
After the work described in the previous blog post, Stack Overflow for Teams now runs on its own domain: stackoverflowteams.com. All Teams have been migrated and customers have been informed of configuration changes they would need to make on their end to keep everything working.
As a reminder, here’s the phases we planned to move our Teams instances:
- Phase I: Move Stack Overflow for Teams from stackoverflow.com to stackoverflowteams.com
- Phase II: Decouple Teams and stackoverflow.com infrastructure within the data center
- Phase III: Build a cloud environment in Azure as a read-only replica while the datacenter remains as primary
- Phase IV: Switch the Azure environment to be the primary environment customers use
- Phase V: Remove the link to the on-premises datacenter
With Phase I completed, we now had a cosmetic separation. The next step is making sure there is nothing behind the scenes that depends on the stackoverflow.com DMZ. This meant we needed to remove the dependency on the Sites database and contain all Teams infrastructure and data within the TFZ which is all part of Phase II.
Breaking up is hard to do
The biggest thing we still shared with the DMZ was the Sites database. This database is the foundation of our multi-tenancy. But that’s not all. The DMZ still received incoming requests and forwarded those to the TFZ for all Teams-related business. And our deployment processes were shared with stackoverflow.com and based on our older TeamCity process.
We first worked on getting a brand new isolated Teams environment deployed to a dev environment. We created some extra servers for this in the TFZ and built a deployment process in Octopus Deploy. This gave us a new, self-contained clean environment that we could test and helped us with moving away from TeamCity.
Once we had our dev environment working and tested, we knew the new Teams environment would be able to function. Now we had to come up with a plan to split the DMZ and the TFZ in production.
We came up with a script that we could follow to perform 27 steps ranging touching everything from IIS settings to application deployments , all required to fully split the infrastructure and start running Teams from the TFZ. This meant database steps such as getting a copy of the Sites database over to the TFZ, application steps such as turning off all Teams related code in the old DMZ, deploying the full app to the TFZ, and load balancer changes to make sure requests no longer were handled by the DMZ.
Practice makes perfect
Once we had a first version of the script, we started practicing this on our dev environment. Optimistic as I was, I thought this would take us an hour. After four hours we decided to give up, lick our wounds, and figure out what went wrong.
The issue we saw was that in our ‘new’ environment, newly asked questions were only shown in the overview page after five minutes. In our old environment, this was almost instantaneous. We knew this had to be a configuration issue from the migration because a brand new deployed environment did show the questions immediately.
Long story short, we made a configuration mistake where we used an incorrect Redis key prefix to signal from the web app to TagEngine that a new question was available and should be added to the overview page. Once we figured this out, we ran a new practice round and things went much smoother.
We then scheduled the real thing for March 11th, 2023. Thanks to our practice rounds, the real switch over went off without any issues.
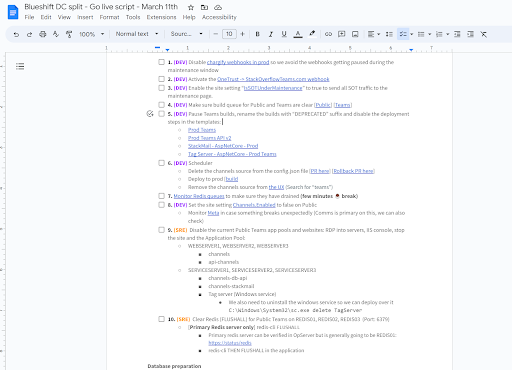
A part of the script for March 11th with in total 27 steps to split Teams and Stack Overflow
This completed Phase II. Phase III was to take this fully-isolated environment from the datacenter and migrate it into Azure. We decided to do a lift and shift because we didn’t want to risk changing both the infrastructure and the application while migrating to the cloud. Instead, we decided to keep things as similar as possible and start modernizing once we are in Azure.
What do we have to move?
We have a couple of key elements running Teams in our datacenter that we had to lift and shift to Azure:
- Windows Server virtual machines running the web application and all supporting services
- Redis for caching
- ElasticSearch for our search functionality
- Fastly and HAProxy for load balancing
- SQL Server for our databases
We started with thinking about how we could map all these components to Azure while changing as little as possible but also making changes where it made sense. The following sections go through all these elements and discusses how we build them in Azure.
