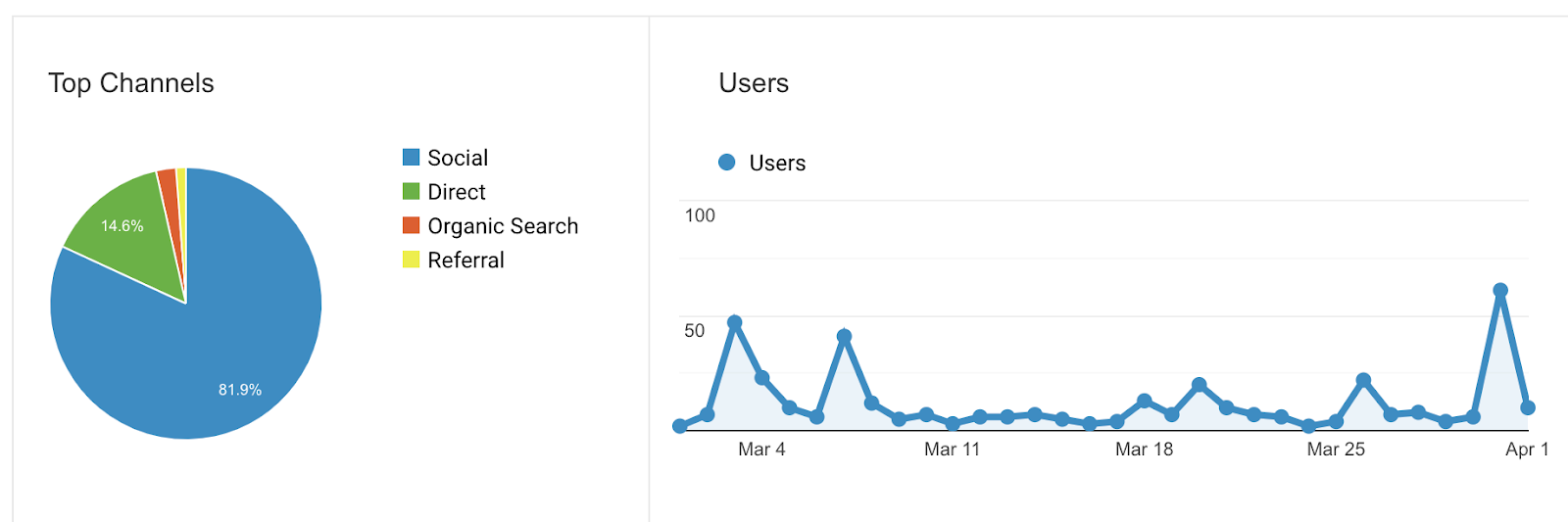
Social networks, much like search engines, rely on the content in web pages to understand what the web page is about. Unlike search engines though, they rely less on the visible content of the web page (the text and images humans see) and more on the metadata (the stuff inside the HTML that us humans don’t care much about).
For example, when you share a link to a website on Facebook, the first thing that happens is Facebook reads the webpage and generates a nice preview of that article. The preview has a title, a line or two of descriptive text, and an image.
But those previews are not generated magically or using some sophisticated AI algorithm. Facebook is relying on metadata inside the HTML header area to create previews. It’s entirely up to website owners to provide the information Facebook needs to build a meaningful preview of every page on their website. Many CMS systems such as WordPress make this really easy with plugins. But I was writing a brand new application from scratch and would have to create this metadata on my own.
In my case, Facebook was falling victim to the same problem Google was. It was reading the template HTML file as-is, and not applying the JavaScript that would help fill in the metadata and create meaningful previews.
What this meant for my users is that every link from my website that was shared to Facebook and other social networks was generating the exact same preview. Whether it was users sharing their custom content, one of the static pages that I auto generated, or even the home page, every link shared on social media had the same preview.
Functionally speaking, nothing was wrong. A user could still click on the preview and be taken to the correct URL on the site. But I didn’t like the idea that the preview wasn’t helpful. After all, I was trying to grow my user base. If someone shared my content to their friends and family, I wanted to have the best chance of people clicking those links so they could discover the site.
Caching
Another area I quickly became concerned with was caching. With a small user base initially, I never worried much about expensive database queries or page load times.
But as new users started to use the website, I started to get worried about these things. Were my queries as performant as possible? Was I taxing MongoDB with too many requests? Would new users give up if a page took too long to load?
