
Handling data is an essential part of a programmer's daily routine. Typically, data is organized into arrays and objects, stored externally in SQL or document-based databases, or encoded in text or binary files. Machine learning is all about data and works best when a large amount of data is used. Therefore, data and data processing play a central role in designing and building a machine learning pipeline. However, data formats are often very different from classes and objects, and terms such as vectors, matrices, and tensors are used. In this article, we explain why machine learning requires an efficient data pipeline and data formats. We explain the basic data structures from scalars to n-dimensional tensors and give examples of processing different data types.
Practical code examples are given in an accompanying workbook. In the following notebook you find actual snippets on data processing in Python.
Why data structures are different in ML
When we talk about data for machine learning, we refer to the training data used to build and test models. The design goals for machine learning data structures are different from those of classical programming. Often, the raw data consists of tabular data, images or videos, text or audio stored on a local disk or in a cloud bucket. Machine learning frameworks cannot directly consume this data as it is often encoded (for example, as a JPG or MP4), contains additional information and cannot be processed efficiently. Performance matters a lot in machine learning, and training data is inferred hundreds and thousands of times by a model during training. Machine learning applications are trained and used by (multiple) GPUs synchronizing data via high performance internal networks and pipes. All this requires an optimized data format that can handle different types of data.
Design goals for ML data structures
- Suitable for high-performance processing and computations
- Efficient synchronization between different GPUs and machines
- Flexible for different types of data
Fortunately, most of the complex tasks are handled by machine learning frameworks such as Tensorflow or PyTorch. Nevertheless, it is important to understand the following fundamentals in order to design efficient data pipelines.
Scalars, vectors, and matrices
In our flexible data format, we start as simple as possible, with a single element: a scalar. Scalars refer to single data points; for example, the amount of blue in an RGB pixel or a token representation for a letter or word. In programming languages such as Java or Python, scalars are single integers, doubles, or booleans.
When building a list from scalars and the list has a fixed order (directed), it is called a vector. Vectors are very common in classic programming and are often used as tuples, arrays, or lists. With a vector, we can already represent a complete RGB pixel (values for red, green, and blue) or a sentence (each word or part of a word is represented by an integer token).
In the next step, we add a second dimension by stacking multiple vectors to a matrix. Matrices are two-dimensional and comparable to a table, consisting of rows and columns. By this, we can efficiently store grayscale images, multiple documents of a text, or an audio file with multiple channels.
Processing matrices on GPUs is extremely efficient and the mathematics behind calculating matrices is well-researched (although reinforcement models have only recently found even more efficient multiplication algorithms). Matrices are the foundation for any data structure in modern machine learning.
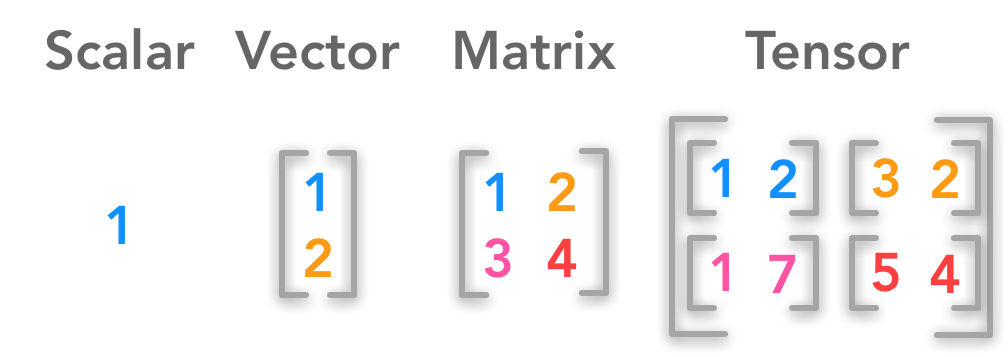
Tensors and their properties
A tensor describes an n-dimensional array of data. Often, the so-called rank or the number of axes refer to the dimensions. A rank-0 tensor is a scalar, a rank-1 tensor is a vector, and matrices refer to a rank-2 tensor.
N-dimensional tensors are ideal for machine learning applications as they provide fast access to data by a quick lookup and without decoding or further processing. Due to the well-known matrix mathematics, computing with tensors is very efficient and allows the training of deep learning models that require the computation of millions and billions of parameters. Many tensor operations such as addition, subtraction, the Hadamard transform, dot product, and many more are efficiently implemented in standard machine learning libraries.
Storing data in the tensor format comes with a notable time/memory tradeoff, which is not uncommon in computer science. Storing encoded and compressed data reduces the required disk space to a minimum. To access the data, it must be decoded and decompressed, which requires computational effort. For single files, this is mostly irrelevant and the advantages of fast transfer and low storage requirements outweigh the access time. However, when training deep learning models, the data is accessed frequently, and algorithms fundamental for machine learning models (such as convolution for image analysis) cannot operate on encoded data.
