
Databases are now given an enviable amount of attention since they manage a company’s most important property: data. Just 30 years ago, most data was stored on paper, magnetic tape, or some type of disk, and as we were producing and consuming smaller amounts of data on a per capita basis, we could still efficiently store, manage, and access it.
However, data tells an entirely different story today. Smartphones have become increasingly necessary and ubiquitous. With smartphones came apps that increased the amount of data we consume and produce to levels unconceivable just 15 years ago. This has put great stress on database clusters, as they need to handle larger and larger amounts of traffic, with some top websites and services receiving billions of visits every week.
How can we handle this incredible volume of traffic when it reaches the database cluster?
The answer could be sharding. Perhaps you’ve never heard of it, or you may have dismissed it too quickly as being a legacy solution unsuitable for modern challenges. Sharding database architecture might not sound as fancy or have all the bells and whistles of other solutions, but it is certainly effective and practical.
Recently this approach has received significant new innovative contributions that have advanced sharding beyond what was imaginable not so long ago (one such example is Distributed SQL which makes sharding easy to achieve and manage). Maybe that's why it has been growing in popularity among blockchain companies looking to achieve scalability.
Database fragmentation
Databases have been around for over 50 years. You might not think there’s anything left to innovate after all that time, but database fragmentation is one of the fastest-developing verticals in the tech industry. The complexity that characterizes existing data infrastructures seems to be only getting worse.
Many modern applications end up being built on top of multiple, and often purpose-specific databases. A single application might include a relational database for storing and accessing content (e.g. PostgreSQL), an in-memory database (e.g. Redis) for content caching, a custom database such as a time-series database, and a data warehouse for analytics. Now try to imagine this happening for a business that has multiple applications, multiple divisions with their own applications, or worse, different vendors.
As mentioned above, data has become one of the most important assets for any business. Database technologies have recently seen a faster development pace, which is arguably correlated with artificial intelligence, machine learning, blockchain, and cloud technologies picking up their pace of development.
According to DB-Engines, there are more than 350 database management systems—with many more that didn’t even make the list.
According to Carnegie Mellon University’s “Database of Databases” there currently are 792 different noteworthy database management systems.
Such a large number of different database management systems (DBMS) shows the wide spectrum of possible requirements businesses may have when it comes to choosing their database management system.
For instance, a bank or financial institution might choose a relational DBMS such as SQL Server or PostgreSQL to ensure ACID (atomicity, consistency, isolation, durability) transactions for its structured data. A business that operates a massive online multiplayer game or web applications requiring sessions would generally prefer a key-value NoSQL database such as Redis. Lastly, a social media analytics business would usually choose a graph database, while an Internet of Things (IoT) business would choose a time-series database to support its sensor or network data.
If you believe that choice is good, then you’re in for a treat as more and more solutions are going to be hitting the market in the next couple of years. These solutions will be brought both by new and innovative startups, as well as more established database vendors that will release new products or enhance already established solutions.
The database market is only going to get more fragmented in the near future. Database fragmentation brings significant challenges, such as vendor technology compatibility, legacy systems’ adaptability, and replacement costs, just to name a few.
Why you need sharding
Traditional databases may struggle to handle more and more data and query traffic. The NoSQL and NewSQL concepts are very popular these days, and accordingly more and more new database products inspired by these ideas are hitting the market. But these concepts alone won’t solve the increasing data problem.
Sharding is a technique that splits data into separate rows and columns held on separate database server instances in order to distribute the traffic load. Each small table is called a shard. Some NoSQL products like Apache HBase or MongoDB have shards, and sharding architecture is built into NewSQL systems.
