If you're starting a new project from scratch—a new app, service, or website—your main concern usually isn’t how to operate it at web scale with high availability. Rather, you’re likely to focus on building the right thing for the customer you’re targeting or finding product market fit. If you’re creating an MVP for a startup, you need to get to that before scaling, otherwise, who are you scaling for? If you’re a developer at an enterprise, you want to make sure that you’re meeting the expectations and needs of the business. Operating at scale is, at best, a tomorrow problem.
Hence, when it comes to choosing the right set of technologies, Kubernetes—commonly associated with large, distributed systems—might not be on your radar right now. After all, it comes with a significant amount of overhead: setting up and operating a cluster, containerizing your app, defining services, deployments, load-balancers, and so on. This may look like massive overkill at the early stage, and you might think that your time would be better spent on other tasks, such as coding the first couple of iterations of your actual app.
When we started building Stack Overflow in 2008, we didn’t have that choice. There was no Docker (2013), no Kubernetes (2014). Cloud computing was in its infancy: Azure had just launched (2008), and Amazon Web Services was about two years old. What we built was designed for specific hardware and made a lot of assumptions about it. Now that we’re modernizing our codebase and moving to the cloud, there’s a fair amount of work we have to put in to make Kubernetes and containers work.
Going through this process has given us a new perspective. If you’re building a new app today, it might be worth taking a closer look at making it cloud-native and using Kubernetes from the jump. The effort to set up Kubernetes is less than you think. Certainly, it’s less than the effort it would take to refactor your app later on to support containerization.
Here are three reasons why building your app on Kubernetes from the start might not necessarily be such a bad idea anymore.
Managed Kubernetes does the heavy lifting
At Stack Overflow, when we set up our first in-house Kubernetes cluster a couple of years ago, it took us close to a week to get everything up and running: provision virtual machines, install, configure, configure, configure. Once the cluster was up, there was ongoing maintenance. What we ultimately realized was that Kubernetes was great for us—but we wanted somebody else to run it.
Today, managed Kubernetes services such as Amazon’s Elastic Kubernetes Service (EKS), Microsoft’s Azure Kubernetes Service (AKS), or Google’s Google Kubernetes Engine (GKE) allow you to set up your own cluster literally in minutes. For example, in AKS, you can just click a few buttons in the portal and fill out a couple of forms:
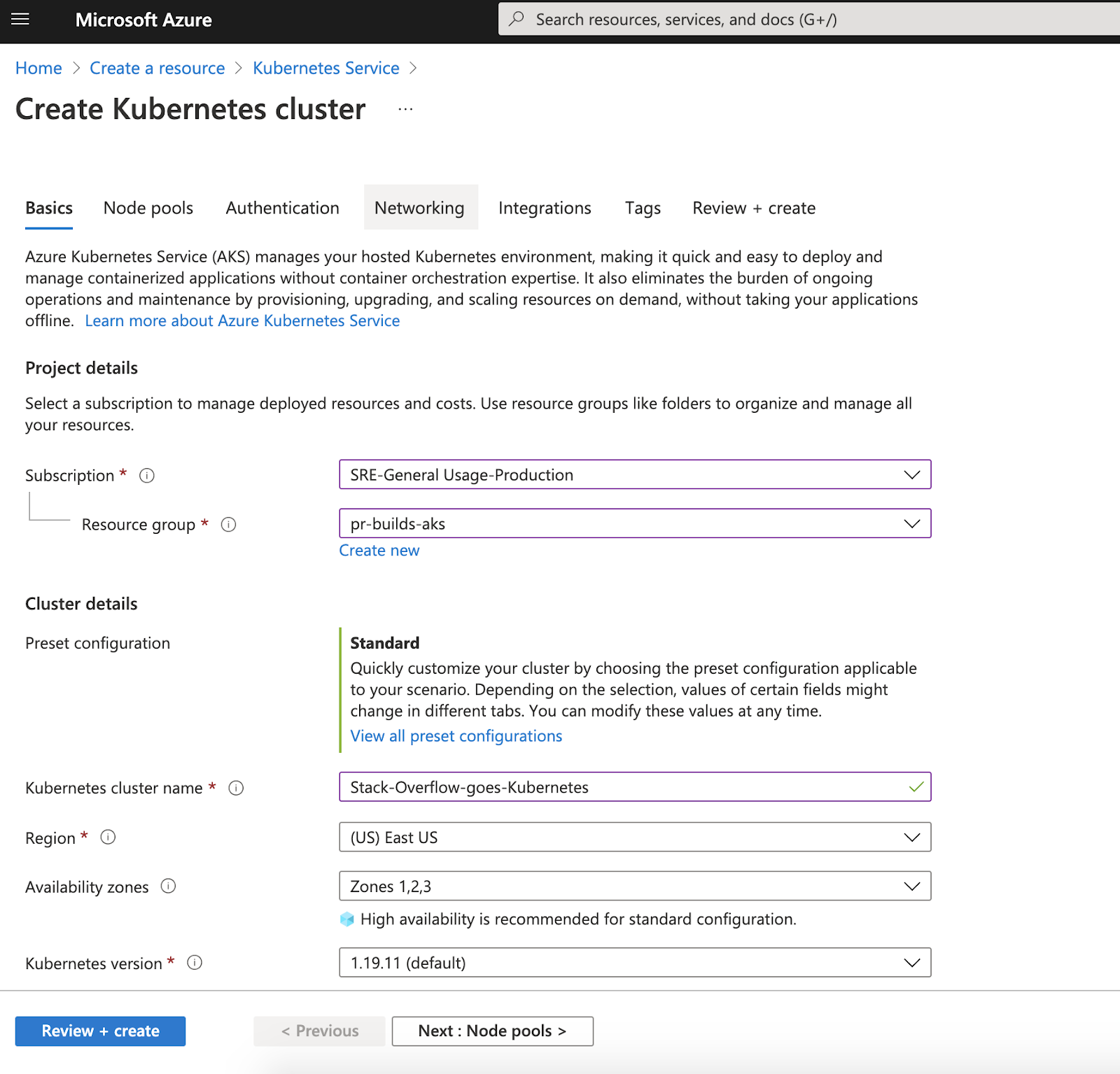
This is convenient, but you might wanna stop short of actually creating the cluster at the end of the workflow. Go through the wizard, but don’t click that blue “Create” button at the end! Instead, download the configuration you just created as an ARM template and check it into your source control system. Now you have the best of both worlds—ease of use and infrastructure as code (IaC)!
