
SPONSORED BY KOVE
Edge computing opportunities continue apace. To name just a few: smart cities, linked smart-cities; self-driving vehicles interacting autonomously in local, regional, and national contexts; real-time IoT devices creating trillions of self-organizing relationships within or across cities; industrial equipment monitoring and adapting in microseconds and soon nanoseconds; massive graphs computed on boats; and machine-driven lab-generated drug design.
How does an organization satisfy local latency across satellite distances with small form factor but enormous need? It is my pleasure to share the results that Supermicro, Red Hat, and Kove measured for edge computing, with a solution that addresses the most vexing complexity challenges facing today’s edge: power, precision compute, dynamism, agility, cost, scale, and not least latency of the local machine. What follows are excerpts of the Supermicro solutions brief, results that prove out our ambitious claims.
AI and enterprise data sets are exploding in size. Processing that data is most efficient when all the data is fully resident in DRAM, avoiding the need to process the data in blocks or constantly page data to disk storage. However, while processor core counts are increasing, memory capacity and bandwidth are not scaling proportionally.
To enable the broadest set of virtualized applications, servers are being built with the maximum possible memory, limited only by the physical PCB real estate. However, there is a dichotomy: Increasing memory size addresses memory-intensive applications and increases costs and the probability of stranding memory. Meanwhile, to protect against possible server crashes, memory is often under-utilized, so you don’t run out of it.
As a result, while many applications can benefit from more memory than can be provisioned on a single server node, many servers have underutilized memory, depending on workload.
Options for effective memory use
Effective memory can be increased by accessing memory offboard the server, often by paging to block storage. The problem: This results in a massive slowdown. It could be up to 125 times slower, even using the fastest SSDs. The outcome: A four-hour job running in SWAP could take more than 20 days to complete, rendering certain workloads impractical.
A common workaround is to rewrite the application to process the data in manageable chunks and then assemble the result. But this approach is fraught with numerous problems as it is error prone, creates developer costs, and may not solve the run-time issues.
What is needed is a way to improve direct access to offboard memory by providing on-demand access to memory across servers. The industry has recognized this and has been working on a software-defined memory solution for many years in the form of CXL. However, CXL 3.0, which provides complete caching capability, is still several years away, will require new server architecture, and will only be available in forthcoming generations of hardware.
Concerns about latency compromises are surfacing, too. Even CXL 3.0 is still piggybacking on the PCI Express (PCIe) physical layer and relying on physical memory paired with PCIe, so one would ordinarily incur a penalty on a key critical metric—latency. Generally, the farther the memory is from the CPU, the higher the latency and the poorer the performance.
Workloads at the heart of everything from HPC to AI have significant memory requirements. But designers struggle to make use of the additional cores available in modern CPUs.
The leap forward in the number of CPU cores is mismatched with a lack of memory bandwidth. And it continues to worsen due to the limited physical space to incorporate more memory and the limited access to additional memory beyond the motherboard.
To embrace scaling, memory must be moved outside of the server. Yet current options that include block storage and cloud services aren’t viable solutions.
Software-defined memory solved
Meanwhile, software-defined memory helps ease pressure on DRAM while increasing computing efficiency and performance. This subset of software-defined technologies is unlocking a new age of disaggregated memory, mirroring the revolution that came with disaggregated storage.