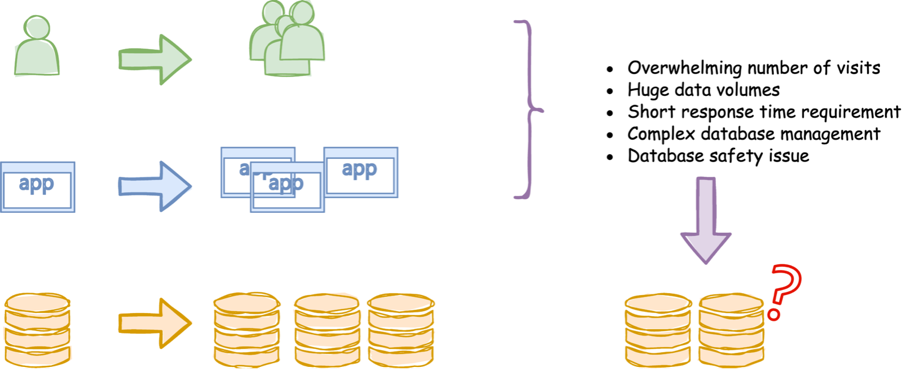
Let's look at a particular type of NewSQL architecture: sharding as it relates to the OLTP (online transaction processing) issues of today.
While there are many solutions to minimize database load, sharding has these advantages:
• Distribute data storage over many machines
• Balance traffic load around different shards easily
• Significantly improve query performance
• Scale databases without extra work
• Reuse and upgrade traditional DBMS efficiently
• Allows multiple databases to use a single server or cloud computing resources across users thanks to its support of multi-tenancy with the use of a proxy.
How to shard a database
The following is a basic workflow that will let you implement sharding for your DBMS. After discussing the setup and the foundational ideas of this technology, we’ll provide some deeper insights into a few essential aspects later.
One of the best techniques to create shards is to split the data into multiple small tables. These are also called partitions.
The original table can be divided into either vertical shards or horizontal shards; that is, either by storing one or more columns in separate tables or storing one or more rows in separate tables. These tables can be labeled ‘VS1’ for vertical shards and ‘HS1’ for flat shards. The number represents the first table or the first schema. Then 2, then 3, and so on. When taken together, these subsets of data comprise the table's original schema.
Here are the two key concepts of sharding:
• Sharding key: a specific column value that indicates which shard this row is stored in.
• Sharding algorithm: an algorithm to distribute your data to one or more shards.
Step 1: Analyze scenario query and data distribution to find sharding key and sharding algorithm
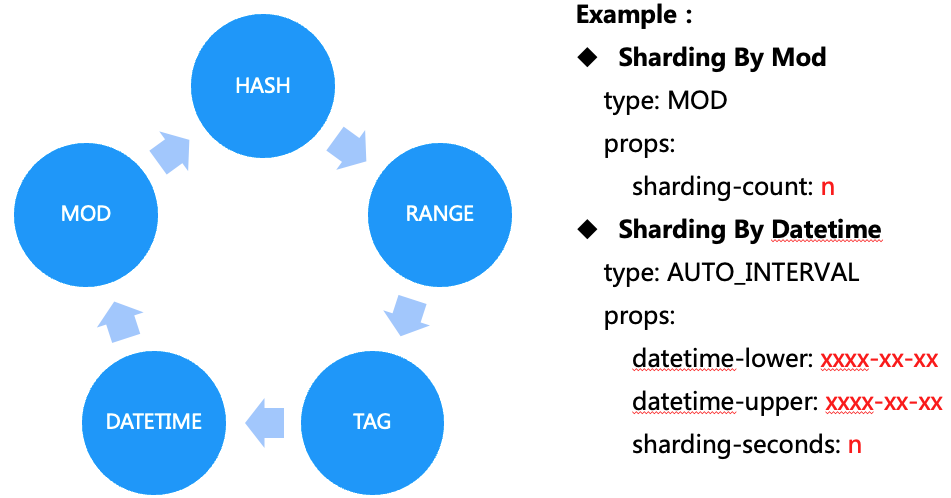
To determine which shard to store any given row, apply the sharding algorithm to the sharding key. Different sharding strategies fit different scenarios. The common strategies include:
- MOD: Short for modulo, this sends every nth row or column to a specific shard. For example, a MOD 3 algorithm would send the first, fourth, and seventh rows to the first shard, the second, fifth, and eighth rows to the second shard, and the third, sixth, and ninth rows to the third shard, and so on.
- HASH: Hash sharding evenly and randomly distributes data across shards. Every table row is placed in a shard according to a computed consistent hash on the shard column values of that row.
- RANGE: This sends specific ranges of rows or columns to individual shards.