I’m never a fan of premature optimizations, but this was an area that I felt would become a problem quickly if things kept trending the way they were. So I started thinking about how to improve some of the MongoDB queries and page load bottlenecks. And one of the first things that came to mind is caching.
I’ve worked with a variety of enterprise caching technologies such as Coherence, Ignite, Redis, and others. For what I was looking to do, these all felt like overkill. Plus, they would add to the compute and memory costs of a project that was still technically only a hobby.
Instead, I decided this was a perfect use case for CloudFlare. I was already using CloudFlare as my DNS provider because they provide a ton of great features for free. And one of those great features is page caching. It’s free and requires no additional coding on my part.
Here’s how it works. CloudFlare acts as a reverse proxy to my website. This means all requests are really going through their infrastructure before being forwarded to my website. Among other things, this allows them to cache my server responses across their vast network of global data centers. All I have to do is configure which set of URLs I want them to cache and how long they should be cached, and CloudFlare handles all the heavy lifting. All without me writing a single line of code.
Periodically, the cached content will expire and CloudFlare will need to pass the request on to my server. But on aggregate, this approach can drastically reduce load on your server because far fewer requests end up getting through. As a bonus, the user experience is improved because returning the cached content is much faster than having your web server generate it from scratch.
This all sounded great in theory. But in practice, it wasn’t quite working as I expected. After making the change and enabling page caching, there was no appreciable difference in my MongoDB cluster resources. I was expecting to see an appreciable decrease in resource utilization as far fewer queries would be made. But instead I saw things mostly staying the same.
So what was going on? It all goes back to the template HTML file that single-page apps use. CloudFlare doesn’t execute any JavaScript prior to caching the response. It simply takes the raw HTML response from the origin server and caches it. In my case, that response was the template HTML. And the net result is that every page I wanted to cache, was really just caching the same template HTML.
So when a user requested one of those cached pages, CloudFlare simply returned the bare bones template HTML to them. And in turn, the user’s web browser would load this template and download the required JavaScript files. Those JavaScript files would send a bunch of requests to my server to get the real content for the page, meaning whatever expensive queries I was hoping to avoid were always going to be executed.
Technology envy
Another general area I wish I had been more cognizant of is technology envy. As a developer wanting to improve my skill set and value to potential employers, I’m constantly on the lookout for new technology. But sometimes it’s easy to get envious of what others do, without realizing the skills you already have are valuable too.
This happens a lot on social media. I’m constantly in awe, and frankly a bit jealous, of what some of other people create and build. I see buzzwords and technology and think to myself, “I really ought to know how to use these things.” And while there is value in learning new things, it’s more important to be adaptable and know the right tools for the job. As the saying goes, a jack of all trades but a master of none.
And that’s exactly what happened when building my first single-page app. I was so caught up in the short term excitement of learning a new technology, I never stopped to consider how that decision would impact the future of the app.
And eventually this came back to haunt me. As new feature requests came in or I had new ideas, I found the choice of framework ever more frustrating. Whenever I wanted to add a new page, for example, there were multiple areas of Angular code to touch: routers, controllers, services, templates, etc. I was constantly looking up how to do things, and went down my fair share of rabbit holes trying to figure out “problems” that eventually proved to be my own doing.
In a sense, this is how we learn. We can take all the programming boot camps and courses under the sun, but real learning comes from frustration. Real knowledge and understanding come from hours spent stepping through code in a debugger. Unfortunately for me, this project had taken on new meaning and it was no longer the right context for me to explore and learn.
Conclusion
This isn’t meant to be a critique of single-page apps on the whole. It’s a cautionary tale that I think many developers can relate to. The excitement of learning something new, creating a functioning application from the ground up, and then reflecting on the lessons learned along the way. And even though I eventually re-wrote my application using technology I was more familiar with, the experience was invaluable.
Mistakes are good. They help us learn. They help us make better decisions down the road. I’ve already got new ideas for how I can use single-page apps for other projects I am working on. And this time I’ll have confidence knowing they are the right tool for the job. I can also now confidently speak to clients and tell them when I think a single-page app makes sense for their use case. And I can discuss my experience with colleagues, helping them to avoid some of the pitfalls I had to deal with. In the end, this was still just a hobby project, and the experience I gained will go a long way.
In a perfect world, developers would have all the information they need up front. Every requirement, every change in scope would be known ahead of time. But this isn’t how our industry works. We create roadmaps as best we can, and we choose technologies that make sense given what we know. More often than not, our best laid plans don’t pan out the way we envision. And that’s ok.