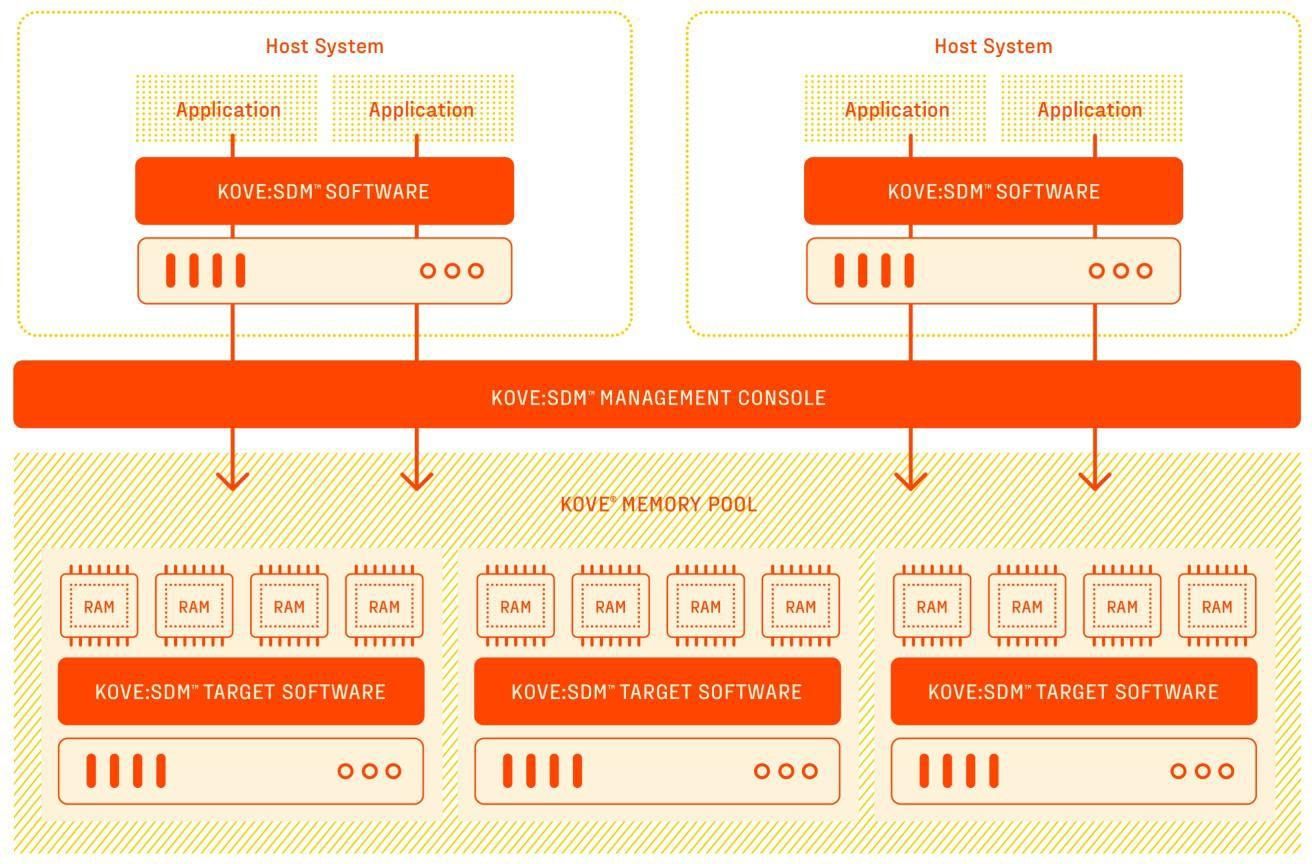
Our version of pooled or software-defined memory, Kove:SDM™, empowers individual servers to draw from a shared memory pool, including amounts far larger than could be contained within any physical server, so each job receives the memory it needs while reducing power consumption.
For instance, you can allocate 10x 64 GiB for ten containers on a compute node with only 64 GiB of memory, create containers with larger memory than the physical hypervisor, or burst to allocate 40 TiB to a single server for an hour. Control memory in real-time, on-demand, using easy-to-configure provisioning rules. Memory capacity scales up to CPU addressable limits beyond the limits of local physical DIMM slots.
Kove:SDM™ solves memory stranding by pooling memory into a global resource, shareable and reusable across the data center. In other words, it decouples or “disaggregates” memory from standard servers, aggregating memory into a shared memory pool resource. SDM policies then structure the access to the memory pool. After use, it securely zeros out and returns memory to the pool for reuse. As a result, it also provides strong security against attacks targeting memory penetration.
Works with any server
Unlike CXL, no special chips or hardware are required to run Kove:SDM™. Rather, it decouples memory from servers, pooling memory into an aggregate, provisionable, and distributable resource across the data center using unmodified Supermicro hardware.
Like a storage area network (SAN) provisioning storage using policies, Kove:SDM™ delivers a RAM area network (RAN) that provisions memory using policies. Both provide a global, on-demand resource exactly where, when, and how it is needed. For example, an organization might:
- Use a Kove:SDM™ policy to allocate up to 2 TiB of need-based memory for any of 200 servers between 5 pm-8:30 pm;
- Develop a provisioning rule that would provision a virtual machine with larger memory than the physical hypervisor, such as a 64 GiB RAM physical server (hypervisor) hosting a 512 GiB RAM virtual machine; and
- Provision a 40 TiB server for a few hours or a 100 TiB RAM disk with RAID backing store for a temporary burst ingest every morning.
