
The 2026.3 release marks our most significant milestone of the year: the general availability of Ingestion in Stack Internal.
Ingestion is now generally available
You’ve built a strong foundation in Stack Internal, but refreshing it with new content and onboarding other departments shouldn't be a manual hurdle. Ingestion now allows you to quickly seed your instance with structured, verified knowledge that would otherwise remain siloed across your tools.
But this release isn’t just about saving time, it’s about making your technical context accessible to the tools that need it. By providing a continuous stream of expert-vetted knowledge, Ingestion ensures your AI tools are actually reliable, reducing the repetitive “shoulder taps” that pull senior engineers away from high-value work.
Convert noise into high-signal posts
Ingestion’s AI pipeline intelligently chunks, cleans, and converts raw text into structured, atomic Q&A pairs. These posts are automatically tagged, mapped to users, and scored for confidence before being routed to experts for final review. By converting fragmented, unstructured content into verified units of knowledge, your institutional data is optimized for both human discovery and AI retrieval.
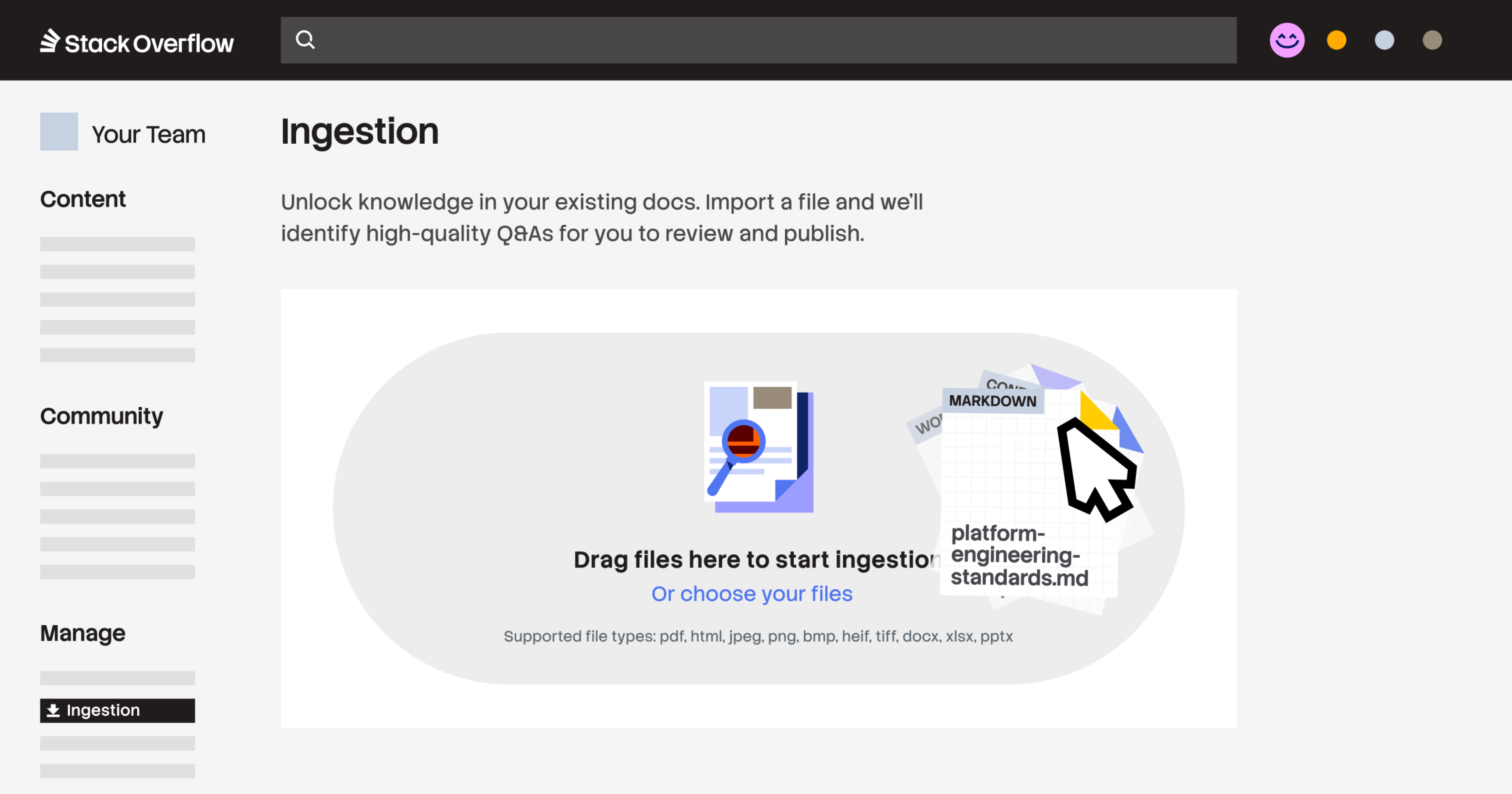
Ingest siloed content at scale
Ingestion supports uploads of PDFs, HTML, Markdown files, images (.jpeg, .jpg, .png, .bmp, .heif, .tiff), and Microsoft Office documents (.docx, .xlsx, pptx). You can automate high-volume migrations via a POST /ingest/file API endpoint or simply drag and drop files directly into the web interface. This centralizes and structures raw data from across your organization into a single, verified place almost instantly.
