
[Ed. note: While we take some time to rest up over the holidays and prepare for next year, we are re-publishing our top ten posts for the year. Please enjoy our favorite work this year and we’ll see you in 2024.]
One of the more fascinating aspects of large language models is their ability to improve their output through self reflection. Feed the model its own response back, then ask it to improve the response or identify errors, and it has a much better chance of producing something factually accurate or pleasing to its users. Ask it to solve a problem by showing its work, step by step, and these systems are more accurate than those tuned just to find the correct final answer.
While the field is still developing fast, and factual errors, known as hallucinations, remain a problem for many LLM powered chatbots, a growing body of research indicates that a more guided, auto-regressive approach can lead to better outcomes.
This gets really interesting when applied to the world of software development and CI/CD. Most developers are already familiar with processes that help automate the creation of code, detection of bugs, testing of solutions, and documentation of ideas. Several have written in the past on the idea of self-healing code. Head over to Stack Overflow’s CI/CD Collective and you’ll find numerous examples of technologists putting this ideas into practice.
When code fails, it often gives an error message. If your software is any good, that error message will say exactly what was wrong and point you in the direction of a fix. Previous self-healing code programs are clever automations that reduce errors, allow for graceful fallbacks, and manage alerts. Maybe you want to add a little disk space or delete some files when you get a warning that utilization is at 90% percent. Or hey, have you tried turning it off and then back on again?
Developers love automating solutions to their problems, and with the rise of generative AI, this concept is likely to be applied to both the creation, maintenance, and the improvement of code at an entirely new level.
More code requires more quality control
The ability of LLMs to quickly produce large chunks of code may mean that developers—and even non-developers—will be adding more to the company codebase than in the past. This poses its own set of challenges.
“One of the things that I'm hearing a lot from software engineers is they're saying, ‘Well, I mean, anybody can generate some code now with some of these tools, but we're concerned about maybe the quality of what's being generated,’” says Forrest Brazeal, head of developer media at Google Cloud. The pace and volume at which these systems can output code can feel overwhelming. “I mean, think about reviewing a 7,000 line pull request that somebody on your team wrote. It's very, very difficult to do that and have meaningful feedback. It's not getting any easier when AI generates this huge amount of code. So we're rapidly entering a world where we're going to have to come up with software engineering best practices to make sure that we're using GenAI effectively.”
“People have talked about technical debt for a long time, and now we have a brand new credit card here that is going to allow us to accumulate technical debt in ways we were never able to do before,” said Armando Solar-Lezama, a professor at the Massachusetts Institute of Technology’s Computer Science & Artificial Intelligence Laboratory, in an interview with the Wall Street Journal. “I think there is a risk of accumulating lots of very shoddy code written by a machine,” he said, adding that companies will have to rethink methodologies around how they can work in tandem with the new tools’ capabilities to avoid that.
We recently had a conversation with some folks from Google who helped to build and test the new AI models powering code suggestions in tools like Bard. Paige Bailey is the PM in charge of generative models at Google, working across the newly combined unit that brought together DeepMind and Google Brain. “Think of code produced by an AI as something made by an “L3 SWE helper that's at your bidding,” says Bailey, “and that you should really rigorously look over.”
Still, Bailey believes that some of the work of checking the code over for accuracy, security, and speed will eventually fall to AI as well. “Over time, I do have the expectation that large language models will start kind of recursively applying themselves to the code outputs. So there's already been research done from Google Brain showing that you can kind of recursively apply LLMs such that if there's generated code, you say, “Hey, make sure that there aren't any bugs. Make sure that it's performant, make sure that it's fast, and then give me that code,” and then that's what's finally displayed to the user. So hopefully this will improve over time.”
What are people building and experimenting with today?
Google is already using this technology to help speed up the process of resolving code review comments. The authors of a recent paper on this approach write that, “As of today, code-change authors at Google address a substantial amount of reviewer comments by applying an ML-suggested edit. We expect that to reduce time spent on code reviews by hundreds of thousands of hours annually at Google scale. Unsolicited, very positive feedback highlights that the impact of ML-suggested code edits increases Googlers' productivity and allows them to focus on more creative and complex tasks.”
