New language models get released every day (Gemini-1.5, Gemma, Claude 3, potentially GPT-5 etc. etc.), but one component of LLMs has remained constant over the last few years—the decoder-only transformer architecture.
Why should we care? Research on LLMs moves fast. Shockingly, however, the architecture used by most modern LLMs is pretty similar to that of the original GPT model. We just make the model much larger, modify it slightly, and use a more extensive training (and alignment) process. For this reason, the decoder-only transformer architecture is one of the most fundamental/important ideas in AI research, so investing into understanding it deeply is a wise idea.
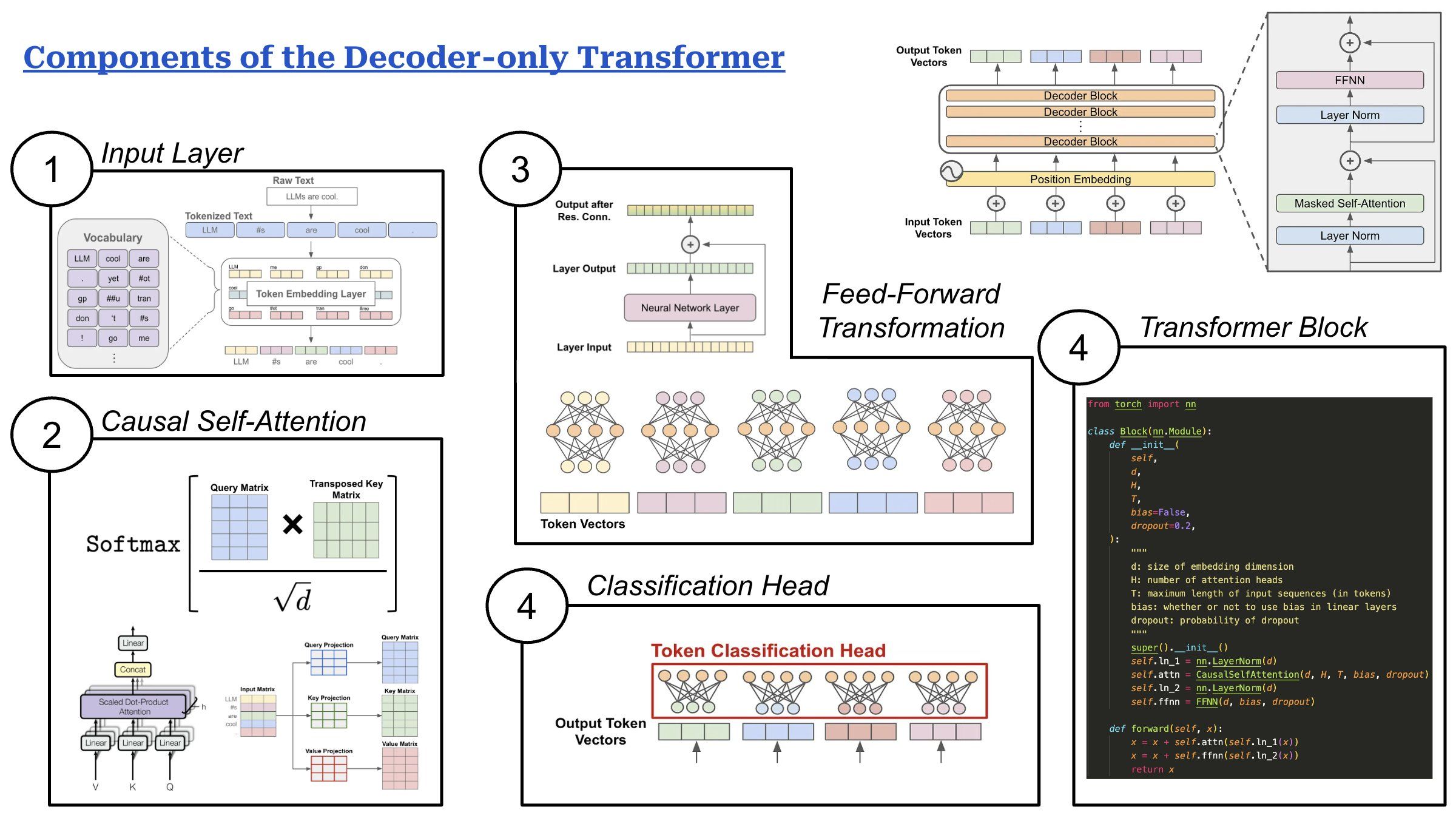
This architecture has five components:
(1) Input layer: Decoder-only transformers receive a textual prompt as input. We use a tokenizer—based upon an algorithm like Byte-Pair Encoding (BPE)—to break this text into discrete tokens (i.e., words or sub-words). Then, we map each of these tokens to a corresponding vector stored in an embedding layer. This process forms a sequence of token vectors that are passed to the model as input. Optionally, we can augment these token vectors with additive positional embeddings.
(2) Causal self-attention is the core of the decoder-only transformer and allows the model to learn from relationships between tokens in the input. The vanilla self-attention operation transforms each token’s representation by taking a weighted combination of other token representations, where weights are given by pairwise attention/importance scores between tokens. Causal self-attention follows a similar strategy but only computes attention scores for preceding tokens in the sequence. Attention is performed in parallel across several heads (i.e., multi-head attention), each of which can focus upon different parts of the input sequence.
(3) Feed-forward transformations are performed within each block of the decoder-only transformer, allowing us to individually transform each token’s representation. This feed-forward component is a small neural network that is applied in a pointwise manner to each token vector. Given a token vector as input, we pass this vector through a linear projection that increases its size by ~4X, apply a non-linear activation function (e.g., SwiGLU or GeLU), then perform another linear projection that restores the original size of the token vector.
(4) Classification head: The decoder-only transformer has one final classification head that takes token vectors from the transformer’s final output layer as input and outputs a vector with the same size as the vocabulary of the model’s tokenizer. This vector can be used to either train the LLM via next token prediction or generate text at inference time via sampling strategies like nucleus sampling and beam search.
(5) Transformer blocks form the body of the decoder-only transformer architecture. The exact layout of the decoder-only transformer block may change depending upon the implementation, but two primary sub-layers are always present:
1. Causal self-attention
2. Feed-forward transformation
Additionally, these sub-layers are surrounded by a layer normalization module—either before or after the sub-layer (or both!)—as well as a residual connection.