
Git has won the race for the most popular version control system. But why exactly is it so popular? The answer, at least in my opinion, is pretty clear: branches! They allow you to keep different versions of your code cleanly separated—ideal when collaborating in a team with other people, but also for yourself when you begin working on a new feature.
Although other version control systems also offer some form of branching, Git's concept and implementation are just stunning. It has made working with branches so quick and easy that many developers have adopted the concept for their daily work.
In this post, I'd like to explore and explain the what, why, and how of branches:
- What are branches, in a nutshell?
- Why are branches so useful?
- How are they used, especially in teams?
- What do branches look like under the hood in Git?
We'll be looking at the concept of branches in Git from a high-level perspective—with the ultimate goal of better understanding what they are and how they should be used so that you and your team can get the most benefit out of them.
What are branches, in a nutshell?
Put simply, a code base is a collection of files. Any meaningful change (e.g. when developing a new feature or fixing a problem) will most likely involve a couple of those files.
Just for a moment, let’s pretend that version control and especially its concept of “branches” didn’t exist. In such a situation you would have to be very careful when making changes—because you couldn’t easily undo them and you would risk breaking the current, working version. But there’s an easy way to mitigate these risks: you could simply duplicate the whole project folder! In this copy, you could then make any changes you like, without worrying about breaking something.
Branches in Git have the exact same effect and purpose: they provide developers with separate workspaces for their code. Of course, they are much more clever than our simple “copy folder” strategy. For example, they don’t waste disk space (which a simple file system copy would do) and they are much more capable when it comes to collaborating with other developers in the same project.
Let’s dive a little deeper into the details!
Why are branches so useful?
Branching’s value becomes clear if you think about your workflow without them: imagine that a team of 10 or 20 developers all work in the same "folder," so to speak. All of them simultaneously editing the same source code files. Suddenly, their code is now your code. Some may be implementing brand new features, which could introduce bugs in the beginning. Every experiment that a developer has to perform in order to make progress and every bug that is unavoidable in that process will affect all of their teammates. A handful of people working together in such a way is enough to bring the whole development process to a halt.
When only one context exists that all teammates and all features have to share, commit history looks something like this:
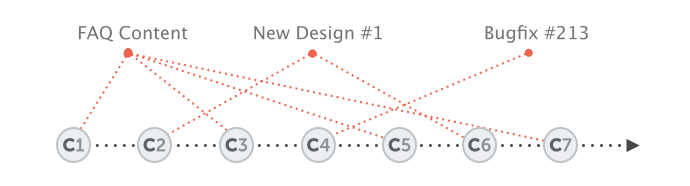
As the (quite confusing) dotted red lines show, working without branches quickly results in chaos: it becomes hard to understand which commits belong to which feature! In the distant past, where a powerful branching model had not been available, version control was—quite frankly—less useful because a major structural element was not available.
Let's imagine the same scenario with branches in mind. Every experiment, every new feature, every bug fix gets its own branch, its own context that is completely separate from all the other development contexts. "Separate" in this regard also means "safe": if a bug occurs in one context, none of the other contexts are affected by that. Branches, in other words, are convenient containers that make developing in multiple, simultaneous contexts safe (and possible in the first place).
Features and bug fixes are clearly separated from each other, and so are their commits and their code:
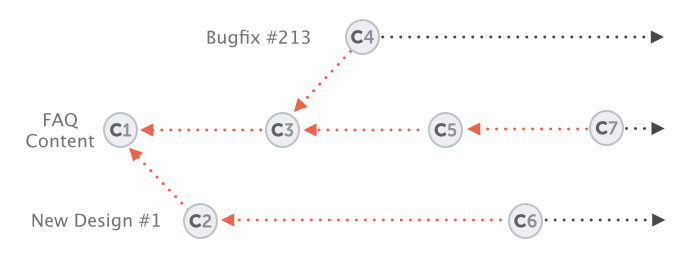
In the above example, the changes in "FAQ Content" and "New Design #1" don't get in each other's way.
To make a long story short: the main benefit of using branches is that they make software development safe. They prevent bugs and problems from leaking from one context into another and help you undo mistakes more easily.
Why Git?
