
Every IDS deployment has a gap. Anyone who has run one long enough eventually finds it, usually at the worst possible time. The gap sits between what you wrote rules for and what the attacker chose to do instead. Classic Snort signatures are genuinely impressive instruments. A well-crafted rule can catch a known exploit with near-zero false positives and overhead that barely registers on a profiler. That precision comes from specificity, and specificity is the whole problem. Write a rule for CVE-2024-12345 and you have coverage for that CVE. A modified payload that clears the same vulnerable code path by a slightly different route? Nothing fires.
That is not a criticism of the signature model. It works exactly as designed. Signatures encode specific, verifiable knowledge about what an attack looks like at the wire level, and the low false positive rate is a direct product of that specificity. The real constraint is something harder to solve: exposure time. Between the moment a novel exploit surfaces in the wild and the moment a researcher captures it, reverse-engineers it, writes a rule, validates that rule against a test corpus, and ships it through an update channel, days or weeks can pass. For actively exploited vulnerabilities in common software, that window is not hypothetical.
Cisco Talos addressed this directly in March 2024 with SnortML, a machine learning detection engine running natively inside Snort 3. Around the same time, a broader transformation in security operations started gaining serious traction: agentic AI entering network defense. These two developments operate at different layers of the same shift, and examining them together reveals something that looking at either one in isolation does not.
Part 1: What SnortML Actually Does
Before architecture and implications, the mechanics matter. SnortML is not a generic anomaly scorer tacked onto Snort's alert output, and it is not a cloud reputation service that phones home on every request. The inference happens entirely on the local device, inside the same processing pipeline as normal rule evaluation, and it produces a verdict in under a millisecond.
Two components make this work. The snort_ml_engine module handles model loading at startup, bringing pre-trained TensorFlow models into memory and making them available as classifiers throughout the session. The snort_ml inspector then subscribes to data feeds from Snort's existing service inspectors through the publish/subscribe interface Snort 3 already uses internally. When the HTTP inspector finishes parsing a request, it publishes the URI query string and POST body to the event bus. The SnortML inspector picks that up, runs it through the classifier, and returns a float representing the probability that the content contains an exploit attempt.
The neural network does not need to have seen a specific attack to flag it. It has learned the shape of what SQL injection attempts look like at the byte level, and that shape holds across a wide range of syntactic variations.
The model architecture is an LSTM preceded by an embedding layer. The embedding layer maps raw byte values to learned vector representations, which captures relationships between bytes in a way that pure frequency analysis cannot. Think of it as analogous to word embeddings in NLP, except the tokens are bytes rather than words. A byte value of 0x27 (apostrophe) sitting next to 0x4F 0x52 (OR) carries learned context about SQL injection patterns, and the embedding layer encodes that. The LSTM then processes these sequences and captures temporal structure: the ordering of bytes matters, and attack payloads tend to have characteristic orderings that distinguish them from legitimate query strings.
A final dense layer collapses the LSTM's output to a single probability float. LibML, the inference library shipped with SnortML, uses XNNPACK for hardware-accelerated matrix operations that keep inference time predictable under load. On a 4.7 GHz AMD processor, a single classification pass runs in roughly 350 microseconds. One practical detail worth knowing: from Secure Firewall 10.0.0 onward, SnortML automatically selects between models sized for 256, 512, or 1024 byte inputs based on the actual query length. Short queries get the lighter model. Only the longer, more complex requests go through full-sized inference. For queries exceeding 1024 bytes, the input gets truncated to that boundary before classification, which is a behavior worth keeping in mind when working with applications that generate unusually long parameter strings.
The initial release targeted SQL injection detection. By late 2025, coverage expanded to include XSS and command injection attack classes. Model updates arrive through Snort's Lightweight Security Package system, using the same update channel as rule content, which means SnortML stays current without requiring a separate update workflow.
TECHNICAL NOTE: ADAPTIVE MODEL SELECTION
The 256/512/1024-byte model selection is not just a performance optimization. Each model was trained on a distribution of inputs at that length range, so the smaller model is genuinely calibrated for short queries rather than being a truncated version of the full model. This matters when reasoning about false positive behavior: a 200-byte legitimate query that looks slightly injection-like will be scored by the 256-byte model, which has seen a more concentrated distribution of short query traffic during training. Understanding which model variant fires on a given alert helps when tuning threshold behavior.
