
At Stack Overflow, we understand the central role search plays in helping technologists solve their problems, so we're constantly striving to improve the way you find the information you need. Today, we're excited to share details about our latest experiment that aims to make your search results in Stack Overflow for Teams Enterprise even more relevant and useful.
What's new?
As part of our ongoing journey to improve search functionality, which we first launched in January with our Improved Search initiative, we're introducing an ML-powered reranking system that will refine the order of search results. We know you want the most relevant content at the top of your search results when using our Search Bar, API, or Slack/Microsoft Teams integrations. In fact, our data shows that 88% of clicks happen within the first 10 results. Through this experiment, we will help ensure that the most relevant answers appear higher up in the search results listing so you can find the best answers faster.
How will this affect you?
As a user, you may notice subtle but positive changes in your search experience:
- More relevant results at the top of the list
- Improved context-based ranking based on your specific query
- Enhanced performance of our OverflowAI features, which rely on top search results
This experiment is designed to be non-intrusive, and we're starting small to ensure the best possible outcome for our users.
The journey of continuous improvement
Improved Search is not a one-time initiative—it's a commitment that requires continuous investment in data science, machine learning, and software engineering. This reranking experiment is just the first step in a series of planned search relevance improvements and experiments.
Our commitment to you
As we roll out this experiment, we want to assure you that:
- We're starting conservatively with a phased rollout strategy.
- We'll be closely monitoring various metrics to ensure a positive impact.
- Your privacy and data security remain our top priority. There will be no changes to how your data is stored.
