
Looking back a few decades, search-based navigation of knowledge was rocky for knowledge producers. Google Knowledge Graph reminded us that many seekers were happy to find the quick answer, but the benefits still rolled back to the source platforms. These search platforms made money from high-scale audiences via advertising, affiliates, performance marketing, etc. Companies that survived and thrived adjusted to this by leveraging meta-information and links, which enabled them to generate traffic; an entire industry built around optimization and performance of search-enabled marketing emerged. The Interdependent relationship between search providers and content producers grew with the advent of sitemaps and search engine optimization roles, which created more value for them and the users trying to find the information they needed.
A few years later, cloud computing provided a more performant and cost-effective way to deliver technology's benefits, giving rise to the concept of infrastructure-as-a-service. These technologies drove an even more rapid transformation; businesses that survived adopted cloud computing by default to lower costs for themselves and their customers. Cloud-based services then gave way to cloud-based products, and the rise and proliferation of software-as-a-service business models emerged, creating entirely new categories of businesses.
About ten years ago, new interfaces and interaction methods, such as Siri and other virtual assistants, evolved, as did early chatbots. While this new, more conversational technology felt innovative, unlike previous transformations, the business models that served it had no underlying change. These agents were still interfaces for interacting with knowledge platforms, ultimately sourcing links to those reputable resources, with conventional search under the hood. These forces began to change recently when AI chatbots and agents became the newest interfaces to surface knowledge—separating content (and audiences) from platforms into interfaces that attempt to summarize indexed community content. These agents present synthesized knowledge as if they are the owner or creator of that knowledge without attributing the actual authors; this prevents the interchange of traffic back to the sources, sometimes completely obscuring them. With this, the internet is changing once again: it is becoming more fragmented as the separation between sources of knowledge and how users interact with that knowledge grows.
At the same time, new problems are emerging:

- Answers are not knowledge: What do you do when your LLM doesn't have a sufficient answer for your customers’ questions? Despite the massive gains LLMs have made in the past 18 months, they often lack two key things: answers to more complex queries or context to why an answer might work in one scenario or environment but not another.
- LLM brain drain: AI agents give answers but do not reinforce the creation and maintenance of new knowledge, nor can they consider how the future might look different from today. AI’s end users then famously complain about “cutoff dates,” or the date in history when the LLM's knowledge is cut off. How do LLMs keep training and improving if humans stop sharing original thought?
- Developers lack trust in AI tools: We face a scenario where a user’s trust in community knowledge is more crucial than ever. Still, the technology products that deliver the knowledge leave that trust and credibility out of the loop. An increasing lack of confidence in LLM-generated output risks every component of this system that’s forming.
Preserving and highlighting the feedback loops with the humans generating the knowledge is essential for continued knowledge creation and trust in these new tools.
The good news is that some LLM creators are engaging increasingly with knowledge-generating communities to stay current. They know the LLM brain drain risk and understand that there is no substitute for human knowledge, even with synthetic data. Put in classic economic terms: there is ever-greater demand, and communities, platforms, and publishers have the supply. With this, a new set of Internet business models is emerging: in this new Internet era, businesses that understand that human knowledge and its creation, curation, and validation are as valuable (or more so) than the awareness or engagement of users themselves. As a result, Stack Overflow and the larger Stack Exchange community need to be direct about our needs and ensure GenAI providers partner with us on this new forefront. We are entering a new economy where knowledge-as-a-service will power the future.
This new set of business models depends on a community of creators that progressively create new and relevant content, domain-specific, high-quality, validated, and trustworthy data. It also leans heavily on ethical, responsible use of data for community good and reinvestment in the communities that develop and curate these knowledge bases. These businesses will be successful if they can deploy and structure their content for consumption at scale, identify and support end-product use cases for their content by 3rd parties, and deliver ROI for enterprises. They must also establish a network of enterprise relationships and procure and deploy relevant datasets to build and optimize for end users (in Stack’s case, developers). In the long term, they will sustain these businesses with their ability to create new data sources, protect their existing ones from unpermitted commercial use and abuse, and continue macroeconomics conducive to selling access to data or building tools based on knowledge, content, and data.
So, what do we mean by knowledge-as-a-service? It is simple for Stack Overflow: Developers and LLM providers rely on Stack’s platform to access highly trusted, validated, and up-to-date technical content—the knowledge store. The knowledge store supports user and data paths to access existing knowledge on demand while accelerating the creation and validation of new knowledge. The Knowledge Store is continuously growing, improving, and evolving at the speed of technical innovation, reinforcing user and data loops and solving for “LLM brain drain” and “Answers are not knowledge" problems. Knowledge-as-a-service establishes Stack Overflow’s public knowledge store as the most authoritative and trusted knowledge store in technology. It also pushes forward a future that preserves the openness of community content: it enables communities to continue to share knowledge while redirecting LLM providers and AI product developers to have pathways for fair and responsible use of community content.
