
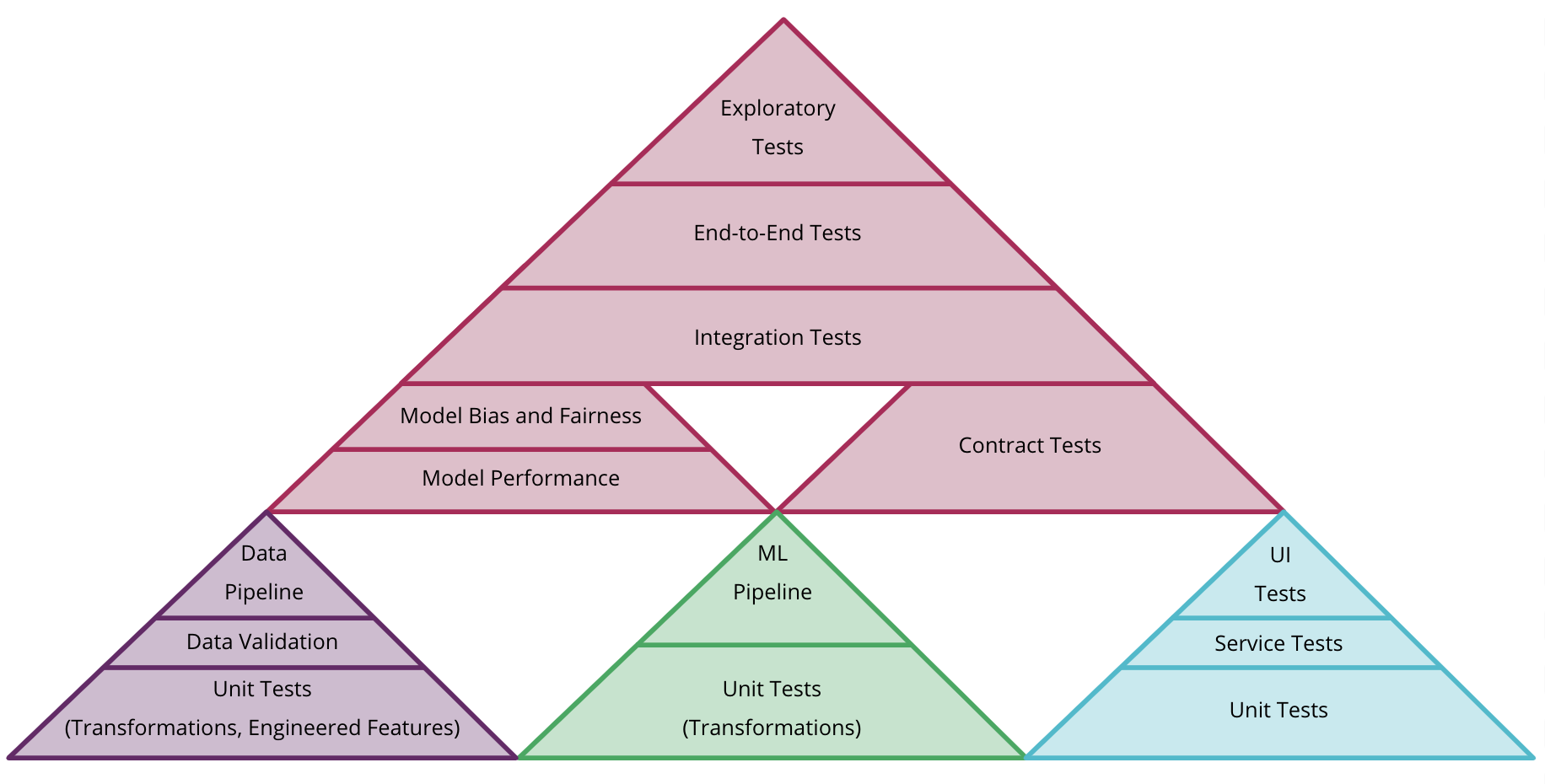
Software is complex, and as developers, we all understand the need for building and testing a good quality assurance (QA) process. However, training deep learning models and implementing them in production creates new challenges for testing quality. Many of the well-known testing approaches are not directly applicable to deep learning models. This blog post gives some practical insights into the QA process of a full deep learning pipeline.
QA is different in deep learning
In normal software QA, you can spot a failure when the software crashes, then slowly back the bug into a corner through breakpoints and print statements. But the initial point of failure is rarely ambiguous.
Deep learning models fail silently. It can be hard to identify the points of failure as there are many candidates. A suboptimal learning rate or mislabeled sample will not raise a stacktrace; it will just worsen the results until they are useless. In this process, it’s hard to do the step-by-step debugging we are used to.
Have you ever tried to understand the impact of one of the 25 million parameters of a ResNet50 model? Deep learning models are too complex to understand the dependencies. The black box (model) can solve the problem correctly only if all elements of the training and inference pipeline work as intended. The more complex the algorithm and the bigger the impact of the deployed software, the more quality checks are necessary. A reliable QA process is therefore crucial for the long-term success of a deep learning project.