The diagram below shows how this sits inside Snort's packet processing pipeline. The SnortML classifier runs in parallel with traditional signature matching. Pay attention to where the two paths diverge from the inspector dispatch and where they converge at the verdict stage: either path can independently trigger an alert, and a detection where both paths fire simultaneously carries meaningfully higher confidence than one triggered by ML alone.
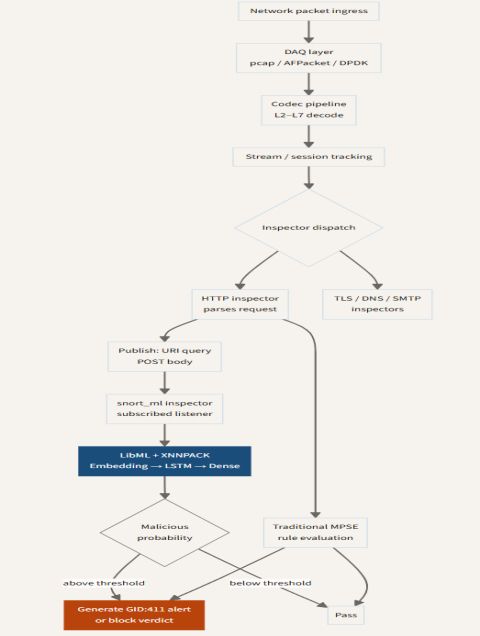
Why does the parallel architecture matter?
SnortML does not replace signature evaluation. Running both in parallel is a deliberate engineering decision, not a transitional compromise. A neural network trained on a vulnerability class will occasionally misfire on legitimate traffic that resembles attack syntax. URL-encoded special characters in a legitimate database query are a common case. Running signatures alongside the ML model means the two mechanisms provide independent coverage with different error profiles: the ML catches novel variants that no signature exists for, while classical matching provides a low-noise floor for known patterns. When both fire on the same payload, that correlation is meaningful signal for downstream systems.
Latency impact was tested carefully. The 350-microsecond overhead is real and needs to be understood in context. A high-throughput Snort deployment on a current Cisco Secure Firewall appliance operates with a per-packet processing budget ranging from low hundreds of microseconds to a few milliseconds, depending heavily on ruleset size and protocol complexity. Adding 350 microseconds is not negligible. That is precisely why XNNPACK acceleration matters: it keeps the ML overhead predictable and bounded rather than variable under load.
Part 2: The limits of embedded ML and why agents come next
SnortML is a focused engineering solution to a specific problem. That focus is a strength and a limitation at the same time. It catches zero-day exploit variants within known vulnerability classes, on-device, with no external dependency. Within that scope, it works well. The scope itself is where things get interesting.
The classifier operates on individual HTTP parameters. A single URI query string or POST body comes in, gets scored, and either triggers or does not. The model has no visibility into what came before that request, after it, or from the same source IP over the previous twenty minutes. Consider a simple three-request sequence: a probe request to map the application's input validation behavior, an enumeration request to identify injectable parameters, and finally the exploit attempt tailored to what the first two probes revealed. Each request, looked at individually, might score below threshold. The third request in that chain is more dangerous precisely because of the first two, and SnortML cannot see that relationship.
The same boundary applies to anything outside HTTP parameter space. DNS tunneling exfiltration, TLS-layer protocol attacks, SMB exploitation, timing-based covert channels, protocol behavioral anomalies in non-HTTP services: none of these pass through the HTTP inspector publish path, so SnortML never sees them. The architecture could accommodate other inspectors, and the publish/subscribe interface is generic enough for that. But trained models for those data sources do not exist yet, and assembling the labeled training corpora for less studied protocols is considerably harder than it was for HTTP.
None of this is a bug. These are the natural constraints of any detection system that operates at the per-packet, per-parameter level. Getting past them requires a different kind of reasoning: one that holds context across time, correlates signals from multiple observation points, and does not wait for a human to read a report before acting. That is what agentic AI in security operations is built to do.
