Developers are famed for wanting to rewrite software, especially when they “inherited” the software and they can’t be bothered to understand how it works. Experienced managers and senior engineers know that rewrites should be avoided unless they are truly necessary, as they typically involve a lot of complexity and can introduce new problems along the way.
This is a story about trying to rethink complex systems: the challenges you face when you try to rebuild them, the burdens you face as they grow, and how inaction itself can cause it’s own problems. When you’re weighing the risk and reward of replacing architecture, it can take several attempts to find a solution that works for you.
I’m a Senior Engineer at Pusher, a company focused on building real-time messaging APIs. Pusher Channels, our pub/sub WebSocket service used for building scalable realtime data functionality, has been around for quite a while. Until fairly recently, all of Channels ran on AWS EC2 instances. Machines were provisioned and bootstrapped with Python scripts which wrapped Ansible playbooks. Configuration and process management was mostly handled by Puppet, with help from Upstart, God, and a lot of tools written in-house.
We managed EC2 instances like pets. If a machine had to be replaced, an engineer manually migrated traffic/services from the old machine to the new one, and shut down the old one. If a cluster needed more capacity, an engineer provisioned some new machines and attached them to the cluster. This approach had its downsides:
- There was a chunk of manual work involved in keeping stuff up and running
- The in house tooling made onboarding new team members tricky
...but it worked pretty well for quite a while and large parts of this system are still pushing us to new heights. Team members changed, we launched Pusher Beams, we sunsetted Pusher Chatkit, and our user base just kept on growing. All the while, the Pusher Channels infrastructure stayed mostly the same while seriously increasing in scale. And this is where the problems started.
Maintenance
As the Channels clusters got larger, the maintenance burden of operating it seemed to scale almost linearly. Before long a significant amount of engineering time each week was spent just keeping things up and running.
It was clear that we needed to do something to reduce the maintenance burden; trying to maintain a highly reliable service for our customers, however, meant we have spent the last few years battling the inevitable build up of tech debt and legacy infrastructure that comes with managing and maintaining complex systems at scale.
We made numerous attempts to try and modernise our infrastructure and application in this time but ran into many of the common problems associated with trying to rewrite or re-architect systems. That means that we were still facing the same challenges. A lot of these problems stemmed from trying to modernise the infrastructure and the application at the same time, rather than trying to focus on the biggest challenge that we faced, which is the management and maintenance of the infrastructure itself.
The breakthrough
We had spent some time going back and forth between various approaches. We tried to introduce more automation into our existing infrastructure provisioning system, and we tried a ground up rewrite of our core application services. However, lots of the solutions were entangled with or dependent on each other in non-obvious ways.
Most of these solutions required new types of infrastructure that we didn’t already have. This then had a "soft" dependency on some of the skills we had in the team to add new types of infrastructure with our existing tooling.
After a number of setbacks, we decided to go back to first principles and look again at the most important priorities. We wanted to select a solution that would achieve the key goals with scope to continue iterating in the future. We summarised that the overall aim should be to end up with a platform that is simpler, consistent, easier to maintain and easier to scale. This would allow us to spend less time maintaining and managing platforms and more time building and developing new products and features.
After doing a complete audit of the current state of our infrastructure and application we came to the following conclusions:
- Offload as much infrastructure complexity as possible to a managed services
- Migrate as much of the existing application as possible to this new infrastructure without having to do large rewrites of the application codebase
- Identify components that could be re-envisioned, re-architected, or re-written without adding friction to the infrastructure migration and invest in transforming and simplifying them.
The infrastructure
We'd been keen to begin leveraging auto-scaling groups for some time. After analysing the work required to make use of auto-scaling groups, we determined this would require a significant investment to either:
- Extend our custom-built deployment tooling—which depends on EOL software already—to work with cloudinit and migrate from upstart to systemd. This would have also increased onboarding time for new hires due to the bespoke nature of the solution.
- Migrate to a technology that the industry has standardised around, like containers.
We chose to adopt containers because investing time/energy/money into our in house solution made no sense.
Containerising
In order to migrate to containers we would need to:
- containerise core application services,
- update the build process for application services to build and store container images,
- choose some way of running those containers in production,
- change the routing process for services’ traffic to handle container termination more gracefully
When we broke down the work required to containerise our existing EC2 setup for auto-scaling groups, we were most of the way towards something like Kubernetes, which we were using heavily elsewhere in the company and offered us a great deal more functionality.
There would be extra work, for example, adding additional management services to move our core application services to Kubernetes. In the end, we decided that it was worth it for the following reasons:
- Purpose built for our problem - Kubernetes is built to solve the problem we had—resiliently managing a workload across many nodes.
- In-house experience - We had a lot of Kubernetes experience in-house and were already running multiple clusters.