Once you’re set up here, there’s little left to do once you start scaling your application except write bigger checks to your cloud provider. Any additional resource allocation is easy. The problems that come with scale—fault tolerance, load balancing, traffic shaping—are already handled. At no point will you hit that moment of being overwhelmed with success; you future-proofed your app without too much extra effort.
You can stay (somewhat) cloud agnostic
If your project is successful, chances are that technology decisions made in the early stages will still have an impact months or years down the road. Stack Overflow, for instance, was originally written in C#. 13 years later, it’s still written in C#, but it used to be, too. Occasionally someone (ahem) suggests that we rewrite it in Node.js. That’s still never happened.
The same can be said about dependencies on cloud services. You might build your new app on top of infrastructure as a service (IaaS) products like Amazon’s EC2. Or maybe you’re starting to take dependencies on platform as a service (PaaS) offerings such as Microsoft’s Azure SQL. But are you willing to make a long-term commitment to the cloud providers behind them at this stage? If you don’t know yet where your journey is going to take you, maybe you’d prefer to stay cloud agnostic for a little longer.
Let’s get back to infrastructure as code: throwing a tool such as Terraform into the mix is going to help you with staying cloud agnostic to some degree. It provides a unified toolkit and configuration language (HCL) to manage your resources across different cloud and infrastructure providers. Your app is unlikely to be truly cloud agnostic, however, in the sense that you’ll be able to just switch your cloud provider as easily as your internet or electricity provider at home.
Here’s a good discussion on this topic in HashiCorp’s forum: Is Terraform really cloud agnostic? As one of the commenter points out:
> “A Kubernetes cluster is a good example of an abstraction over compute resources: there are many hosted and self-managed implementations of it on different platforms, all of which offer a common API and common set of capabilities.”
This sums it up nicely! It’s still not a perfect abstraction. For example, each cloud provider is likely to have its own custom way of implementing things like public load balancers and persistent volumes in Kubernetes. It’s still be fair to say if you’re building on Kubernetes, you’re going to stay cloud agnostic to a certain degree.
You can easily spin up new environments—as many as you like!