The diagram below shows how different detection approaches cover different layers of the attack surface. SnortML sits at the wire level, extending Snort's reach from known patterns into zero-day variants. Agentic reasoning operates at a higher abstraction layer where temporal context and cross-source correlation become the primary tools.
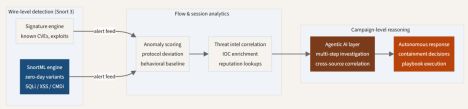
Part 3: What agentic AI means for network defense
The term "agentic AI" has been applied so broadly in security marketing that it risks losing meaning entirely. It is worth being precise about what actually separates an AI agent from a conventional ML model or an automated SOAR playbook.
A conventional ML model scores what is in front of it. No memory of prior inputs, no ability to go gather more context, no mechanism to decide what should happen next with its output. A SOAR playbook takes a different approach: a fixed sequence of steps triggered by an alert condition, with each step predefined. If the situation falls outside the playbook's anticipated branches, the automation stops and kicks to a human. Both of these have real value. Neither of them is an agent.
An AI agent maintains state across a multi-step investigation. It decides what to examine next based on what it has already found, rather than following a predetermined sequence. It calls tools: querying a SIEM for related events, looking up a file hash against a threat intelligence platform, pulling a flagged user's recent activity from an identity provider, checking whether a source IP appears in BGP-level blacklists. Each lookup informs what comes next. When the investigation reaches a point where response is warranted, the agent can either execute or hand off with enough assembled context that a human reviewing its recommendation needs seconds rather than hours.
The commercial security industry has been building toward this for roughly two years. IBM launched ATOM, the Autonomous Threat Operations Machine, in April 2025, framing it as a multi-agent framework sitting above SIEM analytics to handle investigation and remediation workflows. Trend Micro released their Agentic SIEM in August 2025, designed from the ground up around autonomous correlation and investigation. These are not conversational interfaces with security domain knowledge attached. They are orchestration platforms where specialized agents divide investigation work along functional lines and pass structured findings between each other.
The SOC analyst shortage is the real driver
The pace of adoption makes more sense when you look at the labor market. The global cybersecurity workforce gap sits around four million unfilled positions. A 2025 survey found 82% of SOC analysts reporting concern about missing real threats due to alert volume alone. Those numbers describe a system under structural pressure that tooling has not resolved. Adding another detection capability without changing how triage and investigation work generates more alerts, not better outcomes. Agentic AI is being adopted not because it is theoretically elegant but because the alternative, more analysts reading through more alerts, is not a viable scaling path.
Snort 3 as the sensor layer in an agentic stack
In this picture, Snort 3 with SnortML occupies a specific and important role: the sensor. The closest point to the actual wire, running at packet speed, producing a continuous stream of events that represent what was definitively observed on the network. That event stream is the ground truth that higher-level reasoning builds on.
That positioning is worth more in an agentic architecture than in a traditional SOC. In a traditional setup, Snort alerts reach a SIEM and analysts triage them. The analyst is also the error-correction layer: they read context, decide if an alert merits investigation, and chase it manually. In an agentic architecture, Snort's output feeds an automated reasoning chain directly. False positives do not simply consume analyst attention. They burn agent compute cycles, fill investigation queues, and can in misconfigured deployments trigger automated containment actions. The accuracy requirements for the sensor layer go up.
SnortML's probabilistic output helps here in a concrete way. Because the classifier returns a float rather than a binary match, the agentic layer can incorporate that probability into its own confidence scoring. An alert combining a classical signature match with a 0.97 SnortML score gets routed very differently from one where only the ML fired at 0.61. The richer output gives downstream reasoning more to work with and makes threshold-based escalation logic more nuanced.
The diagram below shows how the multi-agent SOC architecture coordinates across specialized functions. Each agent handles one layer of the investigation: triage, enrichment, deep correlation, contextual history. Note the decision points at severity assessment and response: both are explicitly branching structures rather than linear pipelines, which is what allows proportionate human involvement based on risk level rather than treating every alert identically.