We're excited about the potential improvements this experiment could bring to your Stack Overflow For Teams Enterprise experience. Stay tuned for future updates as we continue to refine and enhance our search capabilities.
For the technically curious: a deeper dive
If you're interested in the technical aspects of our experiment, here's a more detailed look at what's happening behind the scenes.
The technology: Cross-encoder reranker
We're implementing a cross-encoder reranker, specifically the `cross-encoder/ms-marco-MiniLM-L-6-v2` model. This model has been fine-tuned on the MS Marco Passage Ranking task, a large-scale information retrieval corpus built from real user queries on Bing. This gives us a solid baseline to work with, as it's designed to understand the nuanced relationships between search queries and potential results.
Why a reranker?
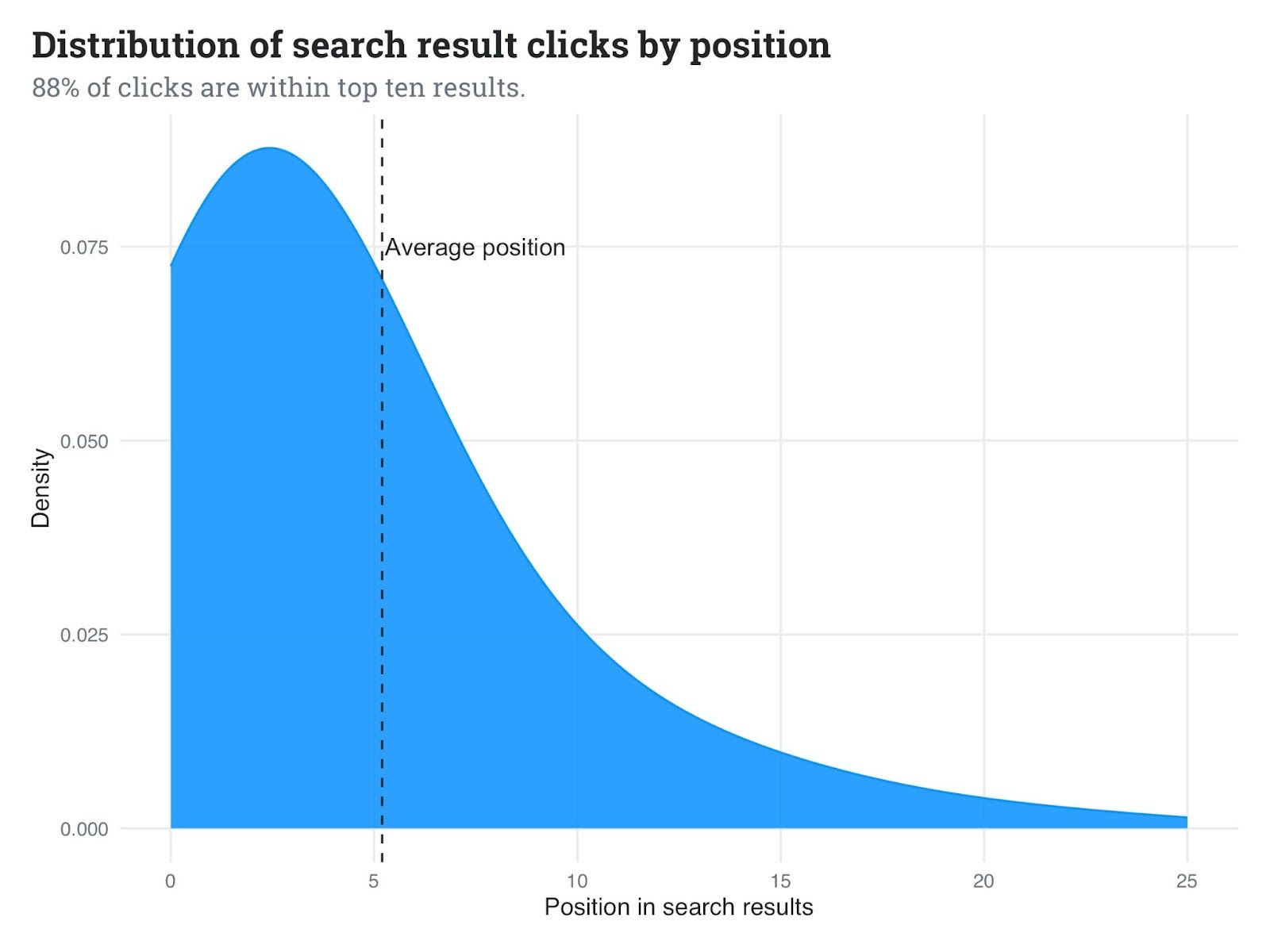
Our data shows that 88% of clicks happen within the first 10 results. In aggregate, we find that our customers are clicking approximately the 6th result on average. By improving the order within this crucial set, we can significantly enhance the search experience and the performance of OverflowAI, our AI-driven features. We also know that customers of our OverflowAI product depend on the top three results to power many of those features. Therefore, we're focusing our reranking efforts on just these top 10 results retrieved by our hybrid search algorithm.
Hypothesis
Implementation of the reranking system will increase customer’s ability to find content which they will find higher in their results and more likely to click into.
Performance metrics
In open benchmarks, this model has shown impressive improvements in Mean Reciprocal Rank (MRR) compared to a baseline of lexical search using BM25 on the MS Marco dataset.
- Baseline (BM25): 17.29 MRR@10
- Cross-encoder model: 39.01 MRR@10
However, it's important to note that these numbers reflect performance on the dataset the model was fine-tuned on. In our specific use case, with our customers' private and unique data, we expect more modest improvements. Many factors can influence actual performance in a real-world setting, so we also use an internal dataset for offline evaluations.
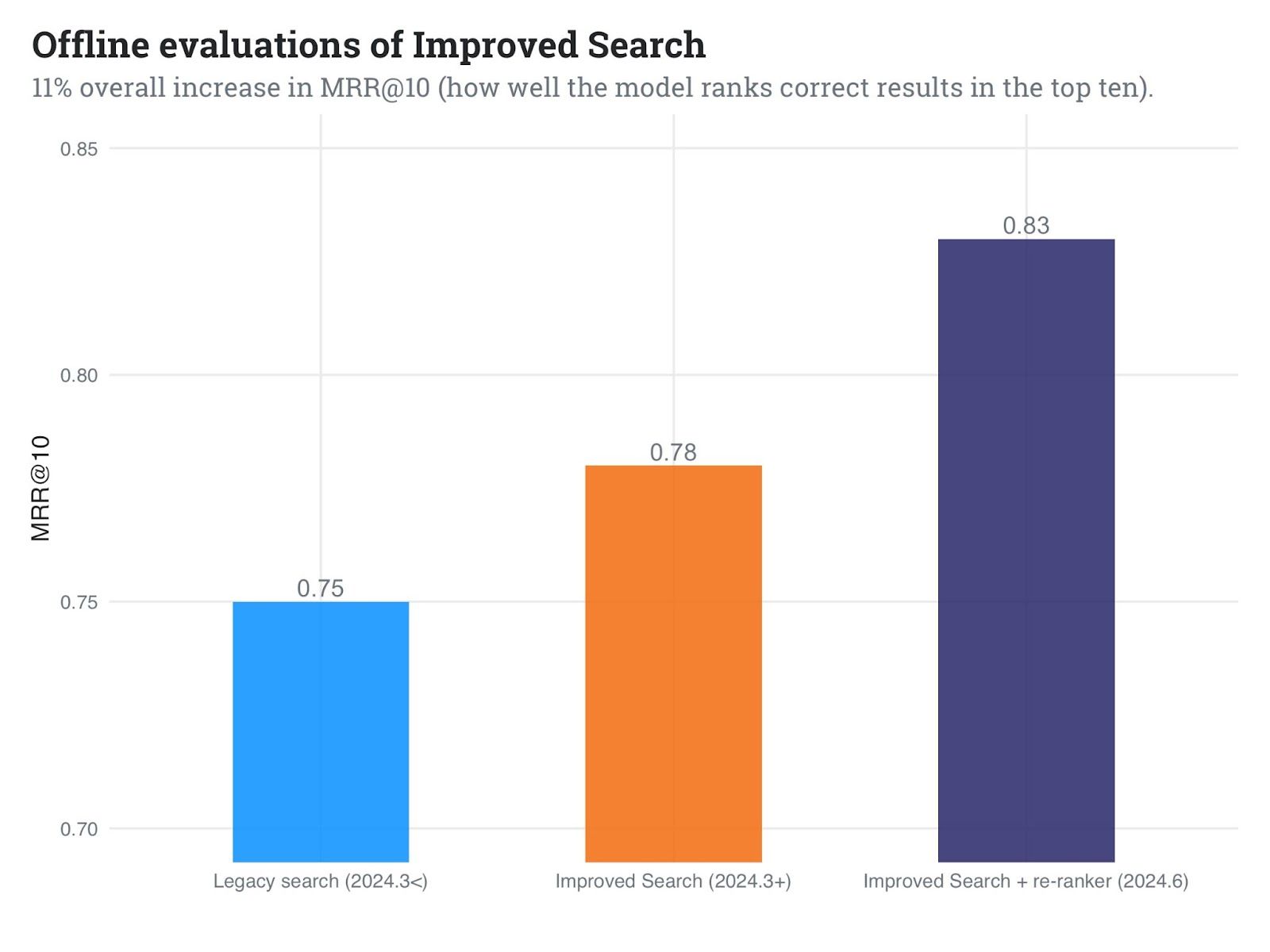
