
Note: This is an updated document based on parts of two older articles.
Event-driven architecture is a paradigm that allows low coupling between services—particularly in a microservices architecture. It removes the need for services to actively know about each other and query each other using synchronous API's. This allows us to reduce latency (avoiding "microservice hell") and make it easier to change services in isolation.
In a nutshell, this approach uses a message broker which manages a number of topics (also known as logs or streams). One service produces to a topic, while other services consume from the topic.
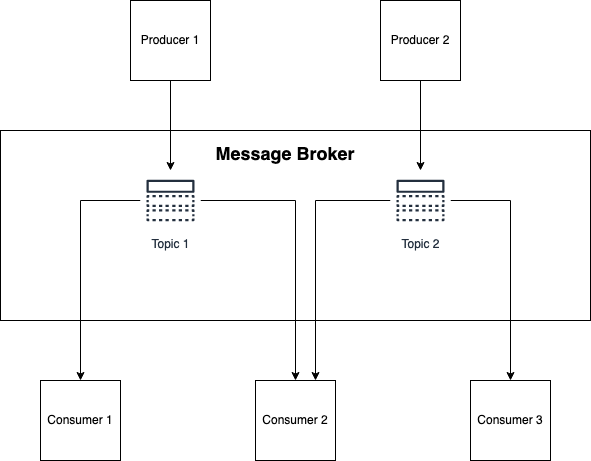
Each of these little black boxes will likely want to have some of its own state in order to do its work. (Stateless services do exist, but for something to be truly stateless, there are a number of tradeoffs and pain points you need to address, and often reflect a more complex microservice architecture. More often than not, these architectures could be described as a "distributed big ball of mud.")
Our goal in introducing a message broker is to reduce dependencies between these boxes. This means that if service A has some information, service B shouldn't ask service A for that information directly—service A will publish that information into a topic. Service B can then consume the information and save it to its own data store or do some work with it.
Ignoring the more technical challenges with this approach on the producing or consuming side (such as marrying the production of messages with database transactions), what kind of data is useful to send through topics? How do we easily and safely move our stored data from one service to another? And what do our topics and services look like in different situations?
Let's start answering those questions.
Kafkaesque
For the purposes of this discussion, I will be using Apache Kafka as the technology underlying the message broker in question. Besides the advantages in things like its ability to scale, recover and process things quickly, Kafka has some properties that make its topics more useful than a standard simple queue or message bus:
- Messages have keys associated with them. These keys can be used in compaction strategies (which deletes all messages with the same key except for the latest one). This is useful in upsert topics, which I will discuss more below.
- Messages are only deleted by compaction or retention settings (e.g. delete any message that's older than seven days)—they aren't deleted manually or as soon as they're seen.
- Any number of consumers (or rather, consumer groups) can read from the same topic, and they each manage their own offsets.
The upshot of these properties is that messages stay permanently in the topic—or until they're cleaned up by retention or compaction—and act as a record of truth.
Kafka also allows you to structure your data. You can send any kind of byte data through Kafka, but it is strongly recommended to use a schema framework such as Avro or Protobuf. I'll go one step further and recommend that every message in a topic should use the same schema. There are numerous benefits to this, but that is a topic for another article.
With these properties and strongly structured data, we can design topics for each of the following situations:
- Entity topics - "this is the current state of X"
- Event topics - "X happened"
- Request and response topics" - "Please do X" → "X has been done"
Entity topics: The source of truth
An entity topic is one of the most helpful ways to use Kafka to ferry data between services. Entity topics report the current state of an object.
As an example, let's say you have a Customers service which knows all about all the customers that your company works with. In a synchronous world, you'd have that service set up an API so that all other services that need to know about a customer would have to query it. Using Kafka, you instead have that service publish to a Customers topic, which all other services consume from.
Consumer services can dump this data directly into their own database. The cool thing about this paradigm is that each service can store the data however they like. They can discard fields or columns they don't care about or map them to different data structures or representations. Most importantly, each service owns its own data. If your Orders service needs to know about customers, it doesn't need to ask for it—it already has it right there in its own database.

One of the properties of Kafka—the fact that every message has a corresponding key—is very effective in enabling this type of topic. You set the key to whatever identifier you need for that customer—an ID of some kind. Then you can rely on Kafka to make sure that eventually, you're only going to see a single record for the customer with that ID: the most up-to-date version of the customer.
Another property—partitioning—ensures that order is guaranteed for any message with the same key. This means that you can never consume messages out of order, so any time you see that customer, you know for a fact that it's the latest version of that customer you've yet seen.
Consumers can upsert the customer into the database—insert it if it doesn't exist, update it if it does. Kafka even has a convention to signify deletions: a message with a key but a null payload, also known as a tombstone. This indicates that the record should be deleted. Due to compaction, all non-tombstone messages will eventually disappear, leaving nothing but the deletion record (and that can be auto-compacted as well).
Because entity topics represent an external view into state owned by an existing service, you can export as little information as you need. You can always enhance that information later on by adding fields to the exported data and re-publishing it. (Deleting fields is harder, since you'd have to follow up with all consumers of the data to see if they're actually using those fields.)