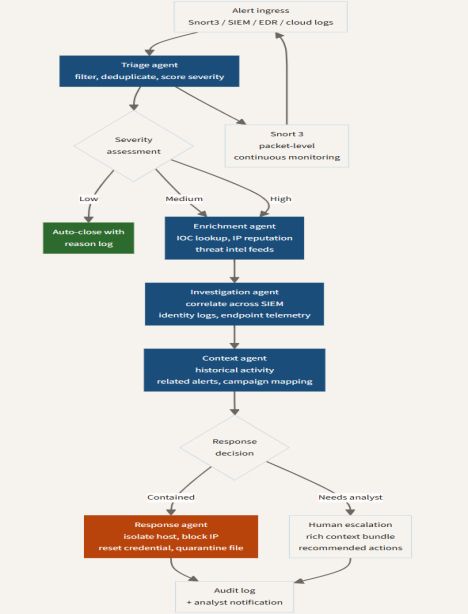
Part 4: A proposed integration architecture
For anyone running an actual Snort 3 deployment, the practical question is how to connect these layers. The architecture below is a concrete proposal, not a vendor product pitch. Every component in it exists today. The question is how to compose them.
The capture tier handles wire-level packet acquisition through the DAQ layer, feeding Snort's analyzer threads through AFPacket RSS queues or DPDK depending on throughput requirements. The detection tier runs the MPSE Hyperscan rule engine and the SnortML LSTM classifier in parallel, both feeding into a unified event stream over a telemetry bus. That stream carries JSON-formatted alert data, ML probability scores, and flow metadata. The schema matters here because whatever agentic framework sits above it needs to parse and reason over that data: inconsistencies in how fields are named or what values are present for different alert types create integration friction that compounds at scale.
The agentic reasoning tier receives that event stream and dispatches to specialized agents along functional lines. A triage agent handles deduplication, filtering, and initial severity scoring. Enrichment agents pull IOC data, IP reputation, and threat intelligence. An investigation agent correlates across SIEM data, identity provider logs, and endpoint telemetry. A context agent maps the current activity against historical patterns, prior alerts from the same source, and known campaign signatures.
The diagram below shows the full integration from capture tier through agentic reasoning to the feedback loop. The most important structural feature is the path running back from the response tier to both the ML model and the rule engine. That feedback connection is what most current deployments are missing.
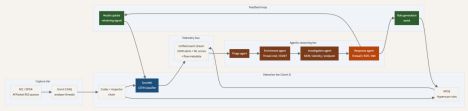
The feedback loop problem
Most current deployments cut off at the detection-to-agentic handoff. Agents receive Snort output, investigate, and act on it. Nothing flows back to improve what Snort detects. Every confirmed attack investigation an agent completes contains information that the ML training pipeline could use: a payload that scored below threshold but turned out to be real, a variant that no signature covered, a novel obfuscation pattern that the classifier learned to score low. That data, labeled and structured, is training signal that currently gets discarded.
The technical path to capturing it is not complicated. HTTP parameter data from confirmed incidents already exists in the alert telemetry. Extract it, run it through a human validation step, and feed it into a periodic retraining job. Cisco's LSP delivery mechanism can push updated models through the same channel as rule updates. The organizational process around this is harder than the technical side, specifically the human validation step. An adversary who can manipulate what the investigation agent confirms, through crafted activity patterns that look like successful attacks to automated analysis, could in theory introduce poisoned training samples into the pipeline over time. That threat model needs anomaly detection running on the retraining input, not just on live traffic.
OPEN RESEARCH PROBLEM: FEEDBACK SECURITY
Automated model update pipelines that ingest data from production traffic face a class of adversarial attack that is distinct from the evasion problem. An attacker who can cause false confirms through coordinated activity that fools the investigation agent can introduce corrupted training samples without touching the inference path directly. The retraining pipeline needs its own anomaly detection layer. Singh et al. (arXiv 2512.23809) address the distributed version of this problem in federated IDS environments using SHAP-weighted Byzantine detection, the most technically complete published treatment to date. In centralized architectures, this remains largely unaddressed.
Part 5: Current gaps and what still needs to be built
What follows is a practical accounting of what does not work yet, and why the gaps matter for people deploying these systems now.
