Have you ever imagined what you could do if you could easily incorporate vision-based AI into any embedded hardware project? You could develop a smart home security camera that recognizes your pet and allows them to move around without triggering alerts. You could add vision AI to your gardening project, warning you when flowers need watering. Or maybe a remote-control car that follows you around, recording your bike tricks while also avoiding obstacles.
When developers figured out how to use the massive parallel processing capabilities of GPUs for something other than maxing out FPS on Call of Duty, it opened up a whole new world for computer vision applications. But strapping a specialized GPU to a camera isn’t exactly a scalable solution, and while systems like this are commercially available, that level of hardware sophistication and AI integration can feel daunting if you’ve never worked on it before.
In an effort to empower developers, Xilinx made an affordable, easy-to-implement production-grade SOM (system on module). Instead of a months-long learning and development process, developers can use the Kria KV260 Vision AI starter kit to create a prototype of their AI powered vision system in a few hours.
If this project piques your interest, read on. We’ll talk about the traditional challenges with adding computer vision to a project, such as FPGA programming and the lack of flexibility in most hardware, then discuss how the Kria SOM makes incorporating computer vision possible for makers of every kind.
Complex tech, complex market
The availability of massive amounts of data, particularly vision data, has led to a boom in the applications for vision AI processing. But as this technology has gotten more complex, so too has the market for solutions. The market has grown more diverse and fragmented as companies try to create custom—but not always scalable—platforms and approaches. For curious engineers looking to experiment with vision AI hardware, it can be daunting to figure out where to get started.
There’s another challenge for AI developers, and this one is physical. Vision AI processes a massive amount of data on hardware. You could stream this video for processing in a data center, but then you’d be at the mercy of network latency. Many vision-based applications need millisecond-scale responses, so your compute must happen on the device—the edge, as it’s often called.
With edge hardware, you must worry about power requirements and thermal design considerations. New high-accuracy AI models are not always built with edge hardware constraints in mind. Developers who aim for a deployable device, either as a one-off or at scale, must figure out how to build vision AI-enabled devices in a reasonable form factor that can adapt when novel techniques and new project requirements come along.
Traditionally, Xilinx has provided hardware solutions for vision AI applications at a chip level. This still leaves a big challenge: developing the remainder of the hardware platform and the software infrastructure (board-support package) for that platform. If you’re a software engineer just looking to experiment, creating an optimized, cost-effective prototype powerful enough to accelerate a wide range of vision and AI pipelines and suitable to work beyond your prototypes might be outside of your skillset.
Furthermore, AI is a rapidly changing domain, with the implication that inference accelerators such as SoCs (system-on-a-chip) and GPUs may be out-of-date by the time you are ready for production. Xilinx Adaptive SoC technology, incorporated into the Kria SOM, leverages FPGA technology to enable future customization of the underlying neural network accelerator and vision pipeline. This flexibility ensures that your chosen platform remains relevant as technology needs shift: future-proofing your design.
On the downside, FPGA programming has historically been a difficult and specialized skill. You first need to know how to design digital circuits—you’re essentially creating specialized processor logic to execute specific algorithms—and understand what registers, adders, multiplexers, and lookup tables all do. Then you have to create that logic in a hardware description language, like Verilog or VHDL, both of which may look like C or Pascal (respectively), but require a different mindset to code well. On top of that, you need to learn to use the FPGA development tools.
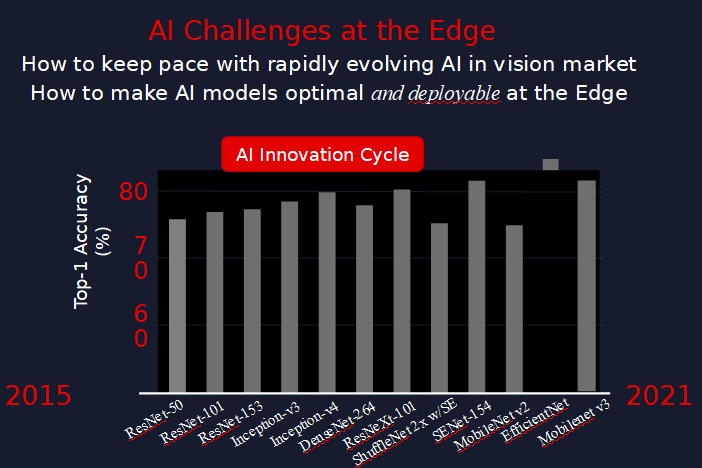
Furthermore, neural network architecture can have a significant effect on overall performance, and that can matter a lot for energy-conscious hardware projects. While inference benchmarks for simple classification networks are available for virtually any inference hardware platform, benchmarks for complex networks that solve real-world problems may not be readily available, so you may go into a hardware project not knowing how well your chosen network performs. In my experience, many companies find midway through their project that their chosen platform fails to meet performance requirements with the result that they have to go back to the drawing board. Marketing feature-creep further exacerbates this problem. Is it any wonder that some 87% of AI projects never make it to production?