Data as a part of the algorithm
Keep in mind that the role of training data is very different from the role of data in classical algorithms (that is, compared to customer data in a database). The data is not only passively processed by the algorithm, it’s actively shaping the solution by influencing the model training. No deep learning pipeline can achieve good results without proper data.
The difficulty in the QA process for training data lies in the volume of samples that we have to handle. Manual inspection and testing of the full dataset is hardly possible and can be very costly.
To tackle the problem, define important metrics like a minimum quality for samples, balancing requirements for different categories, or similarity scores for samples. It’s useful to start with manual spot checks on a small subset of the data to get an idea what the dataset looks like and what problems might occur. When we know what to look for, we can then use statistical methods to gain insights into the full dataset. As with our code, datasets will change within the development process, so it makes sense to automate the statistical process and repeatedly collect metadata from the dataset. This helps us track and understand quality changes over time.
In addition to challenges with the raw data, things can go wrong during preprocessing. To test for correct and useful data preparation, write unit tests. For some operations, it’s possible to check if the process can be reverted correctly (normalization of images).
Validate the full data pipeline before feeding data into the next step. Without useful data, no useful models can be trained.
Checklist for data quality:
- Define important metrics
- Spot-check a subset of the data
- Automatically calculate dataset statistics and track changes
- Validate the full data pipeline from scraping and labeling to preprocessing
Training done right
Let’s be honest: hundreds of cool training methods, tuning algorithms, and experimental parameters have been published that make experimentation with deep learning models really exciting. But implementing all of the latest research right at the start of the development process will usually lead not to a superior model, but to wasted resources, wasted time, and disappointment. Implementing too many untested features at once makes debugging very difficult. And even if the results are decent, who knows if they are optimal for the given inputs?
A basic model architecture and safe default parameters can help at the start. Automate system tests, checking for basics like reducing loss, valid outputs, and successful weight updates. From there, architecture complexity can be increased, hyperparameters tuned, and more fancy algorithms added.
Pay special attention to the correct calculation of metrics, as future decisions and model selection will be based on them. If there are custom parts in the model (that is, non-standard layers or loss-functions), a unit test is probably a good idea.
To select the best model from a set of training iterations, we analyze our performance metrics. But independent smoke tests can help identify flaws, giving us more confidence in the results and improving model regularization. Making this validation step as independent as possible from the training process (for example, by using a separate inference pipeline), helps us to identify possible bugs. A manually created, discrete test set including edge cases and difficult samples should be used for this purpose.
Checklist for model training:
- Start with a basic model setup and increase complexity stepwise
- Include extra tests for metrics
- Unit-test custom parts of the model
- Validate the final model with a well-crafted test set to gain confidence
Avoiding failures in deployment
To solve actual problems, it’s necessary to deploy models. Often, the inference environment and engine can look and behave quite differently from the training setup. The deployed system might use different preprocessing of the inputs, making results either unusable or just marginally worse. Also, some hardware might prune the outputs or calculate with a different level of precision. Separate tests should be in place for each use case. We should deploy regularly to identify problems quickly, so we (again) need automation.
To implement models in production, standard software engineering principles for continuous integration and deployment (CI/CD) are applicable.
Checklist for testing deployments:
- Automate model export and include parameters required for inference
- Perform integration testing on all device types and configurations
- Deploy often, deploy early in separate staging environments
Testing the pipeline
To ensure that a solution actually solves the problem, a final end-to-end test with handpicked samples from real-world data is recommended. This final test should be highly specific for the problem statement and should continuously check whether the complete pipeline is working as intended. For object tracking, one could label a small set of videos and test the counting or track accuracy on target devices. For text sentiment analysis, a test with real-world reviews could show potential flaws. Another approach is qualitative investigation, where you could ask users of the system what they consider a standard scenario.
Final quality checks:
- Perform end-to-end testing with real-world data on target platform(s)
- Prefer actual use-cases over synthetic data and artificial scenarios
- Track testing accuracy for different software releases
- Include tests for edge cases (such as unexpected inputs)
Using the pipeline and iterating
Finally, use a version control for both code and data. This helps to log changes and debug possible issues. It’s not recommended to change data and algorithms at the same time, as the effects are not traceable.
Now that the pipeline is set up, tests and validations are in place, and everything is automated, it’s time to increase the number of experiments. Try out new methods and find the best possible solution. We can do this now with a high confidence that we can identify failures early in the process and correctly validate the results. Remember to test and deploy regularly and add new tests where applicable.
Sources
https://stackoverflow.blog/2021/09/13/why-your-data-needs-a-qa-process/
https://karpathy.github.io/2019/04/25/recipe/?s=09
https://martinfowler.com/articles/cd4ml/test-pyramid.png
{kind=link}
https://towardsdatascience.com/testing-machine-learning-pipelines-22e59d7b5b56
https://www.kdnuggets.com/2019/11/testing-machine-learning-pipelines.html
https://towardsdatascience.com/architecting-a-machine-learning-pipeline-a847f094d1c7