To achieve these outcomes, Kove:SDM™ uses three transparent software components: 1) Management Console (MC) that orchestrates memory pool usage; 2) Host Software that connects applications to a memory pool; and 3) XPD software that converts servers into memory targets to form a memory pool. Users and applications do not ever need to know that it is present.
We should note that our software-defined memory is applicable across a wide range of computing:
- AI/ML - Provision resources to the model rather than forcing models to fit fixed resources. Enjoy deeper and faster lookups, analytics, and iterations. Improve your time on the solution and your return on your data scientists.
- In-memory databases - Analyze databases 100s of times larger than physical servers.
- Containers - Improve CPU utilization. Run more jobs in parallel on a single server, increasing workload capability by 20x. Gain the ability to run 7.5x more C3.ai containers.
- High-performance computing - Run big data analytics, genomics, and Monte Carlo computations entirely in memory. Build trading systems in Java with <11 μs risk exposure. Use standard servers to create any size memory server on demand (e.g., 32-256 TiB in a few seconds).
- Enterprise, cloud, and edge - Enables unlimited memory sizing. Any size computation can run entirely in memory. Achieve your green goals through 52% CO2 reduction and 33% floor space reductions. Create a hybrid cloud to keep sensitive data on-premises without cost and scaling concerns. Reduce your power consumption needs by 50%. Greater utilization makes edge computing financially viable.
To demonstrate what our software-defined memory solution can do (beyond what we have seen from our customers’ proprietary testing), we partnered with Supermicro and Red Hat to benchmark a large in-memory application using our software-defined memory solution spanning a multi-node cluster running Red Hat OpenShift on Supermicro BigTwin servers.
This combination of Red Hat OpenShift with the Supermicro BigTwin systems provides additional performance, reliability, and resource utilization advantages. The Supermicro BigTwin 2U 4-Node form factor offers the most reliable three-node cluster with an extra node as a bastion node in one chassis. Supermicro’s BigTwin system with high-density and high-storage options compliments OpenShift’s capabilities by providing a robust and scalable foundation to run containerized workloads.
Massive memory technical implementation
The logical diagram for our collaborative proof of concept is shown below. It shows two host computers running the applications and three Kove® memory targets. However, our software-defined memory scales linearly and is limited only by the network interconnect infrastructure that customers provide. Kove:SDM™ software allocates memory on demand and as needed to the Application Hosts.
The actual physical system for our collaborative proof of concept was implemented using two Supermicro 2U 4-Node BigTwin systems.
- The first host was running Red Hat OpenShift bare-metal with three nodes as control plane/compute nodes for the application host and a single node as a bastion node to access the control plane/compute nodes and provision them with the DNS server for the rest of the nodes and run the Kove:SDM™ management console.
- The second 2U 4-Node Supermicro BigTwin system ran the Kove® software. Each node was equipped with 1TB of memory per node, enabling Kove:SDM™ to leverage the combined memory pool across the four nodes. This system will provide additional memory resources to any control plane/compute nodes as needed.
- In the proof-of-concept, we used one 2U 4-Node Supermicro BigTwin for the targets. Additional targets can easily be added, as represented in this diagram.
