
This post is the second in a series focused on the importance of human-centered sources of knowledge as LLMs transform the information landscape. The first post discusses the changing state of the internet and the related transitions in business models that emerged from that.
To be explicit, we know that attribution also matters to our community and Stack Overflow. Beyond Creative Commons licensing or credit given to the author or knowledge source, we know it builds trust. As we’ve outlined in our earlier post, the entire AI ecosystem is at risk without trust.
At Stack Overflow, attribution is non-negotiable. As part of this belief and our commitment to socially responsible AI, all contracts Stack Overflow signs with OverflowAPI partners must include an attribution requirement. All products based on models that consume public Stack data must provide attribution back to the highest-relevance posts that influenced the summary given by the model. Investments by API partners into community content should drive towards funding the growth and health of the community and its content. To this end, partners work with us because they want the Stack Exchange Community to be bought into their use of community content, not just for licensing alone: their reputation with developers matters, and they understand that attribution of Stack Overflow data alone is not enough to safeguard this reputation.
Listening to the developer community
In our 2024 Stack Overflow Developer Survey, we found that the gap between the use of AI and trust in its output continues to widen: 76% of all respondents are using or planning to use AI tools, up from 70% in 2023, while AI’s favorability rating decreased from 77% last year to 72%. Only 43% of developers say that they trust the accuracy of AI tools, and 31% of developers remain skeptical. The heart of all of this? Well, the top three ethical issues related to AI developers are concerned with are AI's potential to circulate misinformation (79%), missing or incorrect attribution for sources of data (65%), and bias that does not represent a diversity of viewpoints (50%).
Pressures from within the technology community and the larger society drive LLM developers to consider their impact on the data sources used to generate answers. This has created an urgency around data procurement focused on high-quality training data that is better than what is publicly available. The race by hundreds of companies to produce their own LLM models and integrate them into many products is driving a highly competitive environment. As LLM providers focus more on enterprise customers, multiple levels of data governance are required; corporate customers are much less accepting of lapses in accuracy (vs. individual consumers) and demand accountability for the information provided by models and the security of their data.
With the need for more trust in AI-generated content, it is critical to credit the author/subject matter expert and the larger community who created and curated the content shared by an LLM. This also ensures LLMs use the most relevant and up-to-date information and content, ultimately presenting the Rosetta Stone needed by a model to build trust in sources and resulting decisions.
All of our OverflowAPI partners have enabled attribution through retrieval augmented generation (RAG). For those who may not be familiar with it, retrieval augmented generation is an AI framework that combines generative large language models (LLMs) with traditional information retrieval systems to update answers with the latest knowledge in real time (without requiring re-training models). This is because generative AI technologies are powerful but limited by what they “know” or “the data they have been trained on.” RAG helps solve this by pairing information retrieval with carefully designed system prompts that enable LLMs to provide relevant, contextual, and up-to-date information from an external source. In instances involving domain-specific knowledge (like industry acronyms), RAG can drastically improve the accuracy of an LLM's responses.
LLM users can use RAG to generate content from trusted, proprietary sources, allowing them to quickly and repeatedly generate up-to-date and relevant text. An example could be prompting your LLM to write good quality C# code by feeding it a specific example from your code base. RAG also reduces risk by grounding an LLM's response in trusted facts that the user identifies explicitly.
If you've interacted with a chatbot that knows about recent events, is aware of user-specific information, or has a deeper understanding of a particular subject, you've likely interacted with RAG without realizing it.
This technology is evolving rapidly, so it’s a good reminder for us all to question what we think we know is possible regarding what LLMs can do in terms of attribution. Recent developments showing the “thought process” behind LLM responses may open other avenues for attribution and source disclosure. As these new avenues come online and legal standards evolve, we will continue to develop our approach and standards for partners concerning attribution.
What does attribution look like?
Given the importance of attribution, we would like to provide a few examples of various products that consume and expose Stack Exchange community knowledge. We will continue to share other examples as they become public.
Google, for example, highlights knowledge in Google’s Gemini Cloud Assist, which is currently being tested internally at Google and set to be released by the end of 2024.
