
In April, we shared how Stack Overflow is approaching the future of AI/ML and our products. But you might not realize that we’ve already used AI/ML to build or improve Stack Overflow’s products and features.
Every day Stack Overflow helps all types of developers learn new skills by answering their questions or helping them discover new solutions and approaches. We also know that learning is hard. Oftentimes, users don’t know what questions to ask - they don’t know what they don’t know. That’s why earlier this year, we were excited to announce more ways to learn and grow your skills with our online course recommendations. This new native advertising product recommended online courses that were selected based on the content a user viewed or is currently viewing and provided them with a structured learning path that was relevant to what they wanted to learn.
The following post dives deep into how we designed and built the recommendation system and how it has laid the foundation for other AI/ML initiatives at Stack Overflow.
The idea
Recommending external content is nothing new to Stack Overflow. As part of our current Ads business, we offer a content/question-matching product called Direct-to-Developer. What was new about our online course recommendation system is that while developing it, we were simultaneously launching a new, modern data platform for Stack Overflow. This gave us fresh infrastructure, unrestricted tech stack options, and the opportunity to use state-of-the-art machine learning techniques.
Building upon a clean slate allowed us to hyper-focus on making the learning process easier and more efficient by bringing relevant and trusted courses to developers and technologists. We also wanted to run highly configurable experiments throughout the pilot—bonus points if we could reuse components for other initiatives.
This lead us to build a cloud-first content-based recommendation system that recommends content that is similar to the posts you have or currently are interacting with. This system would need to account for three types of recommendations; post-to-content, user-to-content, and a fallback of the most popular. Each addressed a specific use case to ensure a relevant course could always be served while respecting user preferences.
Our approach
Post-to-content
At the core of a content-based recommendation system is how similarity is defined. At Stack Overflow, we have a lot of text and the catalog of courses to recommend also includes text. So we needed a way to measure the similarity between two pieces of text; a Stack Overflow post and an online course. If you are familiar with NLP (natural language processing), you know there are dozens of ways to approach this problem. Recently, there has been one approach that does extremely well: semantic similarity using embeddings from a pre-trained transformer model.
In our approach, we used a pre-trained BERT model from the `SentenceTransformers` library to generate an embedding for all 23 million Stack Overflow questions and a separate embedding for every course in the catalog. These embeddings allowed us to calculate cosine distance to determine how similar two pieces of text are. We only had a couple thousand courses, so we were able to load all the course embeddings into a nearest-neighbor model and perform a brute-force search to match courses to all questions. The output of this model is our post-to-content recommendation.
In our prototyping phase, this approach performed extremely well! Not only was it able to find the most relevant courses, but by using the BERT model it already had foundational knowledge like “Node is related to JavaScript” and “Swift is related to Apple”. It allowed for offline evaluation and helped us identify which popular technologies on Stack Overflow were missing from the course catalog.
User-to-content
Our post-to-content recommendations ensured that every Stack Overflow question had a list of relevant courses for an ad to be served. This provides an alternative just-in-time learning opportunity for all visitors. But for the users that opted-in to targeted ads, we wanted to provide a personalized recommendation that leveraged our first-party data.
To make a recommendation to a user we needed a way to represent the sum of the content that they have viewed. To do this we took all the posts they viewed within a certain lookback window and averaged them into one embedding. For example, if a user viewed ten posts, we took those ten post embeddings described above and averaged them element-wise into one embedding. This is commonly referred to as mean pooling. With this one embedding, we can use the same nearest-neighbor model and perform find the most similar course to what the user viewed to produce a user-to-content recommendation.
This approach also performed extremely well when we evaluated our own interactions with questions. Yes, Stack Overflow employees also use Stack Overflow! This personalized recommendation consistently outperformed post-to-content in clickthrough rate once we launched.
Top content
The last type of recommendation was to randomly select from a list of top courses, mostly JavaScript or Python, and was used purely as a fallback scenario. Either if there was no recommendation available or if something upstream failed. Regardless top was only served a fraction of the time as priority was set to serve user-to-content and then post-to-content.
How we built it
With any project, especially a machine learning one, the hardest part is often moving it into production. Throw in simultaneously building a brand-new cloud data platform and a non-existent machine learning platform, we had our work cut out for us. Early on we decided not to rebuild the wheel and to empower “full-stack data science” work. This allowed our data scientist (myself) to have almost complete ownership of the entire project. This blessing and curse made it clear that leveraging one platform for as much as possible would be wise, and our platform of choice was Azure Databricks. This allowed us to keep all data processing, feature engineering, model versioning, serving, and orchestration all in one place.
Recommender systems are inherently complex because of all the separate components. So we designed our system to be as modular as possible. This allows us to control dependencies and experiment with different model parameters and techniques. The crux of our system is an offline-batch recommender system, meaning all recommendations would be pre-computed offline and stored somewhere ready to be served when needed. While there are many intricacies, think of our system as being broken down into three core components: generating embeddings, making recommendations, and serving recommendations.