- TAG: This sends all rows or columns that match on a specific value.
For instance, if the sharding key is “ID” and sharding algorithm is “ID modulo 2” (which splits even and odd rows), the rows will be sorted like so:

Hence what you have to do is design a fitting algorithm that uses the sharding key. Your sharding strategy will significantly impact query efficiency and future scale-out. An improper or poor sharding algorithm will always create redundant data across different shards to calculate, which ultimately causes poor overall calculation performance.
The key points to consider when deciding how to shard a database are the characteristics of the business query and the data distribution. Each database will have unique factors that affect this decision, but we can provide some example scenarios that illuminate how a good sharding algorithm efficiently distributes data.
RANGE
For instance, when sharding a table containing time-stamped log details, a RANGE sharding algorithm using the create date as the sharding key is recommended. The reason is that traditionally, people tend to query these detailed records only within a specific time range.
When using a date-time, the RANGE algorithm can cause another issue: historical records will commonly be updated less frequently, while recent records are updated and queried frequently, the majority of queries would hit the shard with the most recent records. This will result in most queries competing with each other to get the exclusive rights to update the data.
MOD
The MOD sharding algorithm can efficiently avoid this fierce competition. It splits rows by ‘shardingKey MOD shards number’. The latest rows will be split into different shards, so that the newest queries will be sent to different shards to avoid recent-rows competition. When the sharding key is a string value (and potentially sensitive to disclose), you can use the HASH algorithm to create a value that the MOD algorithm can use to distribute data to shards.
TAG
However, there are times where you may want to shard data by the value of a cell; in this case, you’ll want to use the TAG sharding algorithm. Let’s suppose that, in order to comply with GDPR regulations, you want to store all EU data on servers located in the EU. How would we operate a sharding distributed database system to answer this question? If the DBA uses the TAG sharding algorithm, rows with data from tagged countries can be sent to specific shards located in a specific country. To find out how many records are affected, our sharding database system just has to return COUNT(*) from the EU shard to answer this query: SELECT COUNT(*) FROM registrant_table WHERE region = "EU". A distributed query, which has to calculate the final result from the entire distributed system, becomes a simple single query from one shard.
There is no silver bullet for all the cases. To achieve the best possible performance, spend some time thoroughly analyzing your specific business scenario. If you’re looking to get started quickly, a distributed sharding database system will generally pick a common strategy that meets the majority of use cases.
Step 2: Migrate existing data
If you decide to implement sharding, you don’t need to migrate all of the original data into a sharding cluster. Doing so is a challenge since you’ll face the following issues:
- How to shard data while the business is running 24/7
- How to replay incremental data in the new sharding cluster
- How to compare data between the original database and the new sharding cluster
- How to find the best time to switch traffic to the new sharding cluster
However, if you do decide to migrate historical data to shards, the traditional approach is as follows:
- First, partition the historical data into the new database sharding cluster through a sharding algorithm. A program to automatically move data is recommended, which will run all of the SQL queries needed.
- Second, run a platform or a program to pull and parse the database log to understand which changes happened during the partitioning process, and apply these changes to the new sharding cluster (incremental data shards).
- Third, choose a data-check strategy to compare the data between the original database and new sharding cluster. These data-check strategies are flexible from high accuracy to a short period, or a balance between them. Whether you want to compare each cell or just check the total amount is up to you. To achieve the highest accuracy in terms of data-check strategies, comparing rows one by one will require the most effort, while comparing only the row amount of the original and new clusters will be fastest at the expense of accuracy. Other strategies, like CRC32, are achieving the balance between accuracy and speed.
Step 3: Shift traffic to a new cluster
Assuming that the above steps were completed smoothly, the next step is to switch the online traffic to your new sharding cluster. This should happen during a period when the database cluster cannot be written to so that the two datasets stay consistent and maintain optional querying—making the off-peak time a common choice for this step.
All update requests should be forbidden for distributed data consistency, but queries are allowed since they do not cause any changes in the distributed system.

The process is straightforward enough, but each part can be challenging to handle. Perform the move automatically would minimize downtime, and caution is recommended as you'll be handling valuable data.