In our internal tests, we've observed promising results:
- Approximately 6% improvement in MRR compared to our first implementation of Improved Search
- 11% improvement in MRR compared to our legacy search implementation
During the live experiment, we'll be monitoring several key metrics:
- Click-Through Rate (CTR)
- Latency
- Ranking of clicked results
- Relevance scores of clicked results vs. remaining retrieved results
Technical implementation and optimization
We've been preparing for scale from the ground up. To optimize performance and scalability while maintaining accuracy, we've employed ONNX Runtime. In our local experiments, this optimization has allowed us to:
- Reduce model latency by approximately half
- Select more cost-efficient machines for deployment
These optimizations should help us scale the experiment without causing costs to skyrocket. However, it's worth noting that these results are from local experiments and may differ in our production environment.
Rollout strategy
We're taking a cautious approach to ensure minimal disruption:
- Initial A/B testing with a subset of Enterprise user traffic
- Gradual increase based on performance and user feedback
- Ability to quickly adjust or disable the experiment if needed
Data privacy and security
It's important to note that while we're collecting performance metrics, we're committed to maintaining the highest standards of data privacy. No sensitive user data is or will be collected during this experiment.
Results
As we observe the metrics, the data will either confirm or reject our hypothesis. If successful, we will promote the reranking system in its current form as a permanent fixture in our search system. If unsuccessful, we will learn from the data and analyze how to re-approach this problem. In either case, we will come back to you with the results so you can be assured that we are committed to transparency and continuous improvement.
What's next?
As we gather data and insights from this experiment, we'll plan our next steps in the search improvement journey. Stay tuned for future blog updates that will keep you informed about the impacts, lessons learned, and next steps.