
Despite years of hype—and some incredible technological breakthroughs—many people think of chatbots as an even more frustrating replacement for offshore call centers. I’m the CEO of a chatbot company, and even I can’t name a single chatbot that’s great.
I don’t think that was anybody’s game plan for chatbots. It certainly wasn’t my game plan when I built the first version of Botpress in 2015.
So how did we get here? And will chatbots ever live up to the hype? I wouldn’t be writing this if I didn’t believe the answer was yes, but don’t take my word for it. Let’s explore what’s happening with the technology together and see if you agree.
Why do chatbots suck?
Despite all of the advances in natural language processing (NLP), most chatbots only use the most basic form of it. They parse conversations through intent classification—trying to organize everything a customer might say into a preconceived bucket based on the intention of their inquiry.
For example, “Hello, I would like to change my billing address” might be classified into the change billing address bucket—and the chatbot would reply accordingly.
While this can handle some common requests, it’s difficult to provide and maintain a satisfying customer experience. To classify a customer conversation, the conversation designer must anticipate the correct intent and add all possible conversation triggers for those intents.
Even if those intents have been well anticipated with good trigger phrases, the chatbot can only deliver on a single intent. Conversations with real people can be messy and full of nuance, and people often want multiple things at once. Intent-based classification just finds the intent that a conversation resembles and pushes the canned response for that bucket. The chatbot might know the answer to the question, “Can I change my billing address so it matches other profiles on my account?”, but have the information under account settings, not address change.
In my view, this hardly qualifies as AI—it’s closer to a search function. You’re not having a conversation; you’re interacting with a conversation machine, playing a text adventure like Zork. This function is error-prone and a lot of work to build, but more importantly, it’s fundamentally wrong. Here’s an example of why:
Imagine an image classification program that identifies animals and furniture. You feed it a pile of labeled images—this is an animal, this is furniture—and it learns to recognize them. Suppose at some point you need to differentiate bears from dogs as well as couches from chairs. Now you have to relabel everything to be more specific. Now suppose the program encounters a bear skin on a couch—that’s multiple matches, so now you have a conflict.
Ideally, a chatbot should be able to ingest a user’s query, understand what the user is trying to achieve, and then help the user achieve their objective—either by taking action or by generating a helpful, human-sounding response.
This isn’t what today’s chatbots deliver. Instead, they are glorified Q&A bots that classify queries and issue a canned response. Recent advances in several areas of AI, however, offer opportunities for producing something better.
What are chatbots capable of, and why aren’t we there yet?
Today, there are better, “intentless” ways to design chatbots. They rely on advances in AI, Machine Learning (ML), and NLP fields such as information retrieval, question answering, natural language understanding (NLU), and natural language generation (NLG).
Soon, chatbots will leverage these advances to deliver a customer experience that far exceeds today’s rudimentary Q&A bots. Imagine a chatbot that can:
- Understand complex queries with all the messy nuance of human speech.
- Generate human-like answers to complex queries by drawing from a knowledge base.
- Use natural language to query structured tables, such as a flight information database.
- Generate human-sounding phrases that match a specific dialect or brand tone.
While a chatbot with these features would provide fantastic user experiences, upgrading from existing versions takes more effort than most organizations are willing to bear. They’ve already invested years in building intent-based chatbots, including training datasets and writing canned responses.
Ideally, developers would pull the data out of these chatbots and build it into newer, more sophisticated bots. Unfortunately, this isn’t possible. Chatbot datasets are created and maintained to match the specific way in which a bot works. A dataset trained against a particular set of intent classifications is no use to a newer, intentless chatbot that uses more advanced NLP concepts. As a result, an organization that wants to implement a more advanced chatbot would have to rebuild it—and its dataset—from scratch.
Why would it be worth rebuilding? NLP is a rapidly evolving field, and changes are coming that will help chatbots live up to their promise. Let me give you some concrete examples.
Four NLP advances that will help chatbots live up to the hype
NLP models are essentially a chatbot’s “brain.”