SnortML coverage is HTTP-only, for now
Current SnortML models detect exploits in HTTP URI query strings and POST bodies. That covers a large slice of web application attack surface, but DNS tunneling, TLS-layer attacks, protocol-level injection in non-HTTP services, SMB exploitation, and anything else outside the HTTP parameter space falls outside its scope entirely. The publish/subscribe architecture is protocol-agnostic: any inspector can publish data that the ML inspector subscribes to. The training data is the constraint. Labeled corpora for less-studied protocols are much harder to assemble than HTTP datasets, where years of security research have produced substantial public collections. Until those corpora exist, SnortML's ML coverage stays HTTP-bounded.
Agentic coordination protocols are still maturing
Multi-agent security platforms today run on proprietary orchestration layers. IBM's ATOM, SentinelOne's Purple AI, and Torq's multi-agent system each have internal agent coordination built to their own specifications, with no interoperability between them. The Model Context Protocol and Agent-to-Agent Protocol are emerging as potential standards, but neither has reached the adoption level where you can reasonably assume they will be supported by a given vendor platform. For Snort-centric deployments, this means the event schema Snort produces needs to be explicitly mapped to each agent framework's expected input format, and that mapping work needs to be repeated for each integration. Schema stability on the Snort side and broader MCP adoption on the agent side would both reduce this burden considerably.
Explainability in ML alerts is underdeveloped
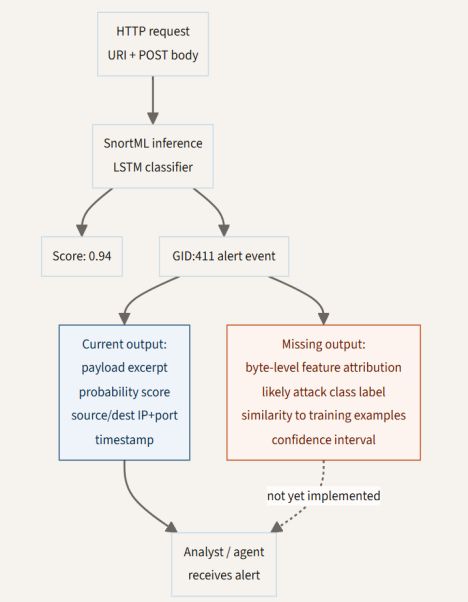
When SnortML fires and an investigation agent escalates the finding to a human analyst for final approval, that analyst has a reasonable question: which part of the payload triggered this? Not the whole URI, but specifically which bytes drove the score above threshold. Was it the presence of a single-quote character? A particular sequence that resembles a UNION SELECT pattern? Current SnortML alert output provides the probability score and the triggering payload content. It provides nothing about the attribution of that score to specific input regions.
Gradient-based attribution methods, specifically Integrated Gradients applied to the LSTM's input embedding layer, can produce byte-level importance scores for exactly this kind of sequential model. The technique is well-understood and has been applied to text classification tasks with similar architectures. Implementing it for SnortML would mean adding an attribution computation to the inference path and extending the GID:411 alert format to carry that output. The engineering path is clear. None of it has been built into the current production system.
The diagram below shows the current alert data flow against what is missing. The left path is what analysts and agents receive today. The right path is what would be available if attribution output were implemented. Both paths originate from the same inference pass, so the gap is not architectural. It is a matter of what gets surfaced from an inference run that already has the information needed to compute it.
Model robustness under adversarial input is untested in public
SQL injection detection via neural network is a supervised learning problem. The model was trained on a corpus of known attack patterns and learns a decision boundary separating them from benign traffic. An adversary aware that SnortML is deployed can, in principle, probe that boundary systematically: try obfuscated variants, character encoding tricks, SQL comment injection, whitespace manipulation, and other evasion techniques to find inputs that preserve exploit functionality while scoring below the detection threshold. This is the standard adversarial ML problem applied to network security. It is not theoretical.
What is missing is any published characterization of where that boundary sits and how stable it is under deliberate attack. SnortML is running in production Cisco Secure Firewall deployments today. The operational security community deserves published adversarial robustness evaluations: what attack classes evade the model, at what rate, under what obfuscation techniques. That work has not appeared publicly. It should.
