
“Move fast and break things” sounds great on a t-shirt when you’re building a calculator and the greatest risk is a minor miscalculation. Consider a civil engineer working on bridges and tunnels—would we be comfortable if they wore a t-shirt with the motto “known shippable”?
No, because we want to be assured that those engineers whom we entrust to build these critical systems have designed them for structural integrity, safety of the users, and the longevity to serve a generation of people.
We software engineers are in the same boat now. The things our community builds are awe-inspiring and wonderful, and the world is eager to participate in our invention. But with that comes a duty of care to those that don’t understand the inner workings of software or data processing, to build systems that respect those individuals, and to ensure the integrity and safety of the systems we provide society. The term of art for this consideration is “data privacy,” but in practice it’s the “respect” concept that may be more apt. Respectful systems are ones where choices are presented transparently to users, and the information users elect to share with the system remains under their control at all times. It doesn’t seem like too much to ask, right? In our field, it’s becoming table stakes.
The good news is, it doesn’t mean we can’t move fast. To quote the endlessly thoughtful DJ Patil, we can “move purposefully and fix things.” The key to combining privacy and innovation, rather than pitting them against one another, is baking privacy into the SDLC. Analogous to application security's (AppSec) upstream shift into the development cycle, privacy belongs at the outset of development, not as an afterthought.
Compliance vs. respect
There are two ways to look at the recent emergence of regulatory interest in our field: an oppressive tax on the agility of our industry (compliance), or an opportunity to build better software that respects its users first and foremost. I’m an optimist so I choose the latter, but this requires implementing fundamental engineering principles and tools. A great reference for this is Dr. Ann Cavoukian’s seven principles for Privacy by Design, which are:
- Proactive not reactive; preventive not remedial
- Privacy as the default setting
- Privacy embedded into design
- Full functionality—positive-sum, not zero-sum
- End-to-end security—full lifecycle protection
- Visibility and transparency—keep it open
- Respect for user privacy—keep it user-centric
Today, data privacy for most engineering teams is something tackled after software is shipped to production. It’s a little like application security a decade ago, where you’d complete implementation, and then security would happen after the fact by pen testing and fixing issues as they were identified.
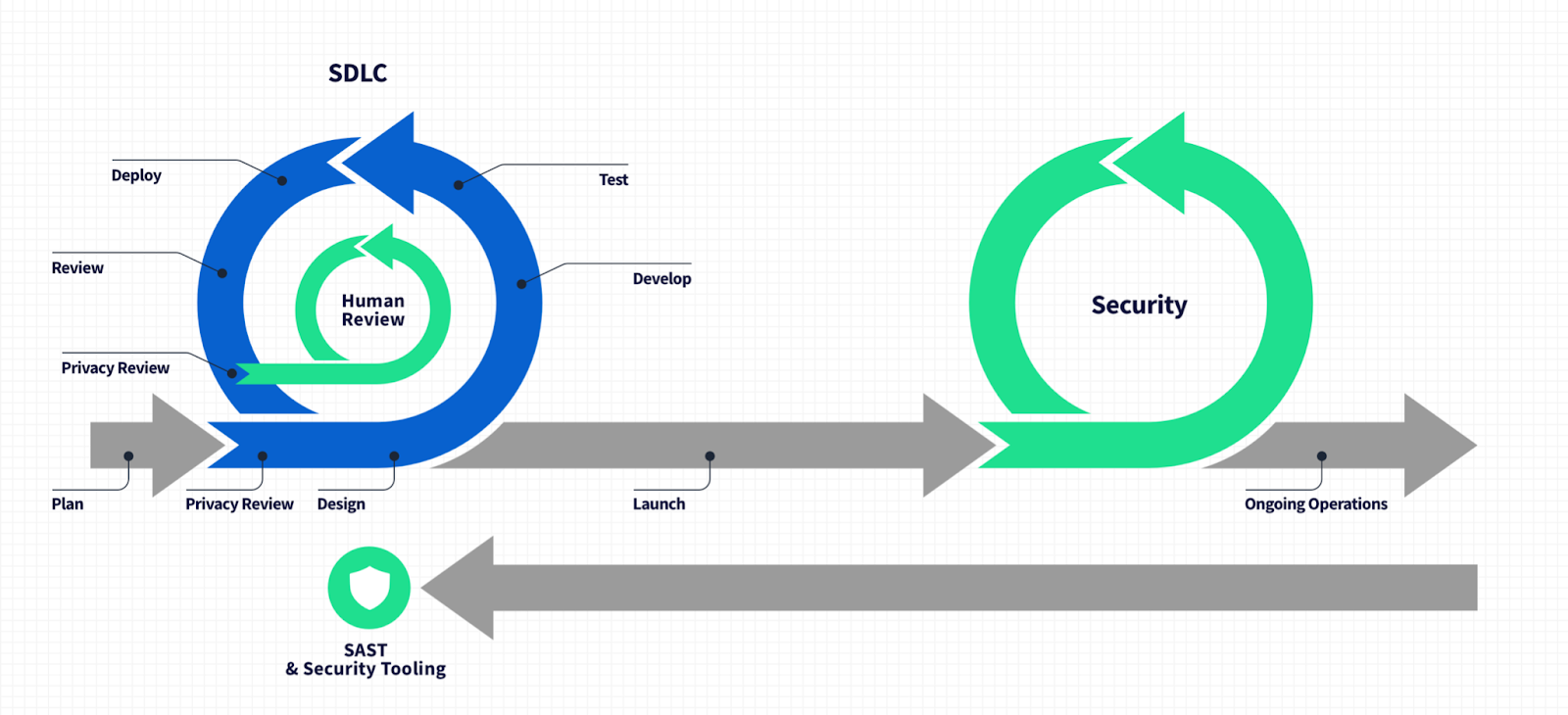
However over the last few years, AppSec has “shifted left” to be part of the SDLC. Well-built software is secure before it leaves the repo you were working in, and security is achieved through a change in engineering mindset and a suite of awesome tools for static code analysis, application security testing, and threat modeling that ensures the code you ship is as secure as it can be. Engineers are increasingly proud to have a security mindset and understand defensive design and zero trust principles.