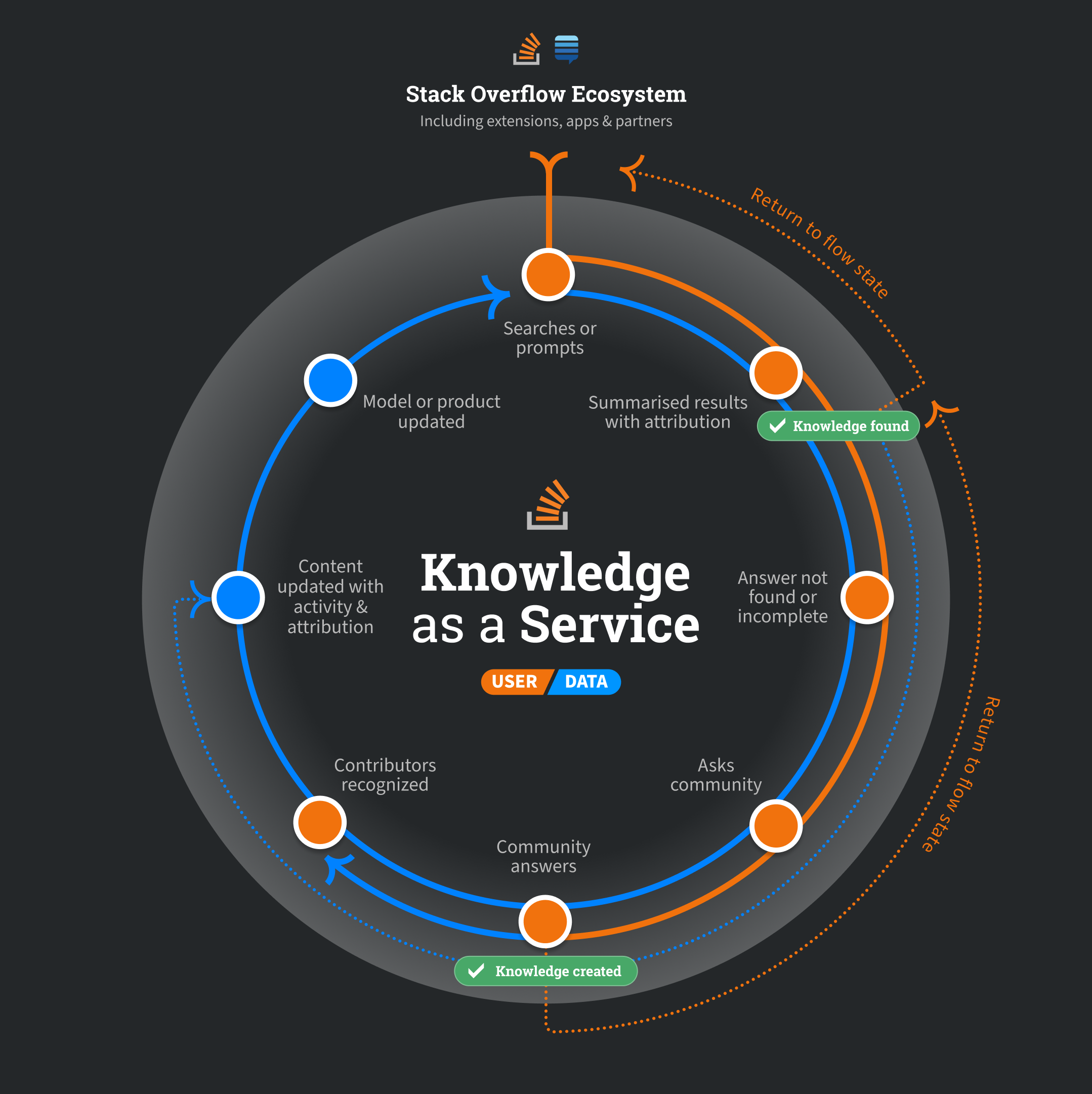
When enterprises combine this public knowledge store with their knowledge, this newly expanded corpus and its access and maintenance become knowledge-as-a-service, a reinforcing feedback loop that enables developers and technologists within those organizations to innovate and drive value for organizations more efficiently and effectively. With these changing forces, pursuing a knowledge-as-a-service strategy isn’t just opportunistic for Stack Overflow; it is the best opportunity for long-term success and viability. Knowledge-as-a-service establishes sustainable financial growth in a market where historical monetization, like advertising and software as a service, is increasingly under pressure across content and community products.