As said, branches are not exclusive to Git. Many other version control systems offer branches as part of their toolsets. But there are a couple of advantages that set Git's branching model apart:
- Simplicity: Using branches in Git is really easy. Beginners sometimes hesitate before creating a new branch and ask themselves if a particular situation justifies creating a new branch. Such hesitation is unnecessary: creating new branches in Git is so simple, and it doesn't come with any drawbacks. Just take disk space as an example: creating a new branch in Git does not copy around files, possibly creating a large amount of duplicate files; instead, Git’s file management makes sure that nothing has to be copied!
- Speed: In Git, all operations around working with branches are very quick. While some version control systems, for example, create copies of files when a new branch is created, Git’s internal management does not need this. As a result, there's no waiting time involved when creating new branches or working with existing ones.
- Merging: Creating safe separate contexts using branches is one thing. But integrating (or "merging") branches back into other contexts is the other part of the game. In many other version control systems, merging can be a complicated business: you might be asked to provide the exact revisions or select specific changesets. Git, on the other hand, makes it very simple and user-friendly. In most cases, it just works without any user intervention.
Git was built with the concept of branches in mind. It was neither an afterthought nor a "nice to have" feature, but instead one of the core requirements from the start.
How are branches used in practice?
The general idea remains the same: branches provide a safe, separate context for the many different kinds of work that happen in any project at any time. In practice, this takes a number of different forms.
Experimentation/New features
Whenever you start "something new" in your project, it makes sense to create a new, separate branch for that. It doesn't matter if it's just a little experiment or a full-blown new feature: you want to protect the mainline of code and your coworkers from all the small and big bugs that inevitably happen when new code is being produced.
Having a separate context has the additional benefit that it's easy to get rid of—if your experiment doesn't yield anything or your new feature doesn't work out. Again, just think about a situation like that without branches: your new experimental commits would have been mingled with other features or even the mainline of code, making them difficult to get rid of later.
Bug fixes
Even for bug fixes (if they require more than a single line of code), a new separate branch very often makes sense. One advantage, again, is that the relatively untested new code that you are producing won't interfere with the work of others. But the more important advantage, in this case, is about organization: by having the bug fix in its own branch, it's easier to integrate it both when and where you want. Maybe you want to integrate the fix only at a certain point in time or into certain other contexts—all of which is easily possible with branches.
Short-lived branches
Both of the previous examples—experiments/new features and bug fixes—belong to what are known as short-lived branches. As the name implies, these branches aren't meant to live forever. Instead, they were created for certain well-defined purposes (e.g. implementing a new feature idea) and can then be deleted once they have been integrated into a long-running branch.
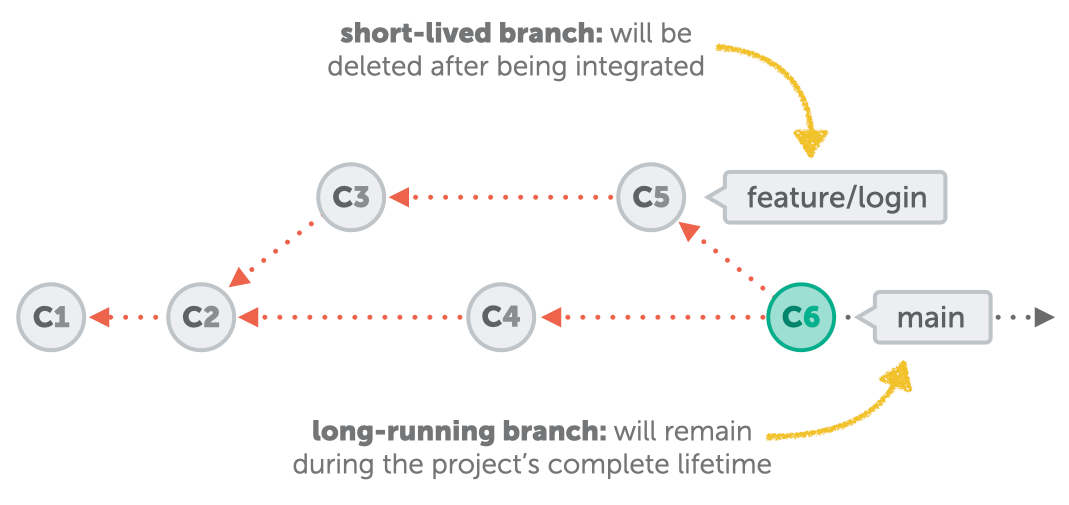
Long-running branches
Unlike their short-lived colleagues, long-running branches typically remain in a project during its complete lifetime. These branches are not tied to specific features or topics. Instead, they represent states or stages in a project:
- the typical "main" branch for the project's mainline or production code
- often also a "develop" branch where different short-lived branches are integrated
- sometimes also branches like "staging" or "production" that represent certain stages or environments
Along with this distinction between short-lived and long-running branches, there's also often a golden rule: never directly commit on a long-running branch; code should only land on these branches through deliberate integration (via merge or rebase).