But again, today privacy is after-the-fact. For example, if you’re in an early-stage team, you iterate on an MVP until you find product market fit. That lean approach makes business sense, but as soon as you have traction—and customers—you’re collecting data. Because you didn’t plan for this part, you’re instantly exposing your users to risk and accumulating a form of data planning debt that’s nearly impossible to climb out of. The more successful your trajectory, the faster your growth, the more data you accumulate, and the more acute this problem becomes. You can’t go backwards and unpack the debt, so now you’re building unscalable mechanical turks to mitigate risk but unable to fix the underlying problem.
The problems of privacy
Let me give some real-world technical problems this yields:
Real world problem #1: Orphan data sets
In large tech companies, “orphan data sets" refer to datasets that exist in their infrastructure that are still in use but there’s no clear understanding of what is in there, where the data comes from, and how it’s used.
We’re all familiar with this story: you build your first product quickly, so perhaps your documentation isn’t perfect or your data model evolves organically. You find success and start growing, so more engineers join the team. Team hierarchy is pretty flat and can spin up a database and start working—awesome, we’re the essence of agile!
Then you’re concerned about system availability and scaling so you start to chunk things into a more elegant service-oriented architecture: different engineers pick pieces off as you add functionality to meet customer demand. Some of your early engineers leave the company, new ones join, the cycle repeats, and before long you have a platform of 500+ microservices and hundreds of databases without any consolidated annotations or metadata. You have no certainty in what serves which purpose and there’s lots of grey areas.

How’s this solved today? A team of dedicated data engineers sift through these systems, starting from the dataset and working back forensically through the services layer to understand what data is being stored, what the services are doing, and what business function is being performed.
And because you haven’t changed your engineering practices—you’re still shipping code the way you were—it’s a Sisyphean problem. Your data engineers are constantly untangling systems to try and understand where data is and how to govern it safely on behalf of your users.
Real world problem #2: Enforcing a user's rights
In order to respect your users, you must respect their rights and, increasingly, these are backed by legal requirements, like with Europe’s GDPR, California’s CCPA, and Brazil’s LGPD.
These rights vary by location, but the basic principle is that when a user of your system wants to, they can access all the information you have about them, they can update it, or they can delete themselves completely. In addition to this, users have rights on how you are permitted to use their data. This creates requirements to be able to suppress an individual user's data from being used in a specific process in your systems if they disagree with it.