Kubernetes is usually seen as a way to manage your production infrastructure. But here at Stack Overflow, we’ve been using it to manage our test environments on the fly. We're using Kubernetes to host what we call PR Environments. Every pull request can be run in an isolated test environment at the push of a button:
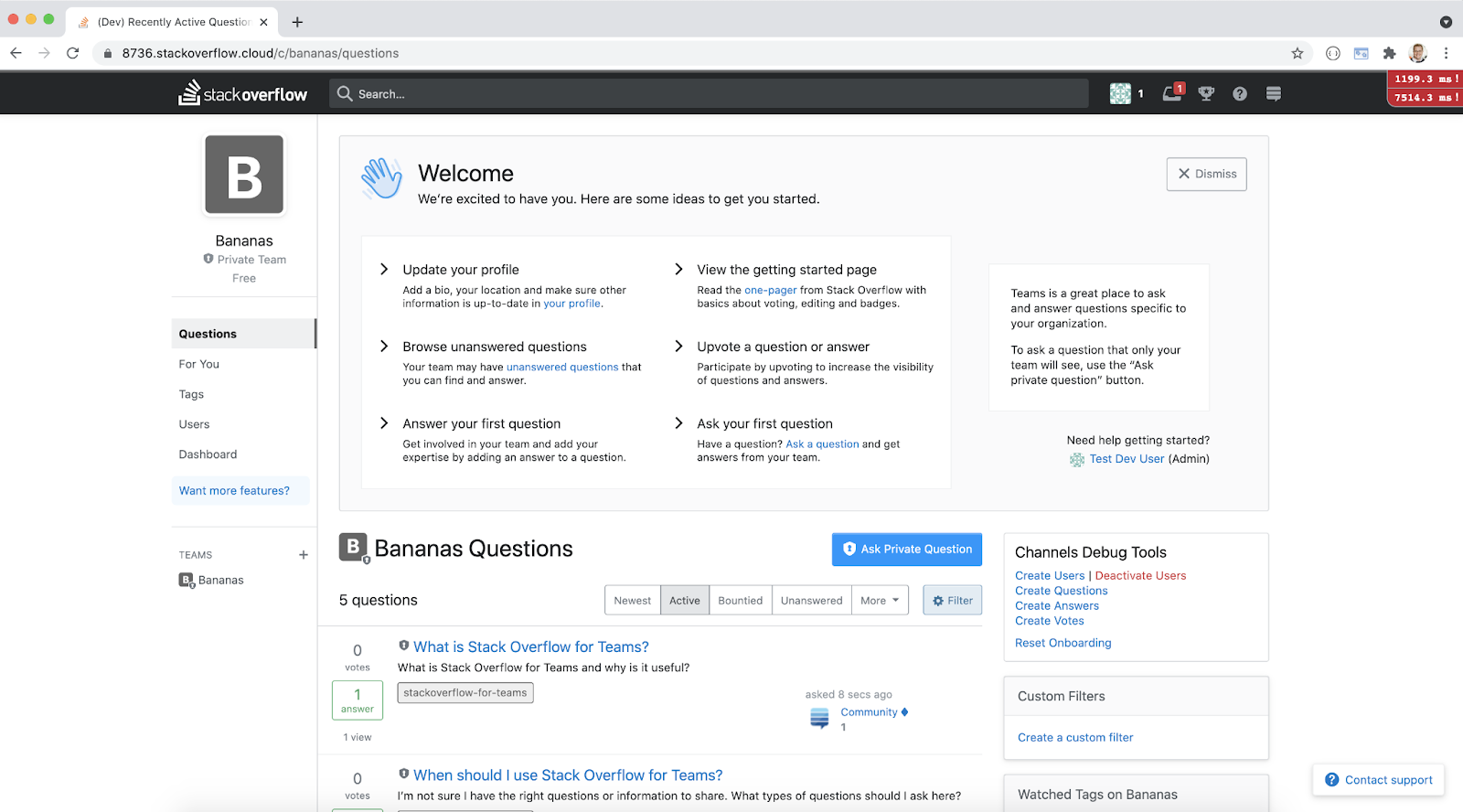
And when we say “isolated environment”, we mean everything: the app itself (with the code changes in the PR branch) with its own dedicated instances of SQL Server, Redis, Elasticsearch, and additional services pieces. All spun up from scratch within minutes and running in a handful of containers in a dedicated namespace, just for you and anyone who’s interested in your PR.
This isn’t something we invented; other organizations have been using this concept. The idea is that every code change goes into a version control system like Git through a pull request. Other developers will review the code, but the code won’t tell the whole story. You want to see the code in action. Normally, you’d have to download all the code locally, compile, and run it. That could be simple, but if you’re running a large application that draws code from multiple repos or—have mercy—a microservice architecture, then you may run into several hours of debugging.
Even better, let’s say you’ve squashed all of the commits for a new feature into a single one and are committing it as a single PR. Send that PR environment to sales or marketing as a single link so that they can preview the feature in action. If your sales team wants to demo the app with specific features or custom builds, send them a PR environment link. You won’t have to spend time walking your less technical colleagues through the build process.
A lot of groundwork was required to get to this point. First off, running classic .NET Framework in Windows Containers wasn’t really an avenue we wanted to pursue. It’s possible in theory—Windows support has been available in Kubernetes since v1.19—but the Docker/Kubernetes ecosystem is really more centered around Linux. Thankfully, our migration to .NET Core was already underway, so we decided to bet on Linux containers.
This, of course, came with its own set of challenges. When you’re dealing with a 10+ year old codebase, you’re likely going to find assumptions about the infrastructure it’s running on: hardcoded file paths (including our favorite: forward slash vs. backslashes), service URLs, configuration, and so on. But we got there eventually, and now we’re in a place where we can spin up an arbitrary number of test instances of Stack Overflow, the Stack Exchange network, and our Teams product on our auto-scaling Kubernetes cluster. What a time to be alive!
Looking back at the early days of Stack Overflow, having this kind of tooling available back then would have been a game changer. In the early stages of building a product, you typically want to build, measure, and learn as much and as fast as possible. Using containers and Kubernetes will allow you to build the tooling for that and future-proof you in case you’re going to scale.
So, should you use Kubernetes from day one? Maybe! It still depends, of course, on your specific project, your requirements, and your priorities.
But have you been saying “we don’t need Kubernetes because we don’t have product market fit yet”? Take a closer look, and maybe you’ll find yourself saying “we need Kubernetes because we don’t have product market fit yet.”