How do branches work technically, under the hood?
When trying to imagine how branches work, it's tempting to use the concept of "folders." After all, creating a new branch feels very much like copying the project's current state and pasting it into a new, separate folder.
But part of the genius behind Git is that it doesn't just "copy all contents" of your project, which would make things slow and use up lots of disk space. It's much smarter than that!
Pointers, not file system copies
If branches aren’t copies of the file system, what are they? To answer this, it's important to know that commits in Git are incredibly safe and efficient at storing data:
- Safety: A commit's contents and metadata are run through an SHA-1 hash algorithm, which makes it very hard to manipulate data after the fact.
- Efficiency: Commits don't store data again if it has already been stored previously. This means that files that have NOT been changed between commits aren't taking up unnecessary disk space.
Keeping this in mind, would there be any need to "invent" something on top of this? No, of course not! That's why branches in Git are an extremely lightweight concept - far from heavy "copies of the filesystem".
A branch is simply a pointer to the latest commit in a given context.
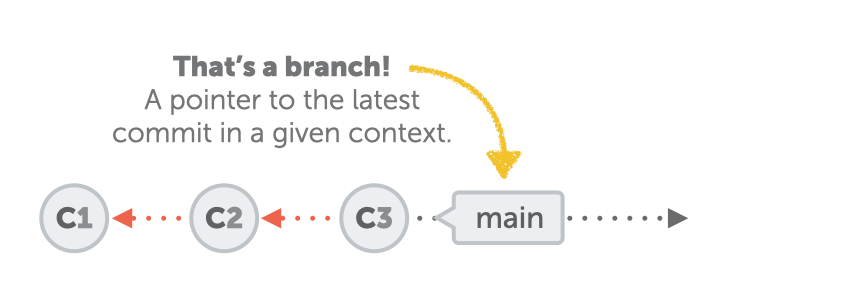
This pointer is automatically moved every time you add a new commit on top. Very practical!

Let's look at this fact again, from another angle: commits in Git are identified by their SHA-1 hash, those 40-character long, cryptic strings. These commit hashes are static and immutable. Branches, on the other hand, are highly flexible, always changing to the commit hash of the latest commit anytime you create a new commit in that branch.
What is a pointer, really?
But what do those mystical pointers look like, and where do they live? To answer this one, we'll have to take a quick journey into the inner workings of Git: the hidden ".git" directory, located in the root of your project. In here, you'll find a subdirectory named "refs" and another subfolder named "heads": it's here that each branch is represented by a file named after that branch.
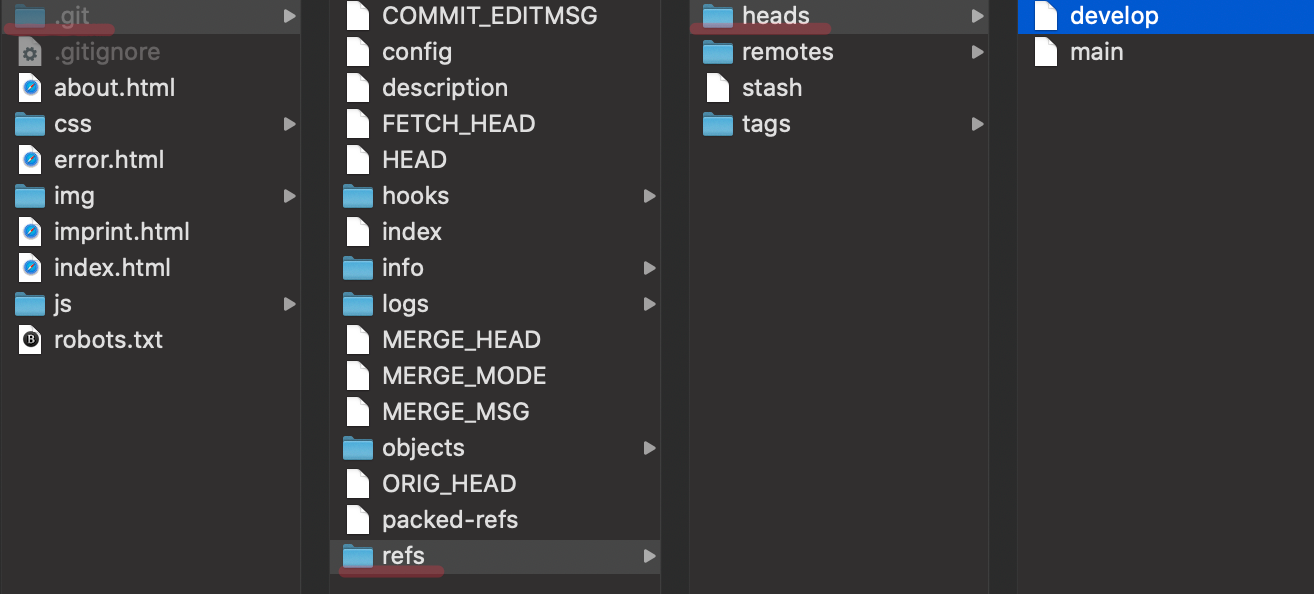
When you create a new branch, e.g. with a command like "git branch my-new-branch", you'll find a new physical file in here, named "my-new-branch".