- Hiring - Kubernetes is one of the dominant tools in the space. Hiring engineers with Kubernetes experience, or a desire to learn it, was significantly easier for us than hiring people who wanted to work with Puppet/Ansible.
- Onboarding - Our existing solution was fairly bespoke so any new joiners had to spend a decent chunk of time learning the ins and outs of all of our homemade tooling. Kubernetes has great documentation so new starters can get up to speed more quickly even if they don't have experience with it.
- Offloading infrastructure complexity - This change would allow us to shift complexity to a managed service like EKS
The application
One of the traps that we have previously fallen into when trying to improve Channels was trying to rewrite large parts of the application while simultaneously trying to reduce the maintenance burden of running the infrastructure. This tightly coupled approach led to a few setbacks and abandoned attempts. With this new plan, we were mostly finding solutions to port large parts of our application services to Kubernetes without doing large application rewrites.
We were still keen to strategically improve parts of the application, however, so long as it didn’t fundamentally add friction to migrating to new infrastructure. We found this approach gave engineers the freedom to make technical improvements to the application and opportunities to reduce the maintenance burden of application components that frequently run into issues that wouldn’t be solved by porting to Kubernetes.
As an example, we recently wrote about our webhook system from EventMachine on EC2 to Go on Kubernetes. One thing this didn’t cover was re-writing the component that actually dequeues jobs from SQS and sends webhooks. This component had recently started causing a large number of alerts and alarms and was in need of refactoring.
Re-writing the webhook sender