Part 6: Research directions with genuine novelty
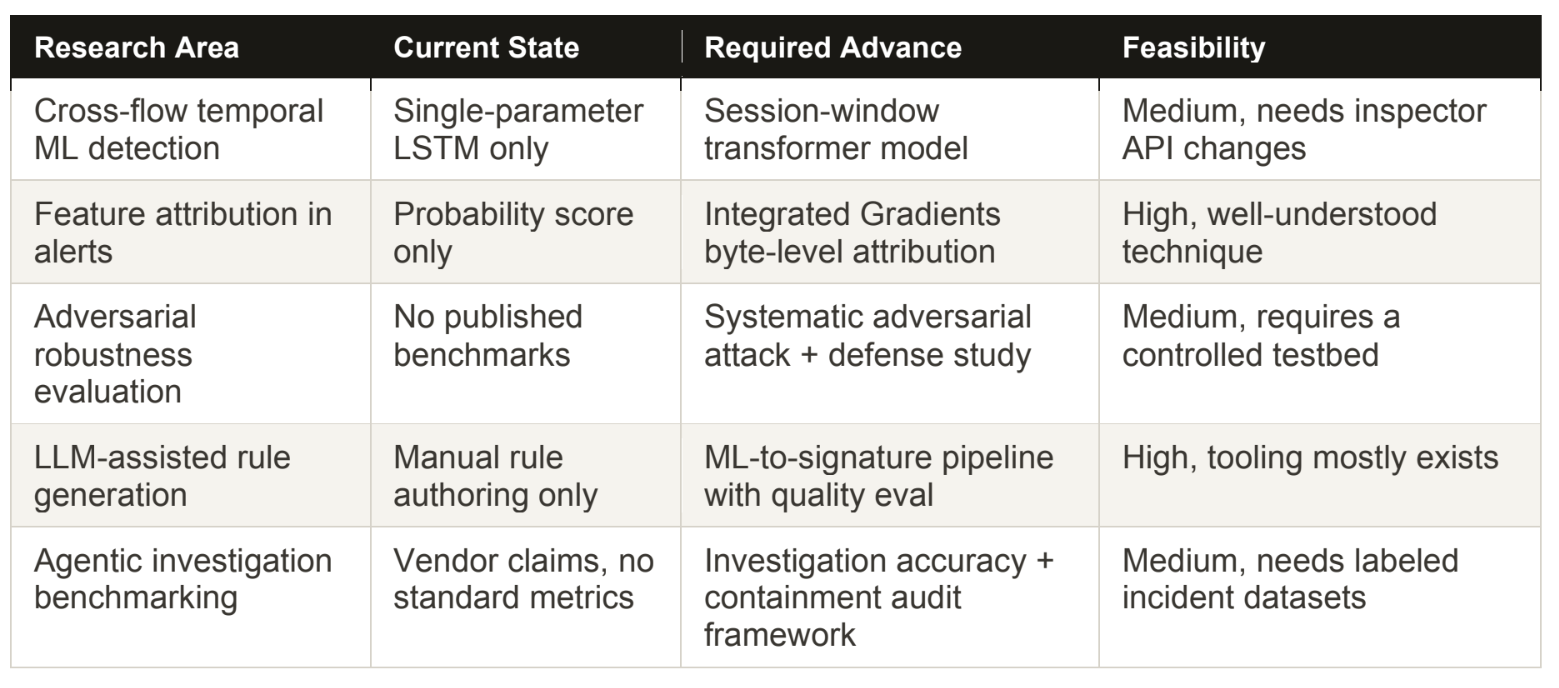
The following five directions do not have clean answers in the current literature. Each one is specific enough to be tractable as a research project and significant enough to matter in deployed systems.