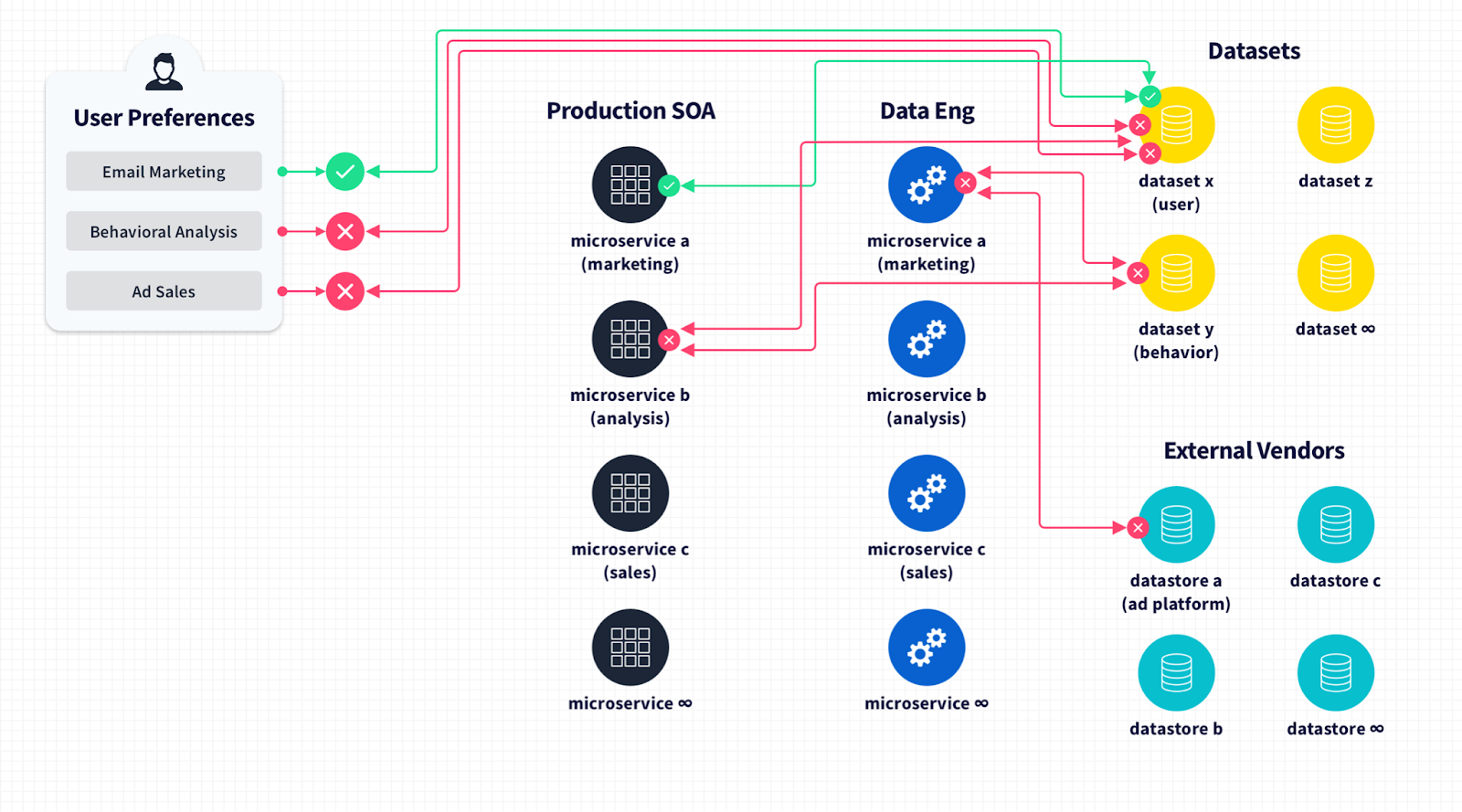
Imagine you have a really elegant, service-oriented architecture of 400 services, each responsible for a distinct piece of business logic. If user A in your platform opts out of processing for 27 of the things you do, you need to be able to identify that individual, a single entity in your dataset, and enforce a constraint that may only apply to specific attributes of their entity recordset on a single process—just one services request.
At a 10,000 ft view, this is all possible if you’ve designed your architecture and data model to support this level of granularity and policy enforcement from the start within the SDLC. But that’s not what usually happens.