We knew it was important to port our webhook sender component from EC2 to Kubernetes, as we had begun to experience increasing operational issues with this component. Because of the lack of autoscaling, the processes responsible for sending webhooks were running on dedicated EC2 machines we called sender machines. On one of our clusters, we had four sender machines, each running 12 webhook-sender processes (called Clowns,because they “juggle” jobs from a queue). This was comfortably sufficient for the peak load of the cluster so we had some headroom for unexpected spikes.
As we had already largely rewritten most of the webhook pipeline in Go, it also made sense to look at completing the process by rewriting the sender itself. The webhook sender is a pretty straightforward piece of software. It reads jobs from an SQS queue and makes HTTP POST requests. The job the process reads from SQS contains everything the process needs to send the HTTP POST request to the customer's server.
Because the webhook sender is an embarrassingly parallel process it makes a great fit for taking advantage of the scaling benefits of a system like Kubernetes.By re-writing this in Go we could also realise some performance benefits over EventMachine, much like we had with the webhook packager and publisher.
Because the webhook sender is a stateless service, it was easy to deploy the new sender alongside the old sender and let them both compete for jobs. This meant that we could gradually roll out the new sender and rely on the old sender to keep servicing the queue in case of unexpected issues. In fact,what we found on some smaller clusters was that the new sender was so efficient the old sender basically had no work to do.
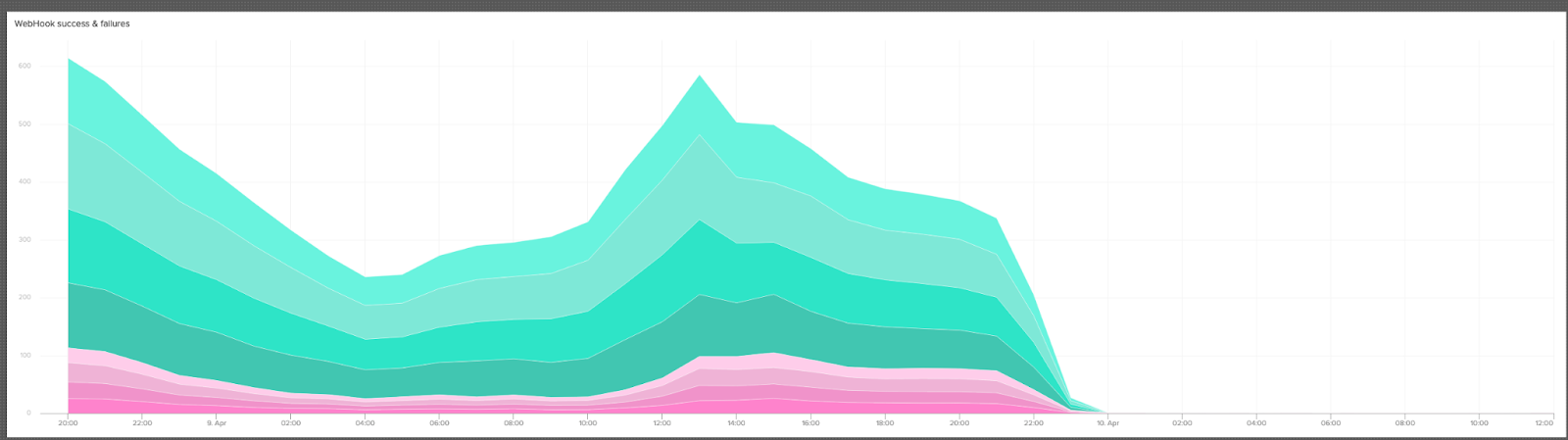
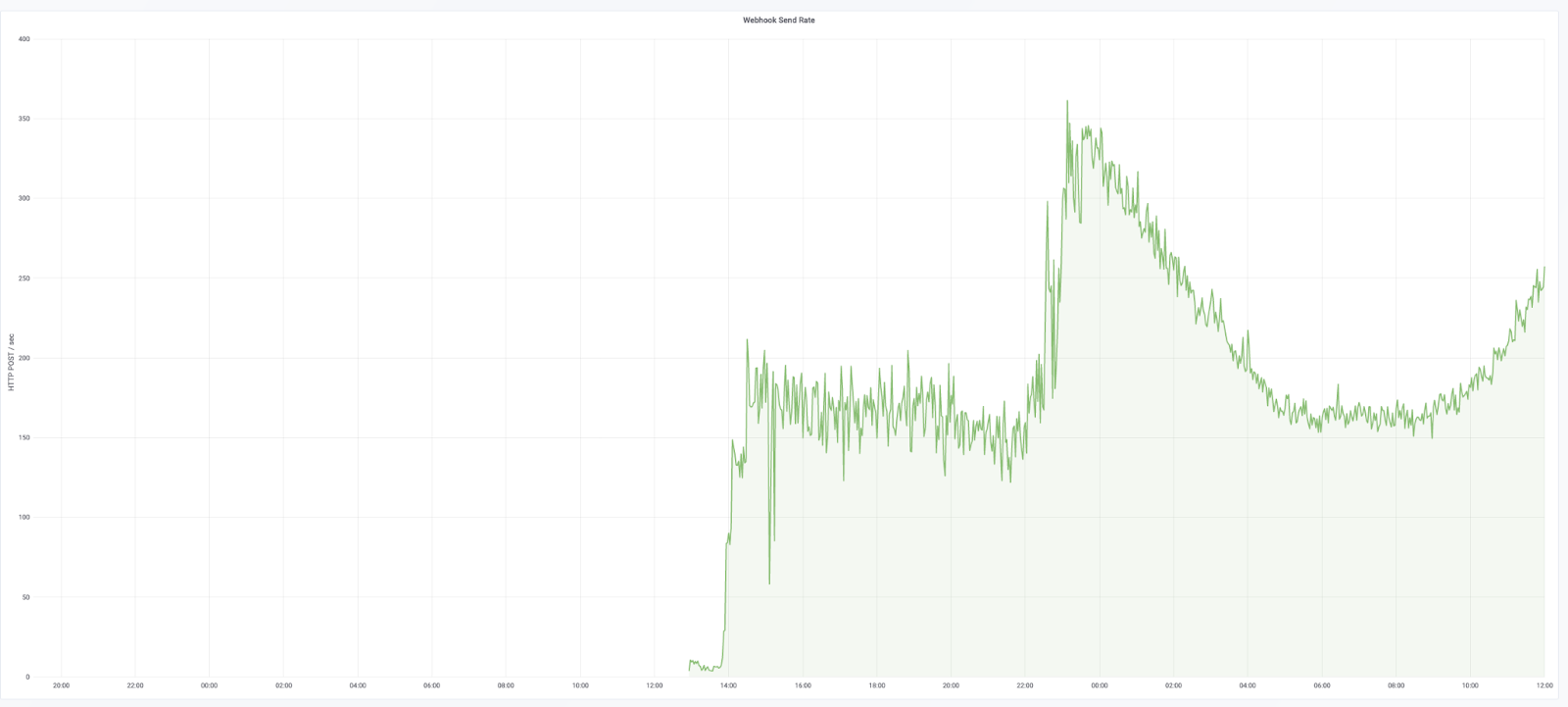
In the end, our largest cluster went from 4 * machines, each with 12 clowns, to 3-15 Kubernetes pods, each requesting 250mCPU.