A well-encoded 320 x 213 pixel JPG image requires only around 13 KB of storage, whereas a float32 tensor of the same image data utilizes about 798 KB of memory, an increase of 6100%.

320 x 213 color pixels in JPG only require 13 KB of storage
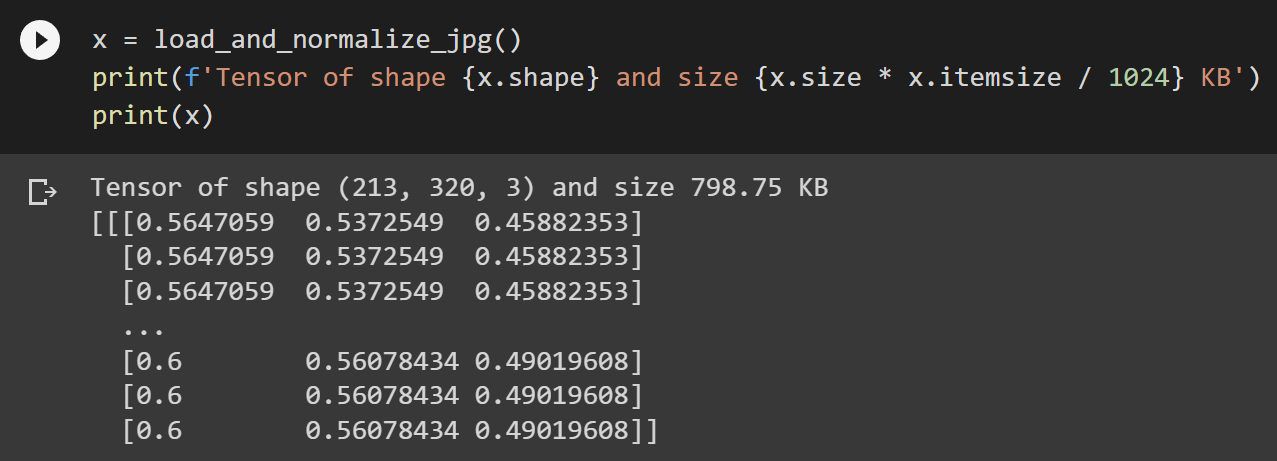
same image data stored in a 320 x 213 x 3 float32 tensor weights 798 KB
To combine the advantages of both, special data loader modules have been designed to preprocess the data for optimized usage in the tensor format.
Additional optimizations such as batching and sparse data formats exist to handle the large amounts of data. Nevertheless, hardware requirements for (training) deep learning models remain high.
Decisions for your data pipeline
Taking into account the above insights on specialized data structures, let’s have a look at the decisions one has to make when designing a data pipeline.
First of all, even before starting to develop any machine learning models, make sure to store any relevant data structured and accessible. For image data, this usually means some cloud storage with additional metadata attached to the files or stored in a separate database. For our data loader it is important to have a structured list of the relevant files and their attached labels. This metadata will be used to download and preprocess the files. Keep in mind that at some point there can be multiple machines working on the same datasets in parallel, so they all need parallel access. For the training procedure, we want to cache the data on the training machine directly to avoid high transaction times and costs, as we frequently access the data. Even if you don’t plan to train a machine learning model (yet), it might be worth it to think about storing relevant data and potentially labels that could be useful for supervised learning later.
In the next step, we convert the data into a useful tensor format. The tensor rank depends on the used data type (see examples in the workbook) and, more surprisingly, on the problem definition. It’s important to define if the model should interpret data (for example a sentence) independent from others or what parts of the data are related to each other. A batch usually consists of a number of independent samples. The batch size is flexible and can be reduced down to a single sample at inference/testing time. The type of the tensor also depends on the data type and normalization methods (pixels can be represented as integers from 0 to 255 or as a floating number from 0 to 1).
For smaller problems, it might be possible to load the full dataset into memory (tensor format) and perform the training on this data source with the advantage of faster data loading during training and a low CPU load. However, for most practical problems this is rarely possible, as even standard datasets easily surpass hundreds of gigabytes. For those cases, asynchronous data loaders can work as a thread on the CPU and prepare the data in memory. This is a continuous process so it works even if the total amount of memory is smaller than the full dataset.
Dataset decisions:
- structured format
- accessible storage
- labels and metadata
- tensor format (rank, batch size, type, normalization)
- loading data from disk to memory, parallelization
Scalars, vectors, matrices, and especially tensors are the basic building blocks of any machine learning dataset. Training a model starts with building a relevant dataset and data processing pipeline. This article provided an overview of optimized data structures and explained some of the relevant aspects of the tensor format. Hopefully the discussed decisions for designing data pipelines can serve as a starting point for more detailed insights into the topic of data processing in machine learning.
Visit the additional notebook for practical examples of how to process different types of data.