In a production reality, you’re left with manual policy enforcement, new policy tables being joined to entity records at runtime in an ad hoc fashion to start to enforce specific constraints. It becomes a Rube Goldberg machine of your users submitting their consent preferences and checking boxes. It looks good in the UX at least, but in the backend it’s a bunch of unscalable manual processes, workflows and runbooks to update users' preferences and ensure they’re excluded from certain pipeline jobs. It also generates reports for legal teams to ensure that when a user has said “no” to something, their consent preference was enforced across your complex data plane. For a successful business, there’s the possibility that they’ll have to do this thousands, even millions of times.
If these are the symptoms, what’s the cause?
As I wrote earlier, privacy cannot be truly fixed with a bandaid after a system is built. The cause of data privacy failures happen upstream in the SDLC, long before most of us think of privacy.
Like application security, the source of problems and the locus of best prevention is where software is being designed, implemented, and tested. This is where instituting design decisions, implementation practices, and privacy devtools can mitigate privacy risks like the ones we so commonly see.
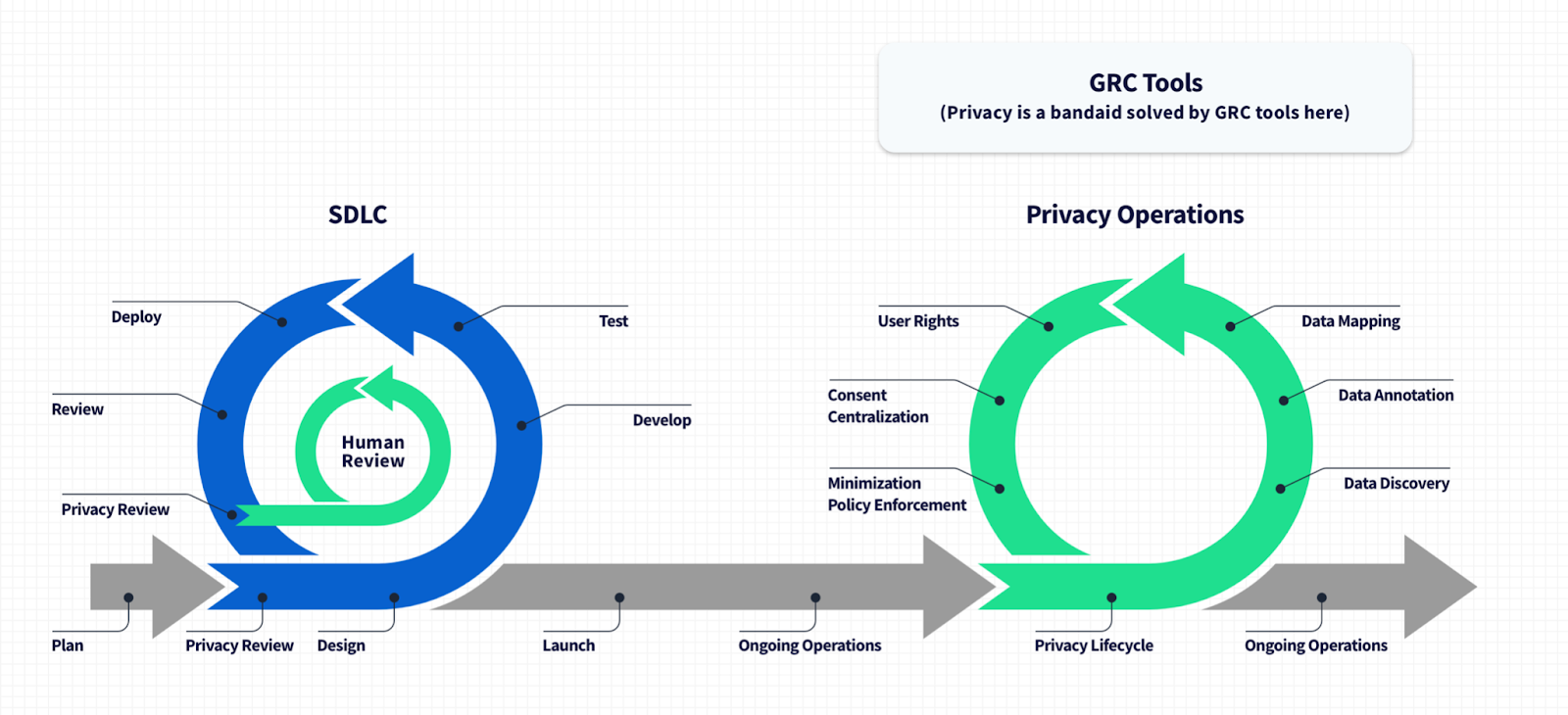
To put it simply: if privacy was part of the software development process, the example of trying to unpack orphan datasets would never materialize, because code merged in a privacy-centric SDLC will describes its purpose, the types of data it uses, and its data I/O so that you can easily observe across the data plane. You’d have a complete map of the data passing through every piece of code—because of steps like thorough annotation at the code level, you know explicitly the substance, source, and purpose of the data in your systems; every dataset has a home.