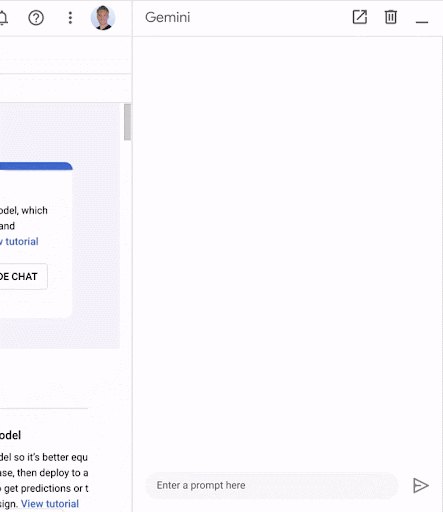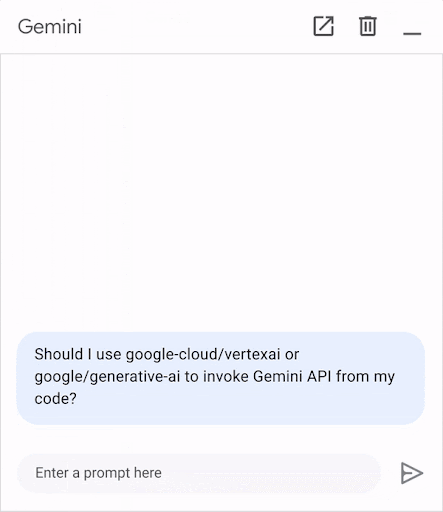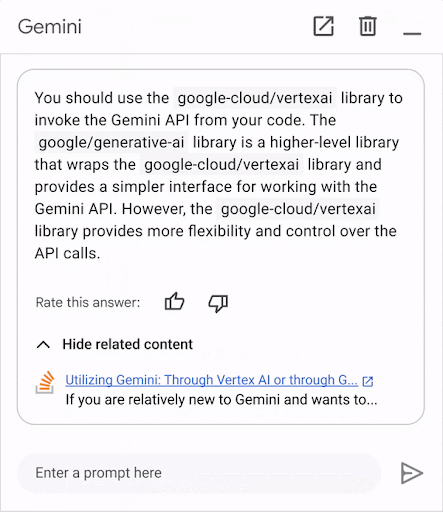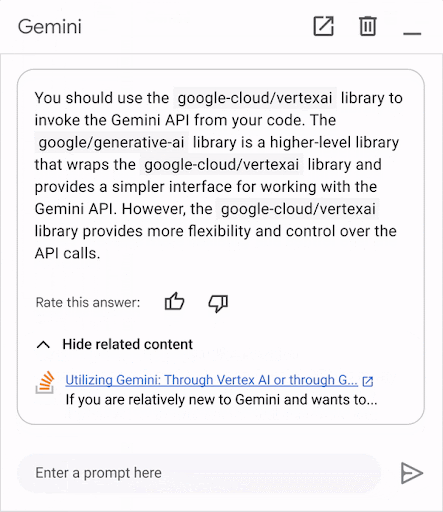
As Google expands its partnership with us, it is increasing its thinking about other entry points for its integrations with us: expect to see attribution of Stack Overflow content in other Google products, interfaces, and services.
OpenAI is surfacing Stack results in ChatGPT conversations about a variety of coding topics, helping drive recognition of, attribution, and traffic back to our community:

SearchGPT, OpenAI’s search prototype, also surfaces Stack links in conversational responses and in its search results, providing numerous links back to our community:

These integrations represent a common theme: attributing content is not just an advantage for authors and community members. It also represents an opportunity to serve developers better: Code-gen tools like these, especially with embedded AI, have great potential and utility for developers. Still, they don’t have all the answers, creating a new problem for developers: What do you do when your LLM doesn't have a sufficient answer to your customers’ questions? Stack Overflow can help. Finally, it enables Stack partners to support compliance with community licensing under Creative Commons, a necessity for any Stack Exchange community content user.
Links like these provide an entry point for developers to go deeper into the world of Stack Community knowledge, drive traffic back to communities, and enable developers to solve complex problems that AI doesn’t have the answer to. Creating these feedback loops allows developers, the community, and API partners to benefit from developing and curating community knowledge. Over the coming months and years, we’ll embed these feedback loops into our products and services to enable communities and organizations to leverage knowledge-as-a-service while building trust in community content and its validity. And more importantly, we will build confidence in and with our communities as we use partner investment in these integrations to directly invest in building the tools and systems that drive community health. Please read through our community product strategy and roadmap series for more information, including an update from our Community Products team that will be coming later this week.