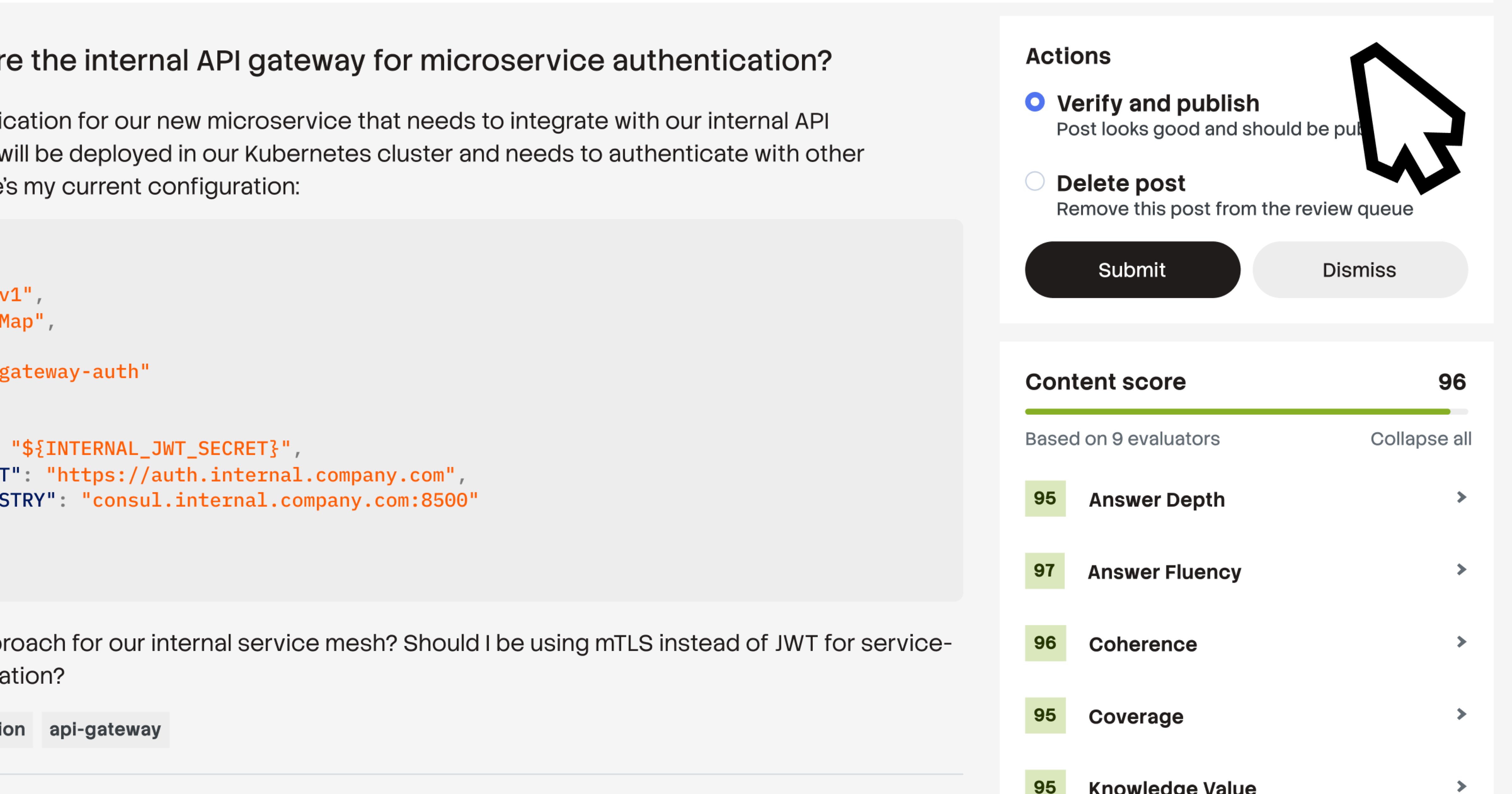
Let SMEs validate instead of curate
Ingestion automates the "first draft" of Q&A pairs by pre-structuring, tagging, and confidence-scoring each one, allowing SMEs, admins, and moderators to move straight to approving high-quality content rather than authoring it from scratch. By shifting the workload from manual curation to expert validation, you ensure only trusted knowledge reaches your teams and AI tools.