The good news is that you’re not the first to meet these challenges. Open source projects allow us to stand on the shoulders of giants.
Apache ShardingSphere (to which I am a contributor) deals with the whole sharding process as one of its primary capabilities. It provides different sharding strategies, migrates data, reshards, and manages existing shards.
It also provides more advanced functions to help fix the issues mentioned in the next section. As an added bonus, Apache ShardingSphereit boasts an active community, which means most of your problems have already been addressed.
What constitutes good sharding
You now have an understanding of the sharding workflow and the necessary steps to perform sharding on your database, but what would good sharding look like?
Without needing to expand too much on fringe theories or context and scenario specific requirements, good sharding generally has six qualities.
It is easy to set up and to understand if there is a change in the DBA (database administrator) that is running the operation. It has high-availability, elastic scale-out capability, highly distributed system performance, observability, and low overhead for migration.
The presence of these six factors represent the ideal sharding, but it also depends on the sharding client that you’d choose.
Using sharding and replication
In addition to the core flow mentioned above, educate yourself about the items below since database scenarios are diverse and your needs will change as your application scales.
Another way to increase database performance and scalability is through replication. Replication creates duplicate database nodes that operate independently. Data written to one node would then be replicated on the other duplicate node.
Generally, both professionals and developers working on passion projects alike strive to squeeze the most out of databases to get high availability and performance—nevertheless, the architecture of sharding and replication can lead to complicated database management and routing strategy.
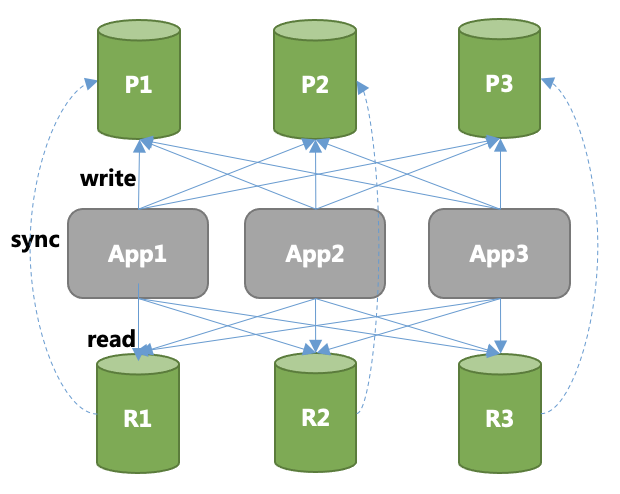
Imagine that each shard has replica nodes. The result would be something like the graph below. If one primary node has more than one replication, the situation will deteriorate for the applications visiting them.
So what's the difference between sharding and replication? As discussed above, sharding means splitting a large table into a few small ones to create many shards; on the other hand replication will create many replicas of the original table. Each replica will contain the entire data of the original (the primary node).
Sharding can help users load-balance the data existence across multiple servers to acquire the scalability, while replication will create backups of the primary database to improve the system availability. The two different architectures bring different advantages to the distributed system. Based on this reasoning, some users want to have the two capabilities together, so it is not uncommon to find a mix of the architectures leveraging sharding and replication at the same time.
As the following graph illustrates, users may want to shard one database containing enormous amounts of data across different servers, such as P1, P2, P3. Every query will also be sharded into different shards to improve the TPS or QPS of this distributed database system. However, if one of the shards crashes down, the availability will lower to 2/3. Moreover, it is time-consuming to pull up another copy of the offline version, creating a loss with grave consequences. To increase the availability of this sharding system, an efficient way is to pull up replication for each shard, that is, the primary nodes, P1, P2, P3 mentioned previously.
The existence of R1, R2, R3 illustrates the solution I explained above. When P1 is unavailable, its replication, R1, will be elevated to the primary node to serve the business. This is a safe option thought out with the idea that the smaller the outage, the smaller the loss will be for your business and services.
This idea sounds great, but the topology of this distributed sharding database system complicates the application visits. Suppose each primary node owns two replicas, then the network made of P1, P2, P3 and their six replicas will confuse and burden developers, raising questions such as: which primary node is correct for this query? how to visit one of their replicas? how to do load balancing among different replicas? Who will help me re-route this query once the primary node cannot work?