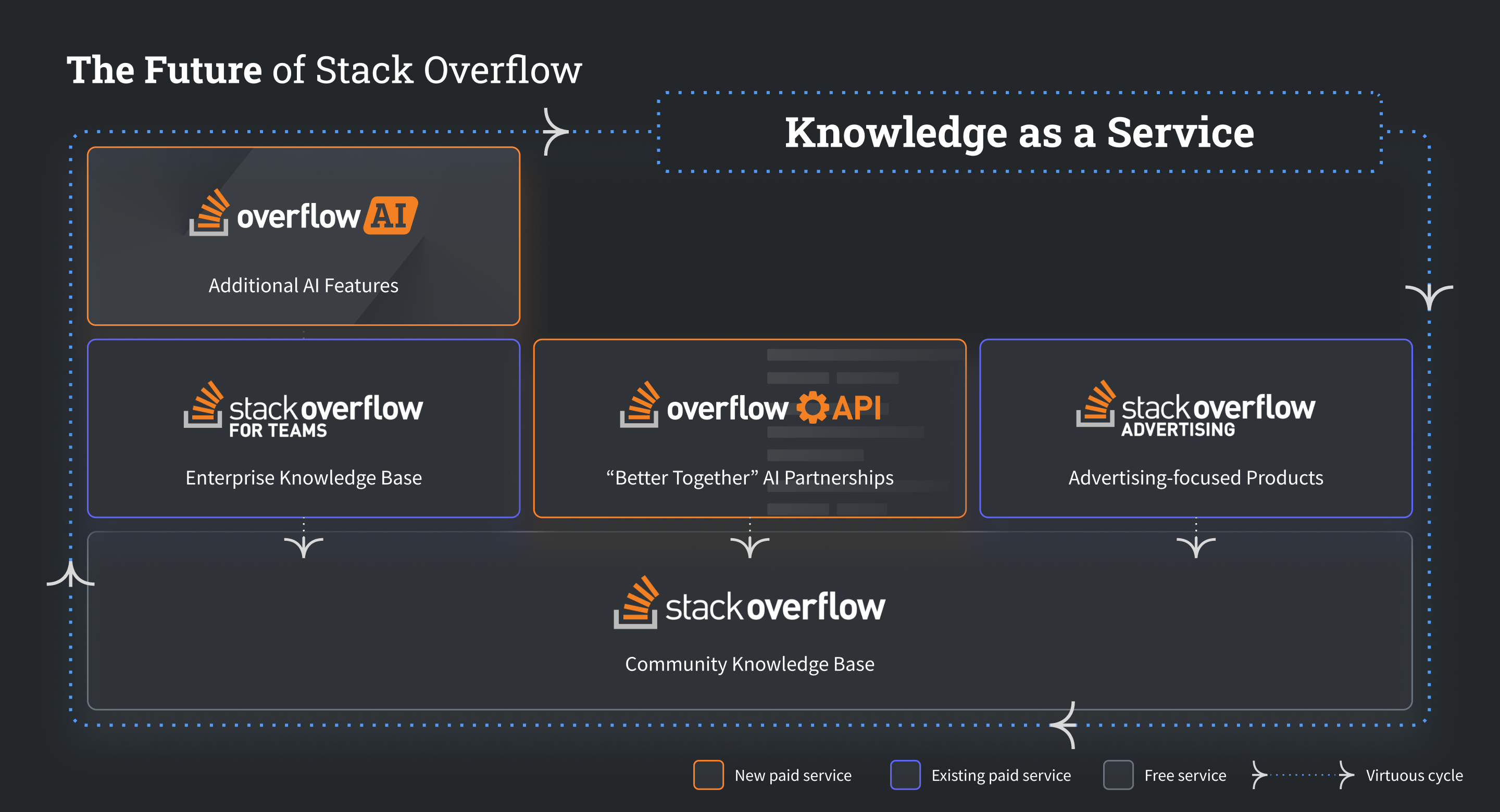
Ultimately, this strategy is simple: the future necessitates a world where we rise to meet these changes by evolving towards Stack Overflow as a “Knowledge-as-a-service” platform or getting left behind. By doing nothing, we risk the existence of our communities and the platform. We choose to rise to this challenge and build for a future where communities and content providers can coexist and thrive.
Underpinning these knowledge-as-a-service businesses is the need for attribution of content and creators. In the next post in this series, we'll cover how attribution works for our OverflowAPI partners and why it matters.