The web tier
Virtual machines are annoying. They require patching for OS updates and often have the tendency to start diverging the moment you deploy them. On-premises, we have an in-house tool called Patcher that we use in conjunction with Ansible to continuously patch our servers. We use Puppet for server configuration. We wanted to improve upon this and get rid of the manually deployed and configured servers.
So we decided to invest in building VM base images with Packer that we could easily update and deploy.
Packer is a tool from HashiCorp. Packer standardizes and automates the process of building system and container images. The resulting images included all latest OS patches, IIS configuration, .NET runtime and certificates that we would need for every web VM. This helped us deprecate Patcher, Ansible, and Puppet. Instead of updating an existing machine, we build a new image and replaced the machine with the new version,
Deployment happens to a Virtual Machine Scale Set. VMSS is an easy way to provision multiple VMs based on the image we created with Packer. It supports rolling deployments and monitoring of the VMs allowing us to safely replace VMs when a new image becomes available.
We run four Standard_D32ds_v5 VMs in production. These have 32 cores and 128GB of memory. We need this amount of memory because of all the caching we do and because TagServer requires a lot of memory.
On each of these VMs, we run six applications:
- Web app
- API v2 and v3
- Scheduler (internal tool used to execute scheduled tasks)
- TeamsDbApi (internal API that manages the databases for all Teams)
- StackMail (internal tool to manage all email we send)
- TagServer (a unique custom, high-performance index of Teams questions)
The base image is immutable, so whenever we want to apply OS updates or other changes we create new VMs based on this new image and then delete the old VMs once everything is live. The applications are deployed on top of these not-so-immutable images.
The reason we don’t bake the app into the image is speed. Building and deploying a new image can easily take a couple of hours. Doing an app deploy on a running VM takes minutes.
If we do a rolling update of all VMs to replace their base image, we need to make sure that the applications are fully deployed and functioning before moving on. The next diagram shows the process we use for this. The VMSS creates a new VM based on the VM image which contains the Octopus agent. Once that agent comes online, it automatically triggers a deployment of all applications. The VMSS then checks the health endpoint, which is handled by the main web application. This endpoint checks if all other applications are done deploying and only then signals that the full VM is healthy.
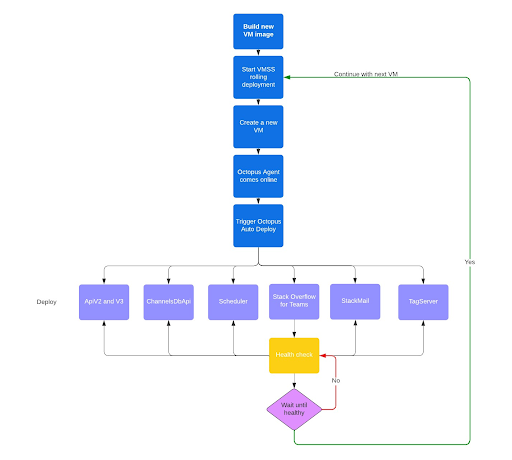
Now imagine that one of the applications fails to start. The VMSS will stop the rolling deployments, leaving one VM unhealthy and all other VMs healthy. The unhealthy VM won’t receive traffic from Azure Application Gateway and customers won’t notice this.
If we do a regular application deployment, we start with a VM that has all applications already deployed. Our Octopus pipeline does a rolling deployment over all VMs. For each VM, the pipeline first runs a script that marks the specific app for that specific VM as unhealthy in the Application Gateway. Once that’s done, the application is deployed and we wait until the application starts showing healthy in the Application Gateway. Only then we move on to the next VM. This way, we can be sure we never take all VMs offline with a failing deployment.
We know this process is complex and can easily fail. For the lift and shift, however, this was good enough and we plan on improving this further in the future, maybe by moving to containers.
Application Gateway and Fastly
On-premises we use Fastly and HAProxy for load balancing. We decided to keep Fastly but also start leveraging Azure Application Gateway to manage external and internal traffic. App Gateway is a layer 7 load balancer that allows us to manage traffic to all the apps installed on the various VMs in the VMSS. Azure Application Gateway is a cloud native offering we don’t have to manage ourselves making our lives a little easier.