Cross-flow temporal modeling in SnortML
The current LSTM processes a single HTTP parameter sequence. A meaningful architectural extension would operate over a window of requests from the same source IP within a session. Practically, this might mean a fixed window of the last 10 or 20 requests from a given source, or a time-bounded window of 60 to 120 seconds of activity, whichever is shorter. Attackers conducting reconnaissance before exploitation exhibit characteristic temporal patterns: a probe request to test input handling, one or more enumeration requests to identify injectable parameters, and then the exploit tailored to what the probes revealed. A single-parameter classifier is structurally blind to this pattern regardless of how good the per-request scoring is.
A transformer-based model operating over such a session window would be a meaningful step forward in detection capability. The engineering challenge is real: Snort's current data delivery model passes individual parameter values to the ML inspector. Building a session-level feature vector requires changes to how the inspector buffers and accumulates input across multiple requests, which touches inspector lifecycle management and memory handling. The research question is whether the detection improvement justifies that architectural complexity.
LLM-assisted Snort rule generation from SnortML detections
When SnortML fires on a confirmed true positive, the triggering HTTP parameter contains syntactic patterns that an experienced rule writer would immediately reach for when drafting a signature. An LLM with access to that payload, familiarity with Snort rule syntax, and a few examples of well-crafted existing rules can attempt to draft a candidate signature covering the same case. The resulting signature, once validated, puts explicit classical coverage in place for that attack pattern so that future instances trigger even without ML inference.
This creates a genuinely useful loop: ML detection handles novel cases that no signature covers, and confirmed detections feed a pipeline that hardens classical coverage. The research question is concrete and measurable: how do LLM-generated Snort rules compare to manually authored ones in terms of false positive rate, generalization across payload variants, and processing overhead? That comparison has a publishable answer and practical consequences for how detection rule pipelines get staffed and automated.
Agentic investigation quality metrics
The security industry is deploying agentic SOC platforms with real authority over containment decisions, and almost no formal benchmarking exists for how well those agents actually investigate. The vendor-provided metrics focus on volume reduction: number of alerts triaged per hour, time from alert to close, analyst hours saved. None of that tells you whether the agent is making good decisions.
A more useful benchmarking framework would measure investigation accuracy directly: the rate at which automated containment actions were triggered by confirmed false positives, the rate at which genuinely malicious activity was classified as low-severity and auto-closed, the fraction of escalations where the context bundle assembled by the agent led to the correct analyst decision within a defined time window. Building that framework requires labeled datasets of real incident investigations with known ground truth, which is a data collection problem as much as a metrics design problem. The work is needed and largely absent from the current literature.
Part 7: Practical deployment guidance
For teams deploying Snort 3 today and working out how SnortML and agentic tooling fit into their stack, a few operational lessons are worth learning up front.
Start with SnortML on a monitoring tap, not inline
SnortML's HTTP parameter classifier has a false positive rate that, while low, is not zero. Running it inline with block-on-detection before you understand how it behaves against your specific traffic profile is a straightforward way to cause production outages. Legitimate applications that use parameterized queries with unusual encoding, REST APIs that pass data structures in query strings, or frameworks with non-standard escaping behaviors can all produce inputs that score above the default threshold without being malicious.
The right initial deployment is passive. Capture SnortML alerts as events, measure the false positive rate against your known-good application traffic over at least two weeks covering normal business cycles, and build a baseline understanding of how the model behaves on your specific protocols and application patterns before enabling blocking. In Cisco FMC, set the GID:411 rule to alert-only during this evaluation period. Once you have that baseline, threshold tuning and selective inline deployment make sense.
Treat the ML score as one input among several
If you are building agentic investigation logic above Snort, do not wire routing decisions that treat a SnortML score above 0.9 as equivalent to a confirmed classical signature match. The two detection mechanisms have structurally different error profiles. Classical signatures produce very low false positive rates on patterns they cover and miss variants. SnortML provides better coverage of variants and novel patterns but carries a non-zero false positive rate on legitimate traffic that resembles attack syntax at the byte level. URL-encoded special characters in database queries and some REST API authentication schemes can score in the moderate range.
The right architecture uses ML score as one factor in a composite confidence calculation, not as a standalone trigger. An alert where both a classical signature and SnortML fired at 0.95 should route differently from one where only ML fired at 0.72. Combine the signals. Do not substitute one for the other, and do not let the ML score single-handedly drive automated blocking decisions without corroborating evidence.