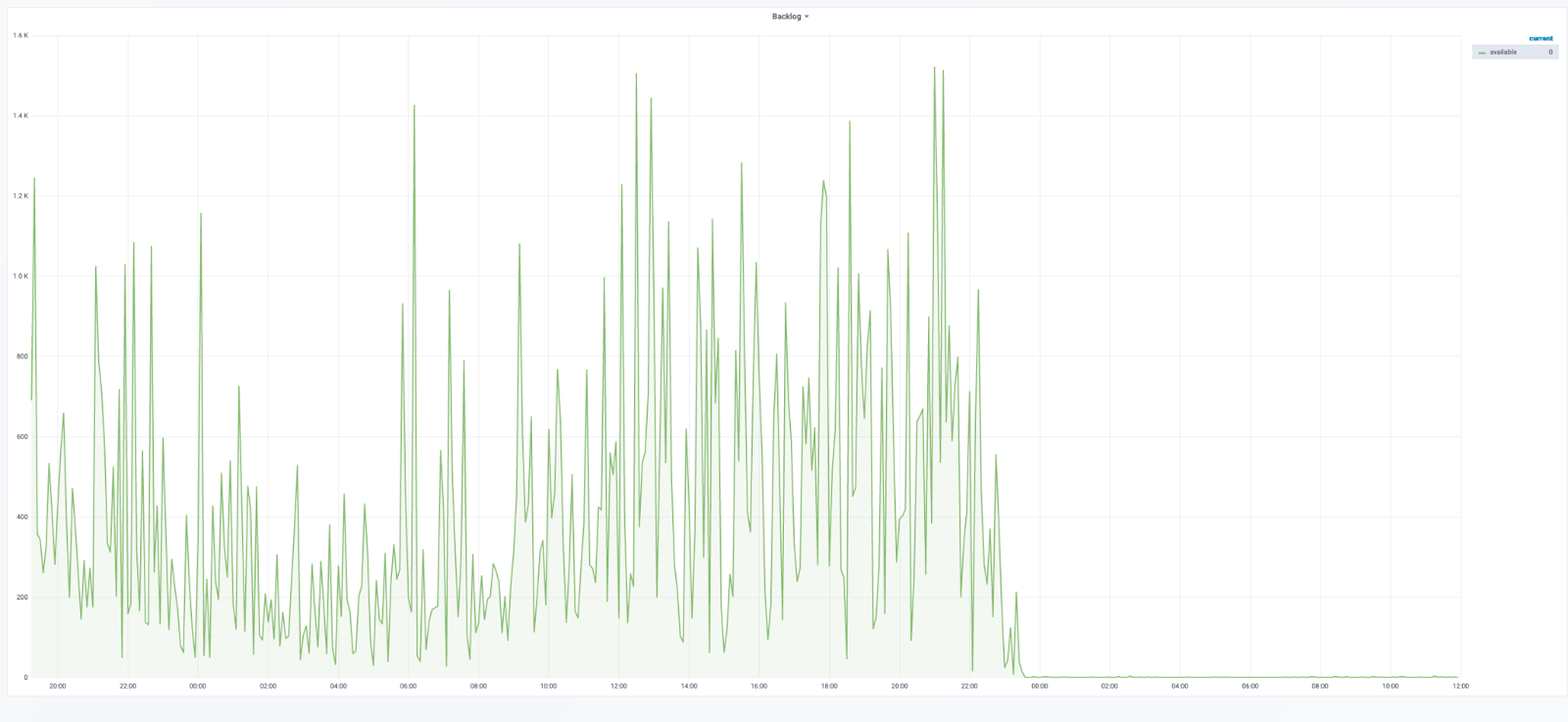

In short, this was highly successful. Another component from our EC2 and Eventmachine architecture crossed off the list and another <N> boxes removed.
Summary
Well-documented stories about trying to rebuild, re-architect, and re-envision systems are countless, and often contain a warning about embarking on such projects. Those of us with previous experience in architecture overhauls will almost always avoid rewrites at any cost because they so often go wrong. Also, complex systems are usually that way for a reason. As explained by Chesterton’s fence, we are usually better off assuming that the person who came before us knew something we did not.
After some failures and challenges along the way, however, we found a path to progress and an approach that does allow us to rewrite code effectively and efficiently while also reducing our maintenance burden. To be fair, our rewrite probably wasn’t what Joel Spolsky meant when he called rewrites one of the things you should never do.
But what we have found is that by identifying components with well defined boundaries, it is possible to rewrite them without throwing entire systems away. If you can identify well-defined boundaries and interfaces, things become a lot easier. In the case of the webhooks pipeline, this had a logical boundary in the form of a queue. We could rewrite parts of this over time, which gave us great ability to test and verify new components in the pipeline while still having the ability to rollback in case of failure.
We have also found that with each one of these projects completed, we are realising benefits of less operational burden, which means we can actually speed up the rate of progress. Making that initial breakthrough was the greatest challenge and it’s important to keep up momentum to avoid slipping back into an unsustainable realm. Now that we’ve broken the wall, we’re excited and confident about having a simpler system that allows us to focus on doing the stuff we actually love to do—building great products and cool features, rather than just keeping the lights on.
The Stack Overflow blog is committed to publishing interesting articles by developers, for developers. From time to time that means working with companies that are also clients of Stack Overflow’s through our advertising, talent, or teams business. When we publish work from clients, we’ll identify it as Partner Content with tags and by including this disclaimer at the bottom.