We decided to deploy two Azure Application Gateways: one for internal and one for external communication. The App Gateway for external traffic is linked to Fastly. The two App Gateways are deployed to two different subnets so we fully control access to who can reach which application and communication between apps.
The public App Gateway is fronted by Fastly. Fastly knows about our vanity domains (stackoverflowteams.com and api.stackoverflowteams.com), while the application gateways only know about the internal URLs for Teams instances. This allows us to easily spin up environments that are fully self contained without having to touch Fastly. Fastly gives us control over routing/redirection, as well as things like request/header manipulation, certificate management, failover between regions, and request logging and observability. In addition, we use mutual TLS (mTLS) between Fastly and the Azure Application Gateway to ensure traffic entering the App Gateways is coming solely from Fastly.
Our on-premises Fastly configuration was relatively “monolithic”—we have a single config pushed to multiple services, which uses rules to determine which part of the configuration applies to which service. For our new cloud config for Phase III, we split out each workload into its own service in Fastly (main application, API, etc) to allow us greater flexibility in applying rules targeting only a single service without impacting others. This way, we can keep the Application Gateway as flat as possible and deploy multiple instances of our environment next to each other without any conflicts or overlap.
The Application Gateway monitors the health of all its backends. The following screenshot shows one of our developer environments that has all the internal applications deployed to a VMSS with two VMs.
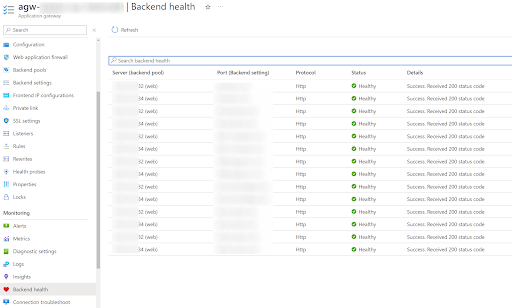
You can see how the Application Gateway checks each backend's health so it knows where it can route traffic.
Elastic and Redis
Our applications make heavy use of caching. On-premises, we install and manage Redis ourselves on a bunch of Linux servers. In Azure, we opted to use Azure Cache for Redis. This is a fully-managed service that we don’t have to upgrade or maintain. We did make sure that every Redis instance has a Private Link network endpoint so we can remove all public access and make sure we never accidentally expose our cache to the public internet. But beyond that, our days of fiddling with Redis settings were over.
Elastic was a bit more complicated. Just as we did for Redis, we wanted to use a fully managed service: ElasticCloud. Now this worked really well for all our test environments. However, when we started loading more data, we ran into issues where ElasticCloud would become unresponsive and master nodes randomly failed and didn’t come back up.
We decided to move away from ElasticCloud and instead deploy an Azure Kubernetes Service with our own Elastic deployment using Elastic Operator. This deployment model gave us more insight and visibility into what was happening, which helped us detect the performance root cause—an issue with a single Elastic API endpoint—and fix it. The issue we had originated from the way we use aliases. We create a filtered alias per Team and each query to Elastic is forced to specify the alias. This way, no customer could ever query data from another customer. However, the huge number of aliases was the cause for our performance issues. Once we figured this out, a quick configuration change to allow more aliases fixed our issues.
SQL Server
On-premises, we ran SQL Server installed on a VM in an availability group that spanned our two on-premises data centers. Each data center had two nodes, with a primary in one data center, and three total secondaries. Our application runs in read-write mode in the same region as the primary replica, sending read-only queries to the secondary node inside the same region, with all other queries going to the primary node. The other region is used solely for disaster recovery.
We have the main Sites database, and then dozens of databases that each contain ~1,000 Teams. To get this data into Azure, we had to extend our availability group to include SQL Servers deployed in Azure. This prevented us from running something like Azure SQL Database or Managed Instances. Instead we had to use manually configured SQL Server VMs.
Once the data started flowing, we could deploy our production environment in Azure as read-only. The SQL Servers in Azure were both read-only and the application turns off all routes that can edit data.
Now, testing a read-only environment is not very exciting, but being able to view a Team and a list of questions already shows that a lot of our components are deployed and configured successfully!
In addition to the manually installed and configured SQL Servers in Azure, we also wanted additional environments to test new infrastructure or application changes and to run automated tests. To support this, we’ve extended our infrastructure deployment to support Azure SQL Database. The advantage of Azure SQL Database is that we can deploy and configure all the required databases in a fully automated way.