An SDLC with privacy baked in results in a system that respects its users rights out of the box without bandaids or manual processes. The system identifies data flows clearly such that data discovery and mapping efforts are redundant; your product stack self-describes its data operations immediately upon deployment.
Treating privacy as an afterthought results in a vast waste of engineering resources in production-related privacy and data compliance operations, which could be obviated with better tooling in the CI/CD pipeline.
A proposed solution to data privacy
The core privacy problem of our age is that systems aren’t built to be respectful from the bottom-up. Some of the reasons for that are cultural, sure, but some are related to the tools at engineering teams’ disposal. Simply put, up to now they haven’t been fit for the task. I’ve been considering this problem at length, and have some ideas for how this problem could be solved.
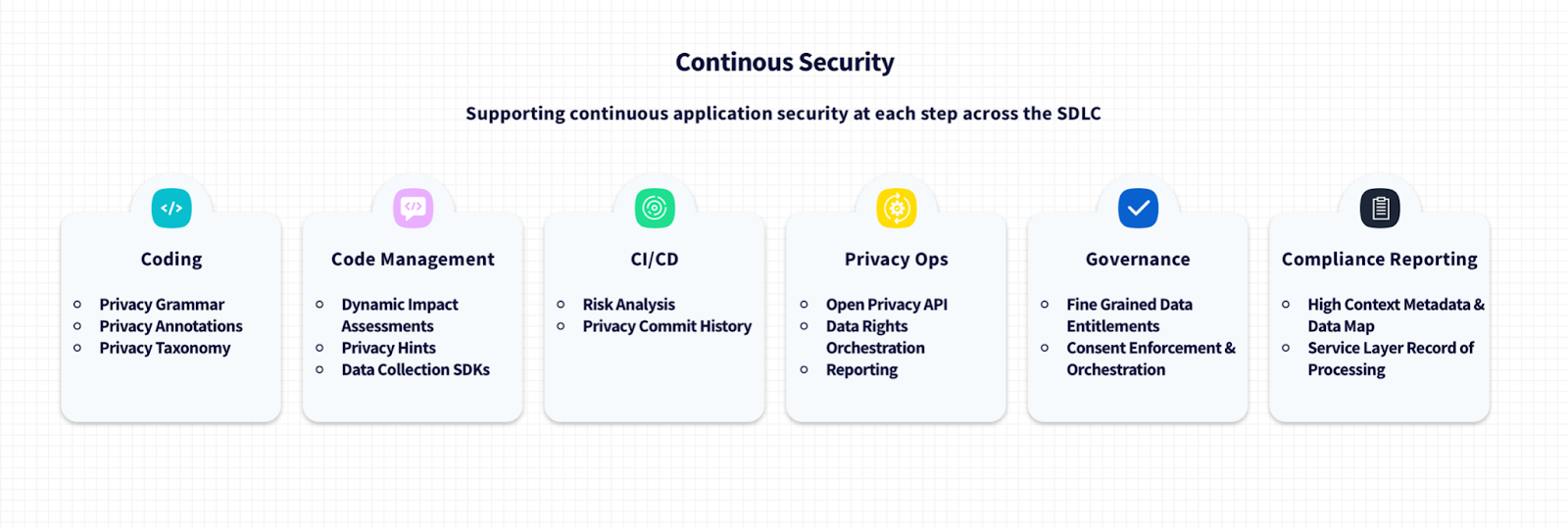
1. Low-friction privacy dev tools
The first step is ensuring engineers have a form of ‘privacy grammar’ or a shorthand, low-friction way to describe what their code does and what types of data it uses and make this part of their editor and CI process. Code comments and documentation are a good start, but a thorough tooling solution is both human and computer readable, integrated into both manual and automated workflows.