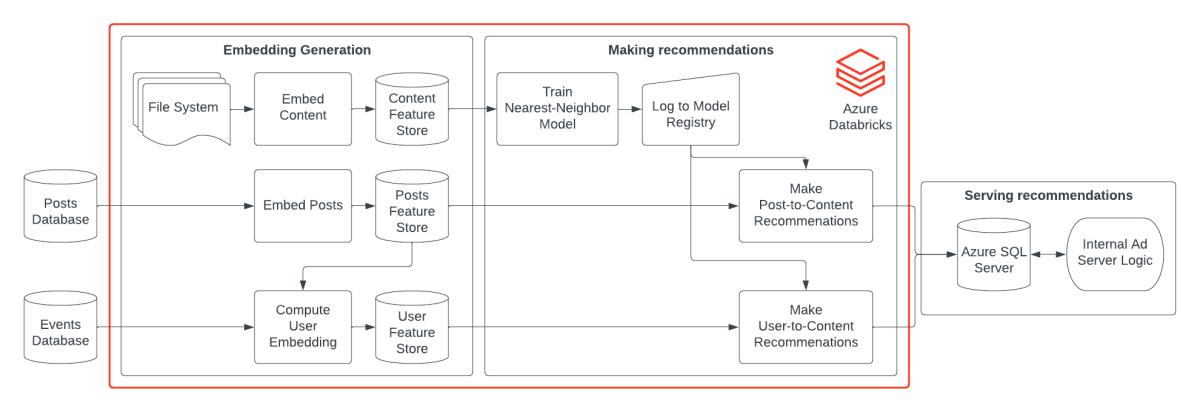
Generating embeddings
As mentioned earlier, the core of a content recommendation system is how similarity is defined. For us, it was computing sentence embeddings and performing a nearest neighbor search. Doing this for 23 million posts and millions of users each run is no small task. Because Databricks is built on PySpark, naturally we leaned heavily into the PySpark ecosystem, which allowed us to rapidly prototype on “small” amounts of data and scale with no code changes.
For the one-time job of generating post embeddings, we wrapped the BERT model in a PySpark Pandas UDF that ran on a GPU cluster. Then on a regular cadence, we computed new and edited question embeddings. Each time the post text, embedding, and other meta-data were written to a feature store. This was the same approach we took to generate the course embeddings.
The user embeddings had to be refreshed each time we wanted to make new recommendations to account for the most recent user activity. We set a minimum number of questions a user had to view within the lookup window, if they met the threshold, then they were eligible for a recommendation to be made. For eligible users, we pulled the post embeddings from the post feature store table, pooled them, and wrote them to a separate user feature store table. For pooling, we also leveraged a Pandas UDF as there were other pooling methods we wanted to try, like linear or exponential weighting.
Making recommendations
With only a couple thousand courses, we loaded all the embeddings into a modified nearest neighbor model, which allowed us to log it directly to the MLflow Model Registry and track lineage to the content feature store. We only had to retrain this model if we added or removed courses to the catalog. Logging the model to the registry also meant there was a clear path to going real-time if we so chose, as we could deploy the model as a serverless API.
Whenever making the recommendations, the logged model was then pulled from the registry and predictions were made directly on a Spark DataFrame. The data was then written to an intermediary Delta table.
For those familiar with recommender systems, you may notice that this is a retrieval-only system, and you are correct. The initial release of the system did not include a ranker model as we needed to collect labels to train a model to re-rank results based on predicted clickthrough rate or other business-driven metrics, not just similarity.
Serving recommendations
Once all recommendations were computed and a series of quality checks were passed, the final results were then written to an Azure SQL Server database. This database served as a low enough latency database for our internal ad-serving platform to select from when it needs to serve a course recommendation.
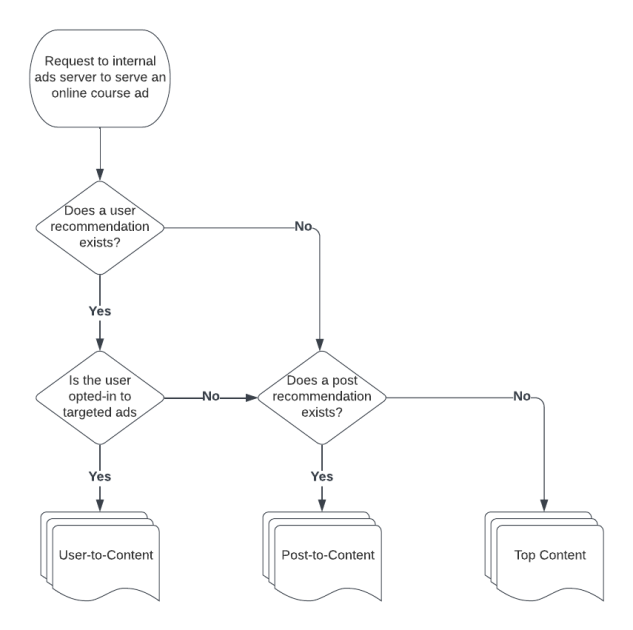
Once our internal ad server was told to serve an online course ad, it first looked to see if the user was opted-in to targeted ads. If so, it would then check to see if a user-to-content recommendation was available. If not, it would use post-to-content, and if there was a failure or the ad was being served on a non-question page, then a top content recommendation was served. This logic can be seen in the below flowchart.
Deployment and experiment
Each of the above three core components had various parameters that could be changed and configured. Each potentially affecting the final recommendation and the execution time significantly. What embedding model, lookback window, or pooling method was used? What cluster configuration, execution schedule, and batch size were used? To address this, we used Databricks’ CI/CD tool dbx to parametrize the workflows and configurations, then had GitHub actions execute the builds. This allowed us to easily move from our development workspace to our production workspace and version changes, while always knowing how a recommendation was computed.
Looking forward
We achieved a lot during the course (no pun intended) of building our online course recommendation system. We went from having no data platform to having a feature-reach machine learning platform that has been handling millions of recommendations every week. It was a learning experience for everyone involved but, most of all, an exciting milestone for Stack Overflow’s AI/ML initiatives. We have already re-purposed some of the work to improve our Related Questions section, which saw a 155% increase in the clickthrough rate (look for a future blog post on this). We have a lot of other ideas and experiments we’re working on for other applications of AI/ML to improve our platforms.