For example, consider that many vision applications use convolutional neural networks (CNN). In classical convolution, every input channel has a mathematical impact on every output channel. If we have 100 input channels and 100 output channels, there are 100x100 virtual paths. In 2017, a team of researchers created MobileNet CNNs that were computationally efficient without sacrificing accuracy. Their novel technique used depthwise convolution to replace classical convolution. However, with depthwise convolution, each input channel only impacts one output channel, with the result that we save a lot of computation.
But no solution comes without some tradeoffs. Computationally-efficient networks are not necessarily hardware-friendly. As a result, GPUs and other inference accelerator architectures could not fully realize the theoretical performance gains of depthwise convolution.
The catch was that the device was still processing the same amount of data. There are fewer computations, but each is handling more data, so memory bandwidth becomes the system bottleneck. If not architected with depthwise convolution in mind, the neural network accelerator becomes memory-bound and thus achieves lower levels of efficiency as many elements of the accelerator array sit like dark servers in a data center, consuming power and space, while performing no useful work. The result was that a chip designed before this technique was known wouldn’t yield the expected performance gains.
But what if your chosen hardware platform leveraged FPGA-based architectures that could be reconfigured in the field to ensure optimum performance as new network architectures or techniques such as depthwise convolution become available? That’s the advantage of the Xilinx Adaptive SoC on the Kria KV26 SOM.
We’ve covered how the system works and why it’s adaptable. Still, if you’re just starting a vision AI hardware project, solving the multi-dimensional equation of how to get started may scare you away. This is where Kria SOMs and the KV260 Vision AI Starter Kit come in.
A simpler way to get started
At Xilinx, we realized that we could give engineers more bang for their buck if we focused on specific vision AI use cases and provided a production-ready platform that would enable developers to get to market quickly. From the hardware perspective, the solution is simple – provide the key components as a single board solution: System-on-module (SOM). SOMs have the advantage that they incorporate the processor, memory, key peripherals, and more on a single board, ensuring that you have the basic elements needed to target vision AI.

Think of the SOM like a video game console: a specialized piece of hardware designed for a very specific purpose. In the case of the Kria KV26, that purpose is vision AI. By tailoring the hardware to this specific application, we optimize the hardware size and cost. Plus, it’s production-ready, available from Xilinx in both industrial and commercial grade offerings.
Now that you have hardware, there are a few details to take care of: configuring the Xilinx Adaptive SoC on the Kria SOM and compiling your AI model to run on the platform. We wanted developers to be able to take advantage of the power of Adaptive SoCs without having to develop the underlying vision pipeline and neural network accelerator. Still, for developers who do need something custom, Xilinx has partners that will design the right logic for the project, or, you can leverage the Vitis tools to integrate your own customizations without becoming an FPGA expert.
Xilinx has historically offered PetaLinux, a Yocto-based flavor of Linux where there is no single distribution binary. Users download the sources, then configure and build them before they can start developing applications. Hardcore embedded developers typically love this style—they know Linux and want full control of what’s in their kernel.
But for those developers who are looking to get up and running immediately without having to build their entire OS, we are introducing Ubuntu for Kria SOMs, with publication of Ubuntu images optimized directly for Xilinx by Canonical. Ubuntu is the most popular open-source distribution of Linux and is generally familiar to developers. You can download the Ubuntu binary image for Kria, boot, and start developing. With Ubuntu, you can choose packages that are familiar to you and install them on Kria. The option to leverage Ubuntu with Linux packages accelerates the development of vision AI platforms.

