TL;DR: Self-supervised learning is a key advancement in deep learning that is used across a variety of domains. Put simply, the idea behind self-supervised learning is to train a model over raw/unlabeled data by making out and predicting portions of this data. This way, the ground truth “labels” that we learn to predict are already present in the data itself and no human annotation is required.
Types of learning. Machine learning models can be trained in a variety of ways. For example, supervised learning trains a machine learning model over pairs of input data and output labels (usually annotated manually by humans). The model learns to predict these output labels by supervising the model (i.e., showing it several examples of input data with the correct output)! On the other hand, unsupervised learning uses no output labels and discovers inherent trends within the input data itself (e.g., by forming clusters).
“Self-supervised learning obtains supervisory signals from the data itself, often leveraging the underlying structure in the data. The general technique of self-supervised learning is to predict any unobserved or hidden part (or property) of the input from any observed or unhidden part of the input.” - from Self-supervised learning: The dark matter of intelligence
What is self-supervised learning? Self-supervised learning lies between supervised and unsupervised learning. Namely, we train the model over pairs of input data and output labels. However, no manual annotation from humans is required to obtain output labels within our training data—the labels are naturally present in the raw data itself! To understand this better, let’s take a look at a few commonly-used self-supervised learning objectives.
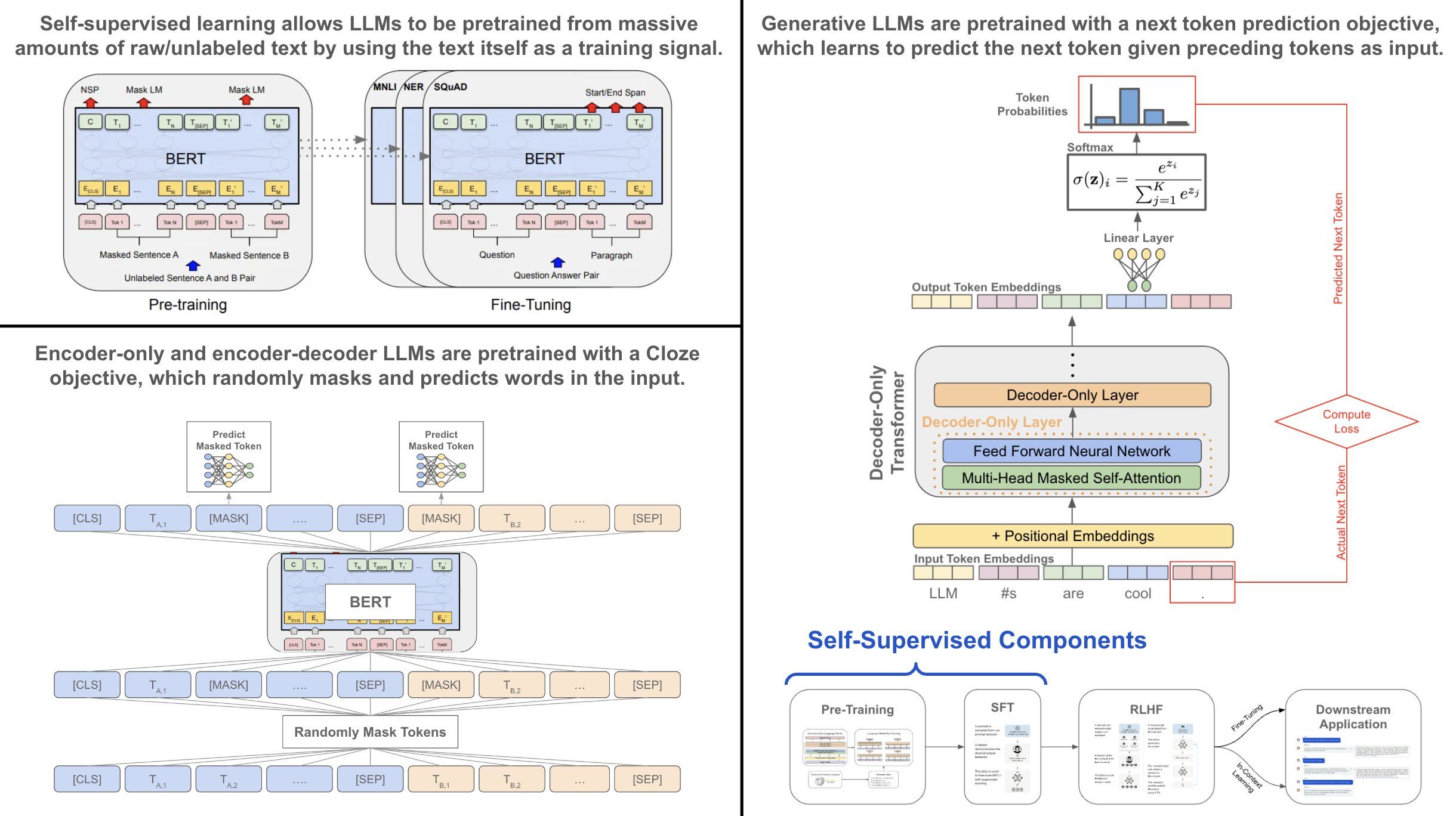
(1) The Cloze task is more commonly referred to as the masked language modeling (MLM) objective. Here, the language model takes a sequence of textual tokens (i.e., a sentence) as input. To train the model, we mask out (i.e., set to a special “mask” token) ~10% of tokens in the input and train the model to predict these masked tokens. Using this approach, we can train a language model over an unlabeled textual corpus, as the “labels” that we predict are just tokens that are already present in the text itself. This objective is used to pretrain language models like BERT and T5.
(2) Next token prediction is the workhorse of modern generative language models like ChatGPT and PaLM. After downloading a large amount of raw textual data from the internet, we can repeatedly i) sample a sequence of text and ii) train the language model to predict the next token given preceding tokens as input. This happens in parallel for all tokens in the sequence. Again, all the “labels” that we learn to predict are already present in the raw textual data. Pretraining (and finetuning) via next token prediction is universal used by all generative language models.
Other options exist too! Although Cloze and next token prediction are the most commonly-used self-supervised objectives for training language models, many examples of self-supervised learning exist. For example, many self-supervised objectives exist for video deep learning models (e.g., predicting the next frame), and BERT models also use a self-supervised next-sentence prediction objective.