In our hypothetical scenario, developers’ responsibility is to code for business efficiency. This remarkable architecture does indeed have advantages, but is too complicated to leverage and maintain.
How to hide this complexity from the application?
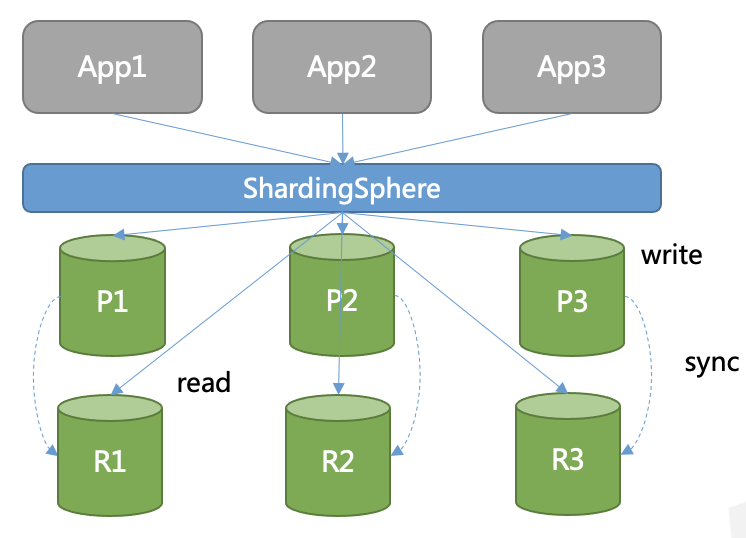
Generally there are two types of clients or access modes for users to choose from, plus a new “bonus” type of client. Sharding can either be instigated through a specialized database connection driver or by connecting your application to a proxy application that routes data.
Sidecar is the newer concept among the available modes for sharding and originated from service meshes. In simple terms, it’s a proxy instance deployed with a service to handle communications, monitoring, etc. among different services. This mode operates similarly to a sidecar attached to a motorcycle. This means that a sidecar is attached to a parent application while providing supporting features for the application.
If we use a dedicated driver or proxy instead of sidecar, it’ll act and appear as a single database server, helping users manage their database cluster. This way applications won’t be affected by these complicated visiting topologies, or have to refactor themselves to adapt to the new framework.
Conclusion and trends
Sharding is one of the ways to solve the new challenges created by the evolution of networked applications. Other solutions include DBaaS (or database in the cloud), new database architectures, or simply the old fashioned method of increasing the number of databases used for storage.
We have now gone full circle, and I hope that this piece can at least contribute to introducing you to sharding architecture, or if you had already heard of it and dismissed it as out of fashion, I hope it changes your mind.
Actually, I do not like the term fashion, as it gives me the idea of something ephemeral, that is here today and is gone tomorrow. While that is true for many things in life, especially in technology, I prefer to judge a technology by looking at its practicality, efficiency, and cost advantages for a specific scenario.
All of this to say that it’s always good to be open to new trends, without forgetting that sometimes existing and established technologies could be the best possible solution.
References
[1] https://db.cs.cmu.edu/papers/2016/pavlo-newsql-sigmodrec2016.pdf
[2] https://github.com/apache/shardingsphere
[3] https://opensource.com/article/21/9/distsql
Author
Juan Pan | Trista
SphereEx Co-Founder & CTO, AWS Data Hero, Apache Member, Apache ShardingSphere PMC, Mentor of China Mulan openSource community.
Ex Senior DBA at JD Technology, she was responsible for the design and development of JD Digital Science and Technology’s intelligent database platform. She now focuses on distributed databases & middleware ecosystems, and the open source community.
Her commitment to open source is significant. She is the No. 2 contributor at Apache ShardingSphere, recipient of the “2020 China Open-Source Pioneer” and "2021 China OSCAR Open Source Pioneer" awards, and she is frequently invited to speak and share her insights at relevant conferences in the fields of database & database architecture.
Bio: https://tristazero.github.io
GitHub: https://github.com/tristaZero
Twitter: https://twitter.com/tristaZero
LinkedIn: https://www.linkedin.com/in/panjuan