When implementing a given functionality in their project with integrated tools, developers can easily describe the context of what their code is doing and on what types of data it’s acting.
Also, in the same way that security/SAST tools are now an accepted component of a well-built CI/CD process, tools that provide CI hooks that enable the privacy grammar and data classifications to be evaluated on each commit and MR, providing easy to apply nudges to developers on how to ensure their work is privacy respecting.
2. Automated risk evaluation
At least for the foreseeable future, I don’t believe we can or should remove humans from the loop. However, the current process for most companies creates a lot of friction between engineers trying to ship code and the manual privacy review process, while also occupying valuable bandwidth.
Automation in the commit and merge phases can better groom high-risk and low-risk issues for human oversight and remove the need for engineers to completely async privacy review forms. Privacy risk evaluation can be an elegant part of the CI pipeline.
3. A global personal data taxonomy
So much of privacy starts with understanding the data your software uses. One of the most common issues with healthy privacy is agreeing to a standard for the types of data in a system. Too often, data types are created by the teams that use them, leading to a hodgepodge of formats. Legal requirements in different geographies make standardization a challenge but this can be achieved by taking the ISO27701 PIMS standards, specifically ISO/IEC DIS 19944-1, and building a single view of personal data classification that can be modeled by every engineering team.
Using a single standard to classify data across a system, we can simplify interoperability of systems for privacy operations and users' rights requests as well as achieve uniform inter-system governance.
4. A privacy policy enforcement engine
Today policy and governance enforcement requires extending an existing Role-Based Access Control (RBAC) or Access Control List (ACL) type system to roll your own fine-grained governance solution, and it still typically acts at the abstract dataset or system level.
A fine grained data policy model should be designed from day one to enforce data access at the individual field level for each entity based on policies managed at the entity level. This granularity is the only way to ensure that privacy rights can be truly enforceable. For this to be possible, however, it needs a scale of interoperability, so integration with a standard policy enforcement model like Open Policy Agent is a key step.
5. Make consent part of validation in front-end frameworks
Today consent is generally dealt with through cookie banners or individual flags set at runtime in a form flow. Consent can and should be a part of the validation module of all front-end frameworks. If we already know at runtime what data is being collected (because we’re validating for it) these same validators could be used to check for context. Tools like the fine-grained data policy model described above would permit any engineer to extend these validations to sensibly check for data type and consent.
We already use validation against field types to generate business logic checks for data type, structure, etc. This must be extended to ensure that field labels ascribe whether consent should be collected automatically and provide a central consent tracking service at application runtime so that user consent is unified throughout application usage. These steps make it harder for systems to accidentally fail to register consent choices or communicate a user's rights.
6. An immutable privacy log
Every application should persist a hashed record of privacy related actions. Such a log would enable engineers to reliably track user rights and privacy activities through application and user lifecycle and demonstrate the decisions made in the privacy CI pipeline.
Trust through transparency
Transparency and privacy might seem strange bedfellows, but they're actually closely linked. Think back to Dr. Cavoukian's sixth principle of privacy by design: visibility and transparency. A commitment to building trustworthy systems applies to the very tools building those systems. Then every engineer, even without deep training, can do a better job of baking privacy into their code while also reducing friction between engineering and legal teams.
As software engineers, we build the systems that billions rely upon for their finances, safety, health and wellbeing. Our tools and processes must reflect the seriousness of our responsibility to respect users' data. A post-hoc approach to privacy is labor-intensive and risky. It is fundamentally reactive, unable to scale with the rapid growth of the systems that power our world.
By equipping engineers with the tools to implement privacy by design within the SDLC, we build better, safer and more respectful systems. On an operational level, we reduce the pain of fixing issues in production, enabling our teams to focus on innovation instead of scrambling to achieve after-the-fact compliance. On a cultural level, we deliver systems that genuinely earn users' trust, which are the only systems worth building in the 2020s.
For years, engineers left AppSec as an afterthought. Today, it's almost impossible to think of the typical SDLC without AppSec embedded into it. We can and must follow a parallel approach with privacy.