Intent-based chatbots use basic NLP models that match user inputs against a dataset of labeled examples and try to categorize them. However, in recent years, we’ve seen huge advances in NLP models and related technologies that will profoundly impact chatbots’ ability to interpret and understand user queries. These include:
Support for larger NLP models
Since 2018, NLP models have grown hyper-exponentially. The graph below shows how quickly the number of parameters in modern NLP models have grown
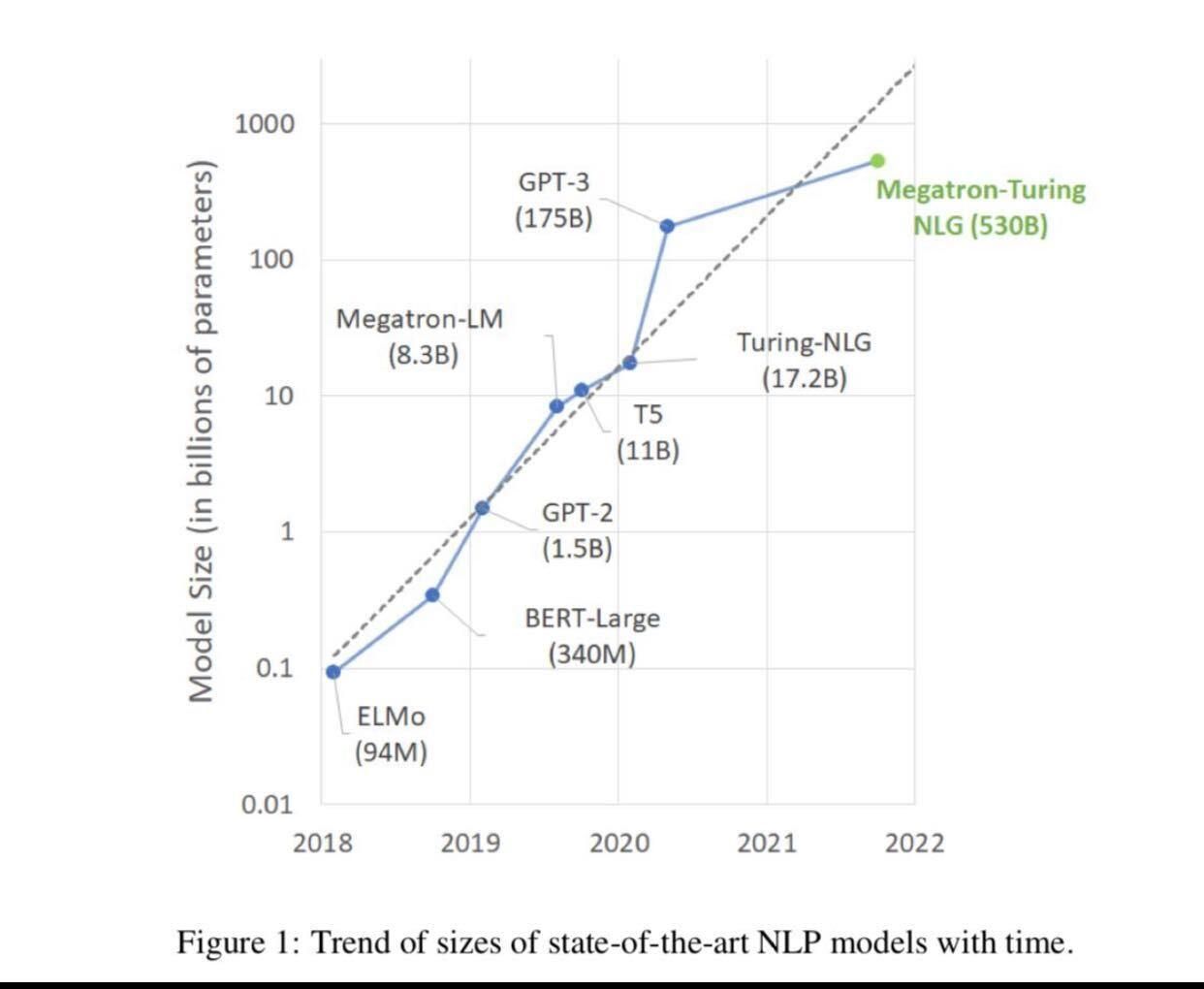
You can think of a parameter as comparable to a single synapse within a human brain. Nvidia estimates that by 2023 it will have developed a model that matches the average human brain parameter-for-synapse at 100 trillion parameters. To support these massive models, Nvidia just announce their Hopper engine, which can train these massive models up to six times faster.
While model size isn’t the only factor in measuring the intelligence of an NLP model (see the controversy surrounding several existing trillion-plus parameter models), it’s undoubtedly important. The more parameters an NLP model can understand, the greater the odds it will be able to decipher and interpret user queries—particularly when they are complicated or include more than one intent.
Tooling
The evolution of frameworks and libraries such as PyTorch, TensorFlow, and others makes it faster and easier to build powerful learning models. Recent versions have made it simpler to create complex models and run deterministic model training.
These toolsets were initially developed by world leaders in AI/ML—Pytorch was created by Facebook’s AI Research Lab (FAIR) and TensorFlow by the Google Brain team—and have subsequently been made open-source. These projects are actively maintained and provide proven resources that can save years of development time, allowing teams to build sophisticated chatbots without needing advanced AI, ML, and NLP skills.