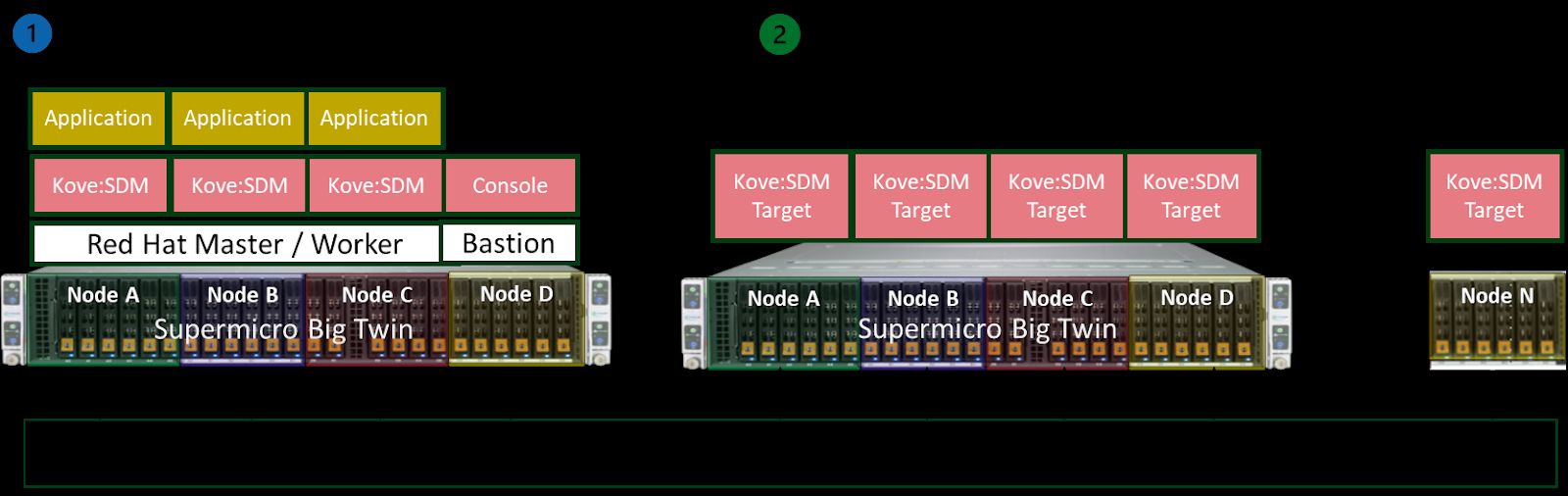
1. Most reliable OpenShift cluster in a single chassis:
- The optimal number of nodes to create a small viable OpenShift cluster.
- Run once, run anywhere with Red Hat OpenShift.
- 1x bastion node to access the rest of the nodes and 3x worker/master nodes in a single chassis.
- Fully optimized containerized environment to build and deploy cloud-native applications.
2. High density for a larger pool of memory with the Kove® software:
- Four nodes fully loaded with memory to provision more memory to client nodes
- Kove® software running to monitor memory resources
- Kove® target memory will automatically provision memory to any workload if necessary
- Workloads that need large amounts of memory will take full advantage of the software-defined memory technology that Kove offers.
Proof-of-concept testing
During the testing phase, we subjected various scenarios to stress this environment using stress-ng. This tool facilitated targeted stress on the CPU and memory, enabling us to gather essential data for evaluating the compatibility and performance of Kove:SDM™ with Red Hat OpenShift.
Each scenario involved adjusting the CPU governor from performance to power save, with memory operated at different frequencies for each CPU governor setting.
The initial phase involved stressing the system using local memory, while the second phase involved reducing physical memory to allow dynamic memory allocation by Kove:SDM™ to the control plane/compute nodes requiring more memory than physically available. In total, the tests were executed with 16 scenarios, each repeated seven times to ensure accurate data collection across 2.165 quadrillion results averaged.
This proof of concept validated the seamless compatibility of Kove:SDM™ and Red Hat OpenShift in handling containerized workloads. Additionally, the test demonstrated the significant benefits offered by Kove:SDM™ in scenarios where workloads require memory capacities exceeding physical limitations while exhibiting minimal to no performance penalty.
Benchmark results
Combined with Intel CPU governor settings, Kove:SDM™ provided 12 to 54% power savings, illustrated in Figure 3.
Figure 3 Power Savings with Kove:SDM™
Conclusion
Across quadrillions of results, tests measured that Kove:SDM™ software
dynamically and transparently delivers virtualized memory across Red Hat Software on Supermicro hardware. This all happens without changing code, or worrying about the MHz speed of memory, or whether memory is on-board or not, or worrying about hardware limits. Without changing latency temperament compared to local memory, Kove:SDM™,
Supermicro, and Red Hat delivered 12-54% power savings. We believe this will allow developers to build impressive new applications in the unforgiving context of restricted power on the edge, without concerns for latency or performance.
If you’d like to read the complete solutions brief from Supermicro that details the benchmarking, you can find it here.
If you’d like to see for yourself the enhanced performance and energy savings that pooled memory can deliver for your enterprise, Kove is offering a 30-day free trial of Kove:SDM™. Contact us here to get started.