Keep humans in the response loop for containment actions
Agentic systems with authority to block IPs, isolate hosts, or reset credentials introduce a risk that is easy to underestimate: an attacker who understands your automated response logic can weaponize it. Crafting traffic that appears to originate from a legitimate critical infrastructure address and triggers your automated block threshold turns your own response system into a targeted denial-of-service capability. This is not theoretical; it is a documented attacker technique against organizations with aggressive automated response.
The operational posture that works is asymmetric: automate investigation heavily and automate response conservatively. Let agents handle the triage, enrichment, correlation, and context assembly that burns analyst hours and does not require high-stakes judgment calls. Reserve final containment decisions for a human who has reviewed the context the agent assembled. Automation reduces the time cost of that review to seconds rather than hours; the human judgment step is what adds the adversarial resilience.
Conclusion
The shift from signature-only detection to hybrid ML-signature coverage, and from human paced investigation to agentic reasoning pipelines, is not happening as a single transition. It is moving in stages, with each stage dependent on the reliability and output quality of the one below it. SnortML represents a mature first stage: a production-deployed ML component that addresses a specific, well-defined problem without touching the performance or operational reliability properties that Snort deployments have always depended on.
The agentic layer above it is less mature, but the operational pressure driving its adoption is not going away. Alert volume continues growing, analyst capacity is not keeping pace, and novel attack techniques appear faster than manual rule development cycles can track. Commercial platforms that work well enough for production deployment have emerged in the past eighteen months. The integration between packet-level ML detection and agentic investigation is where most organizations currently find themselves: aware that both layers exist, still working out how to connect them reliably.
The feedback loop, where confirmed incidents flow back to improve both ML models and rule coverage, supervised by humans but executed automatically, is the harder long-term problem and the most valuable one to solve. A detection system that gets measurably better at catching what attackers actually do today, rather than cataloguing what they did a year ago, changes the economics of offense and defense in a meaningful way. Singh et al.'s ZTA-FL work on Byzantine-resilient federated learning for distributed IDS environments points toward what that loop needs to be resilient against once it is running at scale: not just evasion of the detector, but active manipulation of the improvement mechanism itself.
Snort 3 with SnortML has the right foundation. The engineering work remaining is not about the sensor's detection capability. It is about the plumbing that connects what the sensor observes to the reasoning systems that can act on it intelligently, and the feedback path that turns those actions into a system that improves over time.
REFERENCES
[1] Stultz, B. (2024, March 15). Talos launching new machine learning-based exploit detection engine. Snort Blog. blog.snort.org
[2] Cisco. (2024). Detecting Zero-days with SnortML. White Paper. cisco.com
[3] Cisco Secure Firewall. (2024). SnortML: Machine Learning-based Exploit Detection. secure.cisco.com
[4] Snort 3 Rule Writing Guide. (2024). SnortML documentation. docs.snort.org
[5] snort3/libml. (2024). LibML: TensorFlow + XNNPACK inference library. GitHub.
[6] IBM Newsroom. (2025, April 28). IBM delivers autonomous security operations with cutting-edge agentic AI. newsroom.ibm.com
[7] Trend Micro. (2025, August 15). Trend Micro launches Agentic SIEM. trendmicro.com
[8] Omdia. (2025). The agentic SOC: SecOps evolution into agentic platforms. omdia.tech.informa.com
[9] Multiple authors. (2025, November). AI-Augmented SOC: A Survey of LLMs and Agents for Security Automation. MDPI Systems, 5(4), 95.
[10] Multiple authors. (2026, January). A Survey of Agentic AI and Cybersecurity: Challenges, Opportunities and Use-case Prototypes. arXiv:2601.05293.
[11] Napatech. (2024). 4x Suricata Performance Increase for Napatech SmartNICs. napatech.com
[12] Cisco Talos Blog. (2025, September). SnortML: Cisco's ML-Based Detection Engine Gets Powerful Upgrade. blogs.cisco.com
[13] Singh, S. K., et al. (2025). Zero-Trust Agentic Federated Learning for Secure IIoT Defense Systems. arXiv:2512.23809.