Since then, new tools have further accelerated the power of NLP models. For those wanting the power of these tools without the burden of configuring them, MLOps platforms like Weights & Biases provide a full service platform for model optimization, training, and experiment tracking. As the ML field becomes more sophisticated, more powerful tooling will come along.
Parallel computing hardware
Whereas a CPU provides general purpose processing for any given function, GPUs evolved to process a large number of simple mathematical transformations in parallel. This massively parallel computation capability make it ideal for NLP. Specialized hardware such as TPUs and NPUs/AI accelerators have taken these capabilities and created specialized hardware for ML and AI applications.
As hardware grows in power, it becomes faster and cheaper to build and operate large NLP models. For those of us who aren’t shelling out the money for these powerful chipsets, many cloud providers are offering compute time on their own specialized servers.
Datasets
NLP datasets have grown exponentially, partly due to the open-sourcing of commercially built and trained datasets by companies like Microsoft, Google, and Facebook. These datasets are a huge asset when building NLP models, as they contain the highest volume of user queries ever assembled. New communities like HuggingFace have arisen to share effective models with the larger community.
To see the effect of these datasets, look no further than SQuAD, the Stanford Question Answering Database. When SQuAD was first released in 2016, it seemed an impossible task to build an NLP model that could score well against SQuAD. Today, this task considered easy, and many models achieve very high accuracy.
As a result, new test datasets challenge NLP model creators. There’s SQuAD 2.0, which was meant to be a more difficult version of the original, but even that is becoming easy for current models. New datasets like GLUE and SuperGLUE now offer multi-sentence challenges to give cutting edge NLP models a challenge.
Should you build or buy?
In hearing about all these advances in AI, ML, NLP, and related technologies, you may think it’s time to chuck out your chatbot and build a new one. You’re probably right. But there are fundamentally two solutions for development teams:
- Build a chatbot from the ground up to incorporate today’s superior technologies.
- Purchase a toolset that abstracts the difficult NLP side of things—ideally with some additional features—and build from there.
This is the classic “build or buy” dilemma, but in this case, the answer is simpler than you might think.
For a smaller development team with limited resources, building a chatbot from scratch to incorporate the latest AI, ML, and NLP concepts requires great talent and a lot of work. Skills in these areas are hard (and expensive) to come by, and most developers would prefer not to spend years acquiring them.
What about development teams at larger organizations with resources to hire data scientists and AI/ML/NLP specialists? I believe it still likely isn’t worthwhile to build from scratch.
Imagine a big bank with a dedicated team working on its latest chatbot, including five data scientists working on a custom NLP pipeline. The project takes perhaps 18 months to produce a usable chatbot—but by that time, advances in open-source tooling and resources have already caught up with anything new the team has built. As a result, there’s no discernible ROI from the project compared to working with a commercially available toolset.
Worse, because the chatbot relies on a custom NLP pipeline, there’s no simple way to incorporate further advances in NLP or related technologies. Doing so will require considerable effort, further reducing the project’s ROI.
I confess I am biased, but I honestly believe that building, maintaining, and updating NLP models is simply too difficult, too resource-intensive, and too slow to be worthwhile for most teams. It would be like building your own cloud infrastructure as a startup, rather than piggybacking on a big provider with cutting edge tooling and near infinite scale.
What’s the alternative?
A toolset like Botpress can abstract the NLP side of things and provide an IDE for developers to build chatbots without hiring or learning new skills—or building the tooling they need from scratch. This can provide a series of benefits for chatbot projects:
- Significantly reduced development time.
- Easy upgrades to the latest NLP technologies without significant reworking.
- Less effort to maintain chatbots as updates are automatic.
Best of all, developers can focus on building and improving the experience and functionality of their own software—not learning AI/ML/NLP.
Start building chatbots today
If I’ve piqued your interest in building chatbots, you can start right now. At Botpress, we provide an open-source developer platform you can download and run locally in under a minute.
To get started, visit our chatbot developer page. For a walkthrough on how to install the platform and build your first chatbot, refer to our getting started with Botpress guide.
You can also test out the live demo of our latest product—a radically new method of creating knowledge-based, “intentless” chatbots, called OpenBook, announced this week.
The Stack Overflow blog is committed to publishing interesting articles by developers, for developers. From time to time that means working with companies that are also clients of Stack Overflow’s through our advertising, talent, or teams business. When we publish work from clients, we’ll identify it as Partner Content with tags and by including this disclaimer at the bottom.