This allows us to have what we call ephemeral environments. These environments are created for a specific purpose and, if we no longer need them, we can easily destroy them.
One such purpose is our Quality Engineering environment where we run nightly automated Mabl tests against all Teams features. On-premises, this would have cost us a lot of work to configure the servers and install the application. In Azure, all it took was a PR to add a new environment and an Octopus deploy to roll out the infra and app!
What we ended up with
Combining the new web VMs, Azure Application Gateway, Fastly, Redis, Elastic, and SQL Server completed our Phase III: Build a cloud environment in Azure as a read-only replica while the data center remains as primary.
The following diagram shows what our final Azure environment looks like.
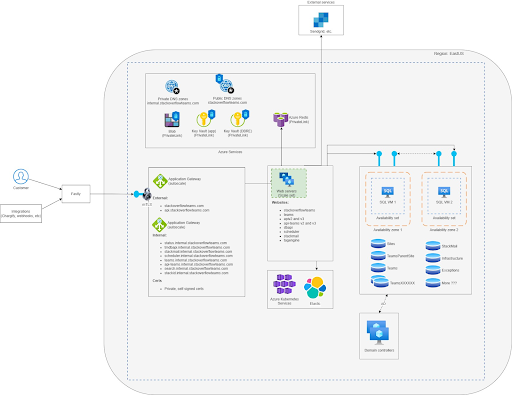
Failing over and cutting the cord
Now that we have a fully-functional Azure environment running Stack Overflow for Teams in read-only mode, it was time to move to Phase IV and make this new environment our primary read/write environment and actually start serving customers from Azure.
There are two main steps in this failover:
- Fastly rebuild
- Database failover
We had a previous version of the Teams service in Fastly, which leveraged a monolithic config shared with other applications. For this effort, we elected to build the code anew to take advantage of lessons we've learned over the years from managing applications in the Fastly CDN, as well as adding in best practice configurations going forward (mTLS, automatic LetsEncrypt certificates, etc).
We also had to fail over the database availability group. The on-premises servers were switched to read-only and the Azure servers became read/write. This is where we hit a big problem: the failover repeatedly timed out due to network latency. After several tries, we decided to force the Azure nodes to become primary and make the on-premises nodes unavailable. This allowed us to bring the app up in read/write mode in Azure, but of course this is not what we envisioned. Once Azure was primary, we restored the databases to a single node in the data center and re-joined that node to the availability group. This let us resume syncing all data to the data center in case something went wrong with our Azure environment and we wanted to fail back.
Now that Azure ran as primary with on-premises as secondary (completing Phase IV), it was time to bring an additional Azure region (West US) online and make that the secondary environment. Because of our infrastructure-as-code deployment processes and all the automation we have in place, it was very easy to bring the extra Azure environment online. Once the database servers were configured and the data was synced, we could access Stack Overflow for Teams as read-only running in West US.
Finally, the moment came to cut the cord between Azure and on-premises. We blocked all communication through firewall rules, removed the remaining on-premises node from the AG, and decommissioned all on-premises web servers and SQL Server instances running Teams, completing Phase V.
And then we were done 🥳
What’s next?
All in all, moving Teams to Azure took almost two years but, finally, we are done! Stack Overflow for Teams runs in Azure without any dependencies on the on-premises datacenter. Now, of course, this is not where we stop.
As you’ve learned throughout these blog posts, we did a lift and shift and deliberately decided to not adopt cloud native elements yet (except Azure Redis, which just worked).
One issue we are seeing is the network performance between East US and West US for our SQL Server availability group. After much research and discussions with Microsoft, we’ve found the problem to occur when we domain join the SQL Server VMs. We want to move away from virtual machines, so we’re now investigating options to move to Azure SQL Database.
Azure SQL Database would remove all the manual maintenance of the SQL Server VMs and allows us to much easier configure high availability across multiple Azure regions. We do need to figure out how to get our data into Azure SQL Database and optimize for performance and cost.
We also want to move away from VMs for our web servers; we want to move to containers. We already have the AKS cluster for Elastic and we’re looking to move apps to containers one by one until we can remove the VMs.
And who knows what’s next after that.
If you have comments or questions please reach out!