What is RAG?
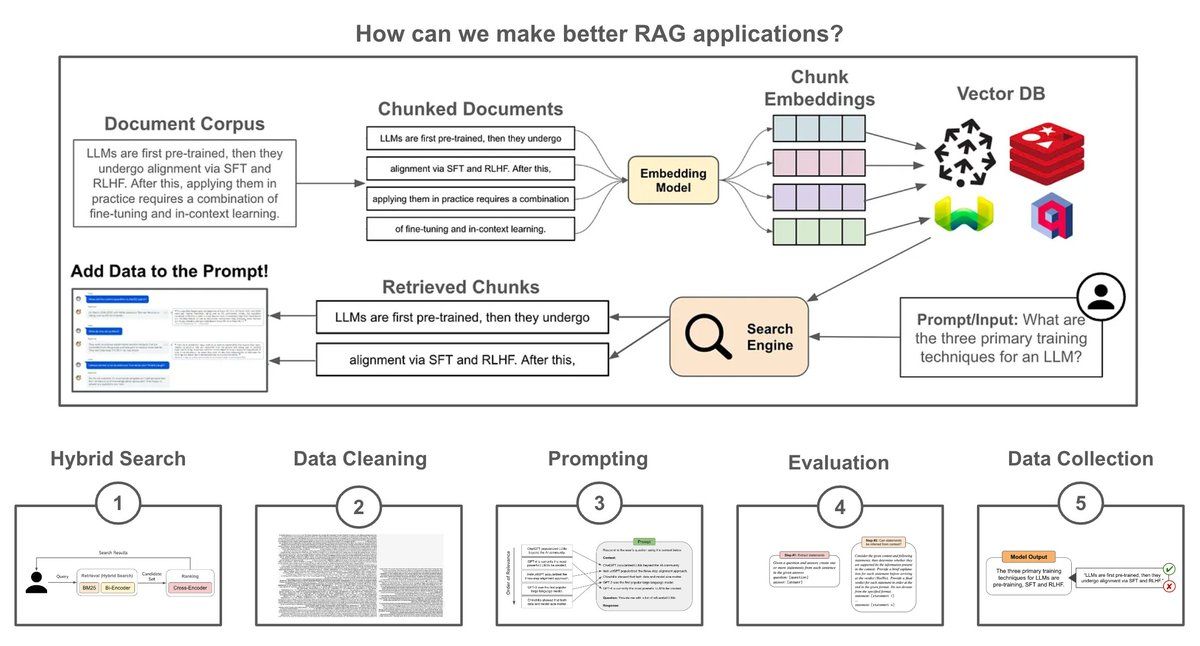
At the highest level, RAG is a combination of a pretrained LLM with an external (searchable) knowledge base. At inference time, we can search for relevant textual context within this knowledge base and add it to the LLM’s prompt. Then, the LLM can use its in context learning abilities to leverage this added context and produce a more factual/grounded output.
Simple implementation: We can create a minimal RAG pipeline using a pretrained embedding model and LLM by:
1. Separating the knowledge base into fixed-size chunks.
2. Vectorizing each chunk with an embedding model.
3. Vectorizing the input/query at inference time and using vector search to find relevant chunks.
4. Adding relevant chunks into the LLM’s prompt.
This simple approach works, but building a high-performing RAG application requires much more. Here are five avenues we can follow to refine our RAG pipeline.
(1) Hybrid search: At the end of the day, the retrieval component of RAG is just a search engine. So, we can drastically improve retrieval by using ideas from search. For example, we can perform both lexical and vector retrieval (i.e., hybrid retrieval), as well as re-ranking via a cross-encoder to retrieve the most relevant data.
(2) Cleaning the data: The data used for RAG may come from several sources with different formats (e.g., pdf, markdown and more), which could lead to artifacts (e.g., logos, icons, special symbols, and code blocks) that could confuse the LLM. We can solve this by creating a data preprocessing or cleaning pipeline (either manually or by using LLM-as-a-judge) that properly standardizes, filters, and extracts data for RAG.
(3) Prompt engineering: Successfully applying RAG is not just a matter of retrieving the correct context—prompt engineering plays a massive role. Once we have the relevant data, we must craft a prompt that i) includes this context and ii) formats it in a way that elicits a grounded output from the LLM. First, we need an LLM with a sufficiently large context window. Then, we can adopt strategies like diversity and lost-in-the-middle selection to ensure the context is properly incorporated into the prompt.
(4) Evaluation: We must also implement repeatable and accurate evaluation pipelines for RAG that capture the performance of the whole system, as well as its individual components. We can evaluate the retrieval pipeline using typical search metrics (DCG and nDCG), while the generation component of RAG can be evaluated with an LLM-as-a-judge approach. To evaluate the full RAG pipeline, we can also leverage systems like RAGAS.
(5) Data collection: As soon as we deploy our RAG application, we should begin collecting data that can be used to improve the application. For example, we can finetune retrieval models over pairs of input queries with relevant textual chunks, finetune the LLM over high-quality outputs, or even run AB tests to quantitatively measure if changes to our RAG pipeline benefit performance.
What’s next? Beyond the ideas explored above, there are a variety of avenues that exist for improving RAG. Once we have implemented a robust evaluation suite, we can test a variety of improvements using both offline metrics and online AB tests. Our approach to RAG should mature (and improve!) over time as we test new ideas.