And if you were to look at the contents of such a file in a text editor, you'd find that it only contains a single piece of information: the SHA-1 hash of the commit it currently points to!
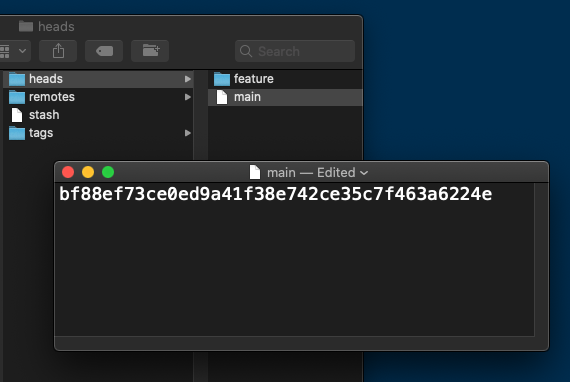
The image above shows the contents of such a “pointer file”: the branch named “main” currently points to the commit with the SHA-1 hash “bf88ef73c”.
Which of those pointers is currently active?
But how does Git know which of your local branches is currently active? What is the branch that new commits are added to and that moves its pointer along when this happens?
Git keeps another, special pointer named "HEAD". The sole purpose of HEAD is to point to the currently active (or "checked out") branch:
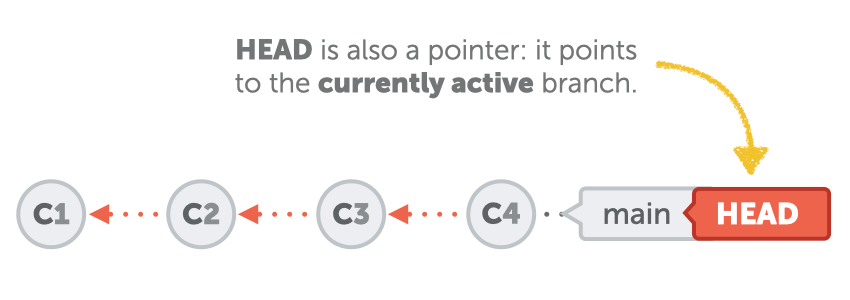
In the local .git repository folder, you'll find this information saved in a file appropriately named "HEAD". And the content of that file typically looks something like this:
ref: refs/heads/my-new-branch
What happens when switching branches?
Finally, let's take a look at what happens when you switch the currently active branch—e.g. with a command like git checkout other-branch or git switch other-branch.
Such a command will do two things:
- a) The HEAD pointer is changed and now points to "other-branch".
- b) The files in your working copy are swapped and now represent the state from the latest commit in that branch.
Understanding Git == becoming a better developer
I hope that this post gave you a better understanding of how branches—one of the core tools in Git—really work.
Like in many other areas, it's only when you deeply understand something that you can really reap its benefits. This is especially true for Git, in my opinion: advanced tools like interactive rebase, submodules, or the reflog have the power to make you a better software developer—but you'll have to take a bit of time to properly learn and understand them.
If you want to up your Git game, I put together the "First Aid Kit for Git"—a free collection of short videos that explain lots of helpful tools like the reflog, interactive rebase and others that can help you avoid or repair mistakes.
Have fun becoming a better programmer!