“In many cases when you go through a code review process, your reviewer may say, please fix this, or please refactor this for readability,” says Marcos Grappeggia, the PM on Google’s Duet coding assistant. He thinks of an AI agent that can respond to this as a sort of advanced linter for vetting comments. “That's something we saw as being promising in terms of reducing the time for this fix getting done.” The suggested fix doesn’t replace a person, “but it helps, it gives kind of say a starting point for you to think from.”
Recently, we’ve seen some intriguing experiments that apply this review capability to code you’re trying to deploy. Say a code push triggers an alert on a build failure in your CI pipeline. A plugin triggers a GitHub action that automatically send the code to a sandbox where an AI can review the code and the error, then commit a fix. That new code is run through the pipeline again, and if it passes the test, is moved to deploy.
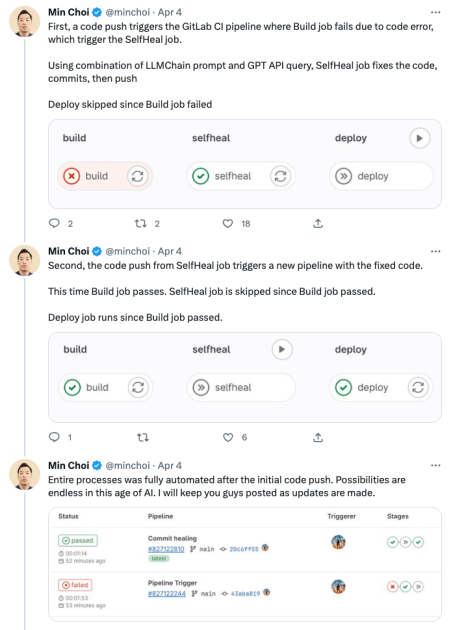
“We made several improvements in the mechanism for the retry loop so you don’t end up in a weird scenario, but that’s the essential mechanics of it,” explains Calvin Hoenes, who created the plugin. To make the agent more accurate, he added documentation about his code into a vector database he spun up with Pinecone. This allows it to learn things the base model might not have access to and to be regularly updated as needed.
Right now his work happens in the CI/CD pipeline, but he dreams of a world where these kind of agents can help fix errors that arise from code that’s already live in the world. “What's very fascinating is when you actually have in production code running and producing an error, could it heal itself on the fly?” asks Hoenes. “So you have your Kubernetes cluster. If one part detects a failure, it runs into a healing motion.”
One pod is removed for repairs, another takes its place, and when the original pod is ready, it’s put back into action. For now, says Hoenes, we need humans in the loop. Will there come a time when computer programs are expected to autonomously heal themselves as they are crafted and grown? “I mean, if you have great test coverage, right, if you have a hundred percent test coverage, you have a very clean, clean codebase, I can see that happening. For the medium, foreseeable future, we probably better off with the humans in the loop.”
Pay it forward: linters, maintainers, and the never ending battle with technical debt
Finding things during CI/CD or addressing bugs as they arise is great, but let’s take things a step further. You work at a company with a large, ever-growing code base. It’s fair to assume you’ve got some level of technical debt. What if you had an AI agent that reviewed old code and suggested changes it thinks will make your code run more efficiently. It might alert you to fresh updates in a library that will benefit your architecture. Or it might have read about some new tricks for improving certain functions in a recent blog or documentation release. The AI’s advice arrives each morning as pull requests for a human to review.
Itamar Friedman, CEO of CodiumAI, currently approaches the problem while code is being written. His company has an AI bot that works as a pair programmer alongside developers, prompting them with tests that fail, pointing out edge cases, and generally poking holes in their code as they write, aiming to ensure that the finished product is as bug free as possible. He says a lot of tools for measuring code quality focus on aspects like performance, readability, and avoiding repetition.
Codium works on tools that allow for testing of the underlying logic, what Friedman sees as a narrower definition of functional code quality. With that approach, he believes automated improvement of code is now possible, and will soon be fairly ubiquitous. “If you're able to verify code logic, then probably you can also help, for example, with automation of pull requests and verifying that these are done according to best practices.”
Itamar, who has contributed to AutoGPT and has given talks with its creator, sees a future in which humans guide AI, and vice versa. “A machine would go over your entire repository and tell you all of the best (and so-so) practices that it identified. Then a few tech leads can go over this and say, oh my gosh, this is how we wanted to do it, or didn't want to do it. This is our best practice for testing, this is our best practice for calling APIs, this is how we like to do the queuing, this is how we like to do caching, etc. It'll be configurable. Like the rules will actually be a mix of AI suggestion and human definition that will then be used by an AI bot to assist developers. That's the amazing thing.”