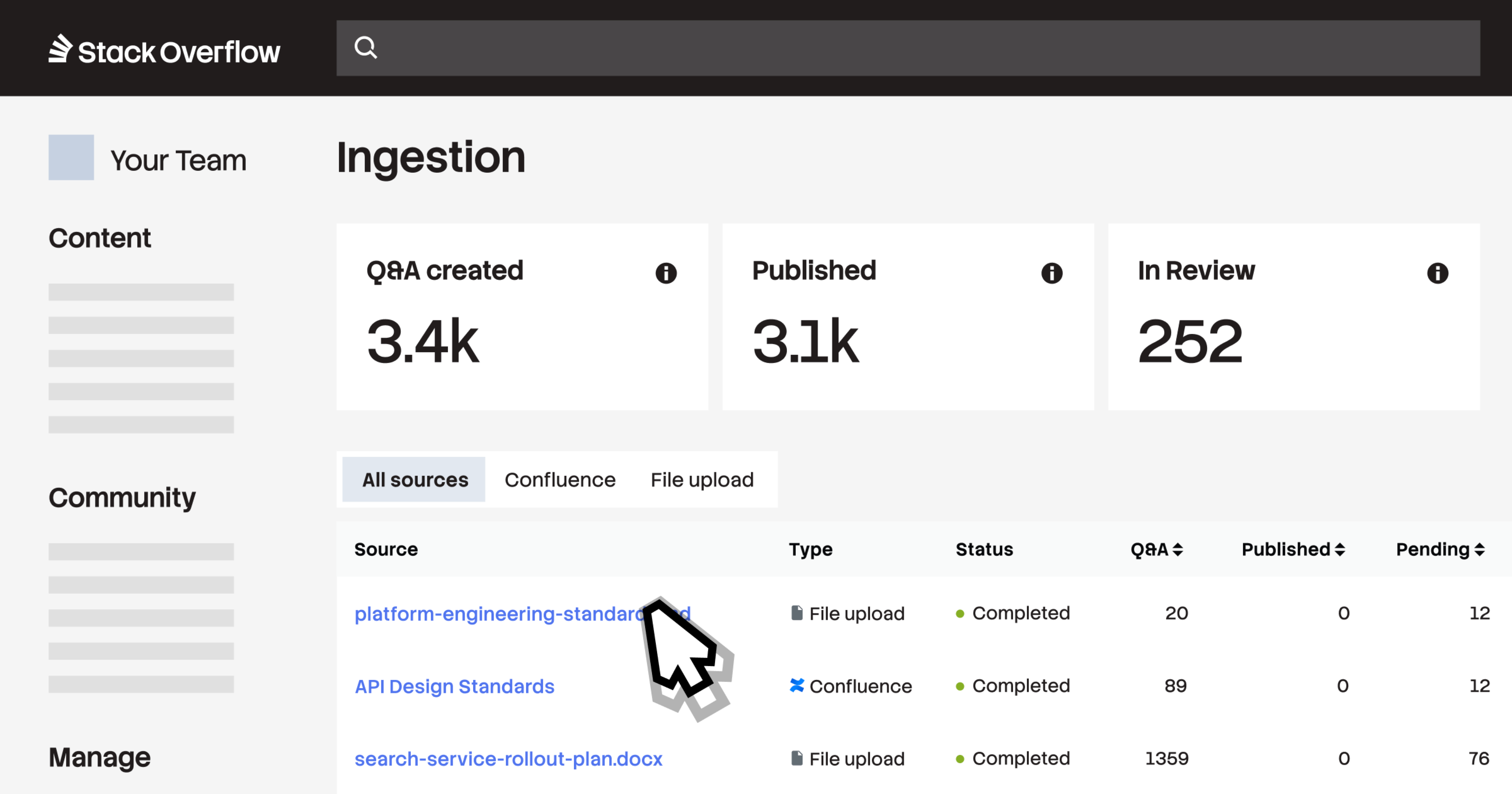
Activate your Confluence data
This release also includes a Confluence Cloud connector that lets you connect Stack Internal directly to select Confluence spaces. Once connected, Ingestion converts static, long-form Confluence pages into SME-verified Q&A pairs that are easier to discover, trust, and maintain at scale. Every generated post includes a direct link back to the original Confluence source page.
Close the context loop with MCP
Once validated and published, all converted Q&A posts are accessible in your AI tools and IDEs via the Stack Internal MCP server. This surfaces expert-vetted context where your team already works, ensuring that ingested data is actively updated and used to drive better technical decisions and agentic outputs.
Get access and learn more
Stack Internal Enterprise customers can start using Ingestion on April 29, 2026. To get started, enable it in your Admin Settings (see this guide for more details). All customers get 100 Knowledge Objects (approved Q&A pairs) per month at no extra cost. For higher volume needs, contact your Stack Overflow account representative.
To learn more about updates in the Stack Internal 2026.3 release, read the release notes.