The final production implementation can leverage bitbake recipes to compile a production Linux image that includes the libraries that you need for deployment. Alternatively, you can obtain a production Ubuntu license from Canonical, thus retaining the ability to dynamically install packages. Whether you are a hard-core Yocto developer or a pure software developer who loves Ubuntu, you can get started with Kria and take either path for production.
Along with making it easier to get started with embedded Linux, we wanted to save developers time when they don’t need to reinvent the wheel. For most vision AI use cases, you’re not solving unique problems. We and our partners have created plug-and-play Accelerated Applications. Xilinx Accelerated Applications are open-source and enable the most common AI deployment topologies (such as a multi-stream AI appliance or Smart Camera). Additionally, domain expert partners such as Aupera Technologies and Uncanny Vision have developed additional apps that you can use for a fee. All the Accelerated Applications are available via the Xilinx App Store, the industry’s first app store for vision AI.
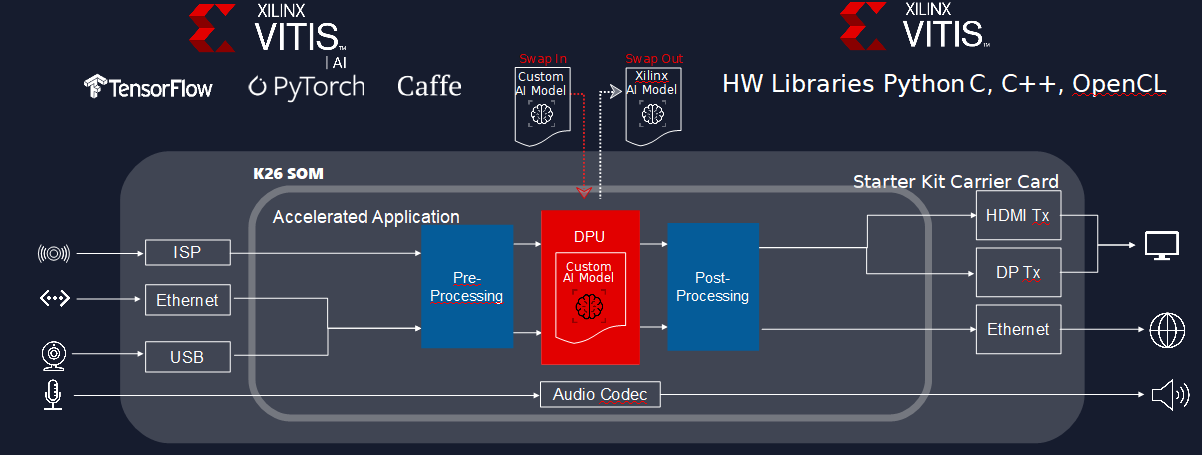
Just like with our Linux kernel options, we give our users four levels of customization when leveraging Xilinx Accelerated Applications:
- Design purely at the application software. The app itself does most of the heavy lifting, processing video data and producing vision data.
- Swap out the default AI model with a customer-trained AI model with Vitis AI. You get more control over the model, but still avoid FPGA design.
- Change the FPGA design, but in a familiar software language like Python, C, C++, or OpenCL using Xilinx’s Vitis tool. Vitis has optimized libraries like the xfOpenCV library, one of the most popular and long-standing libraries to implement vision functions such as color space conversion, rotation, and filtering.
- Fully customize the FPGA using the Xilinx Vivado tool. Obviously, this is not required, but anyone who has this expertise can take full advantage of the adaptable SoC’s flexibility.
With a modular and flexible approach, any software developer can start playing with vision AI hardware projects and get good results. We ran a test using the Uncanny Vision license plate app running on the Kria SOM and a commercial-grade competitor. Our board ran with 1.5 times the performance while consuming 33% less power per stream.
Of all the advances in computer vision AI in the last few years, we think that the most significant is the increased accessibility of vision AI hardware. Democratizing these solutions will make it easier for any developer to create something dazzling. Ready to start building vision AI applications with Kria? Here are a few links that will put you on the right path to your first development.
Next Steps:
Check out the Xilinx Kria Product Page
Download the Ubuntu image for Kria KV260 today!
Get Started with the Kria KV260 Vision AI Starter Kit