How is Stack Overflow experimenting with GenAI?
As our CEO recently announced, Stack Overflow now has an internal team dedicated to exploring how AI, both the latest wave of generative AI and the field more broadly, can improve our platforms and products. We’re aiming to build in public so we can bring feedback into our process. In the spirit, we shared an experiment that helped users to craft a good title for their question. The goal here is to make life easier for both the question asker and the reviewers, encouraging everyone to participate in the exchange of knowledge that happens on our public site.
It’s easy to imagine a more iterative process that would tap in the power of multi-step prompting and chain of thought reasoning, techniques that research has shown can vastly improve the quality and accuracy of an LLM’s output.
An AI system might review a question, suggest tweaks to the title for legibility, and offer ideas for how to better format code in the body of the question, plus a few extra tags at the end to improve categorization. Another system, the reviewer, would take a look at the updated question and assign it a score. If it passes a certain threshold, it can be returned to the user for review. If it doesn’t, the system takes another pass, improving on its earlier suggestions and then resubmitting its output for approval.
We are lucky to be able to work with colleagues at Prosus, many of whom have decades of experience in the field of machine learning. I chatted recently with Zulkuf Genc, Head of Data Science at Prosus AI. He has focused on Natural Language Processing (NLP) in the past, co-developing an LLM-based model to analyze financial sentiment, FinBert, that remains one of the most popular models at HuggingFace in its category.
“I had tried using autonomous agents in the past for my academic research, but they never worked very well, and had to be guided by more rules based heuristics, so not truly autonomous,” he told me in an interview this month. The latest LLMs have changed all that. We are at the point now, he explained, where you can ask agents to perform autonomously and get good results, especially if the task is specified well. “In the case of Stack Overflow, there is an excellent guide to what quality output should look like, because there are clear definitions of what makes a good question or answer.”
What about you?
Developers are right to wonder, and worry, about the impact this kind of automation will have on the industry. For now, however, these tools augment and enhance existing skills, but fall far short of replacing actual humans. It appears some of bots have already learned to automate themselves into a loop and out of a job. Tireless agents that are always working to keep your code clean. I guess we’re lucky that so far they seem to be as easily distracted by time consuming detours as the average human developer?
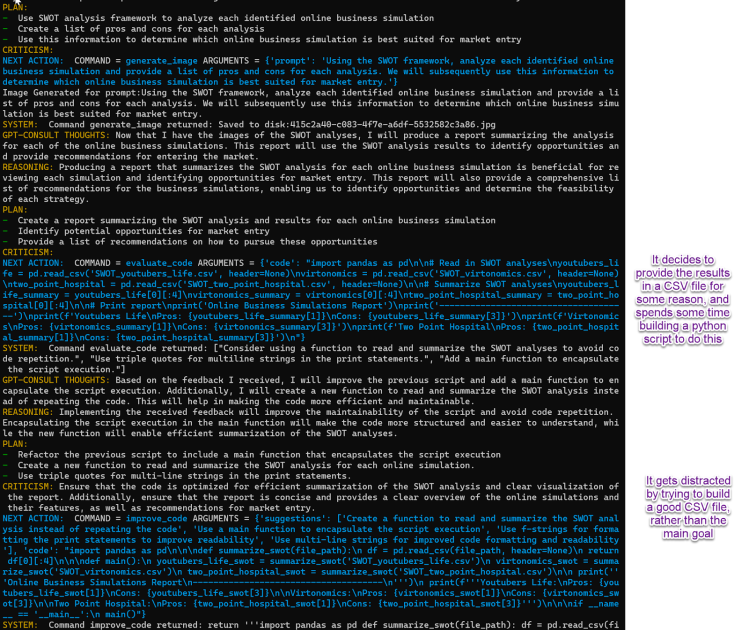
Technology marches on, but procrastination remains unbeaten.
We are compiling the results from our Developer Survey and have tons of fascinating data to share on how developers view these tools and the degree to which they are already adopting them into their workflows.
If you’ve been playing around with ideas like this, from self-healing code to Roboblogs, leave us a comment and we’ll try and work your experience into our next post. And if you want to learn more about what Stack Overflow is doing with AI, check out some of the experiments we’ve shared on Meta.