Entity topics are great, but come with one large caveat: They provide eventual consistency. Because topics are asynchronous, you are never guaranteed that what you have in your database matches exactly with the producer's database—it can be seconds or even minutes out of date if your broker is experiencing slowdown. If you:
- need your data to be one hundred percent accurate at the time of usage, or
- you need to collate information from more than one source and both sources have links that must match perfectly,
then using asynchronous processing is likely not what you want: you need to rely on good old API queries.
Event topics: Record of fact
Event topics are a completely different beast from entity topics. Event topics indicate that a particular thing happened. Rather than providing the most up-to-date version of a particular piece of data, event topics provide a "dumb" record of the things that happened to it.
(Note that I am not going to cover event sourcing, which uses events to reconstruct the state of a record. I find that pattern to be of niche use in specific contexts, and I've never used it in production.)
Events are primarily used for two reasons:
- Collect information about user or application behavior. This often powers analytics and manual or automated decision making.
- Fire off some task or function when a particular event occurs. This is the basis of a choreography architecture—a decentralized design where each system only knows its own inputs.
As opposed to entity topics, event topics can only capture what happens at the exact moment it happens. You can't arbitrarily add information to it because that information may have changed. For example, if you want to later add a customer's address to an order event, you'd really need to cross-reference the address at the time the event happened, which is usually far more work than it's worth.
To restate that, entity topics should have as few fields as possible, since it's relatively easy to add them and hard to delete them. Conversely, event topics should have as many fields as you might think are eventually necessary, because you can't append information after the fact.
Event topics don't need message keys because they don't represent an update to the same object. They should be partitioned correctly, though, because you'll likely want to work on events that happened to the same record in order.
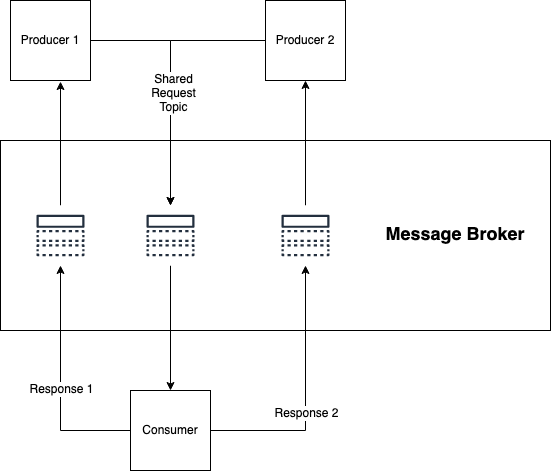
Request and response topics: Async API
Request and response topics are more or less what they sound like:
- A client sends a request message through a topic to a consumer;
- The consumer performs some action, then returns a response message through a topic back to the consumer.
This pattern is a little less generally useful than the previous two. In general, this pattern creates an orchestration architecture, where a service explicitly tells other services what to do. There are a couple of reasons why you might want to use topics to power this instead of synchronous APIs:
- You want to keep the low coupling between services that a message broker gives us. If the service that's doing the work ever changes, the producing service doesn't need to know about it, since it's just firing a request into a topic rather than directly asking a service.
- The task takes a long time to finish, to the point where a synchronous request would often time out. In this case, you may decide to make use of the response topic but still make your request synchronously.
- You're already using a message broker for most of your communication and want to make use of the existing schema enforcement and backwards compatibility that are automatically supported by the tools used with Kafka.
One of the downsides of this pattern is that you don't get an immediate response as to whether the request was successful—or at least successfully received. Often in a "do some action" situation, this information is really helpful to know immediately, especially if it's in a logical transaction of some kind.
If you do use this pattern, you'd likely change up the normal pattern of Kafka architecture and have multiple producers with a single consumer. In this case the consumer owns the schema, not the producer, which is a non-obvious way of working.
Joining and enhancing topics
A common use case for microservices is to join two topics together or enhance an existing topic with additional information. At Flipp, for example, we may have a topic that contains product information and another topic that adds a category to the product based on some input.
There are existing tools that help with these use cases, such as Kafka Streams. These have their uses, but there are many pitfalls involved with using them:
- Your topics must have the same key schema. Any change to the key schema may require re-partitioning, which can be expensive.
- Your topics should be roughly of equal throughput—if either topic has much larger or has many more messages than the other, you are stuck with the worst of both topics. You might end up joining a "small, fast" topic (lots of updates, small messages) with a "large, slow" one (fewer updates, bigger messages) and have to output a "large, fast" topic, which can destroy your downstream services.
- You are essentially doubling your data usage every time you transform one topic into another one. Although you get the advantages of a less stateful service, you pay the price in load on your brokers and yet another link in a chain that can be broken.
- The internals of these services can be opaque and difficult to understand. For example, by default they use Kafka itself as its internal state, resulting in more strain on the message broker and lots of temporary topics.
At Flipp, we have started moving away from using Kafka Streams and prefer using partial writes to data stores. If topics have to be joined, we use a tool like Deimos to make it easy to dump everything to a local database and then produce them again using whatever schema and cadence makes sense.
Conclusion
Message brokers and topics are a rich way to grow your architecture, reduce dependencies, and increase safety and scalability. Designing your systems and topics is a non-trivial task, and I've presented some patterns that I've found useful. Like everything else, they aren't meant to be used in every single situation, but there are quite a lot of cases where using them will make for a more robust, performant and maintainable architecture.