Recently, AI expert Cameron Wolfe broke down the decoder-only transformer architecture and explained its importance for AI researchers. In this piece, he explains some recent changes that have made this architecture more effective.
Although the decoder-only transformer is used almost universally by all large language models (LLMs), several recent changes have been made to improve this architecture’s effectiveness.
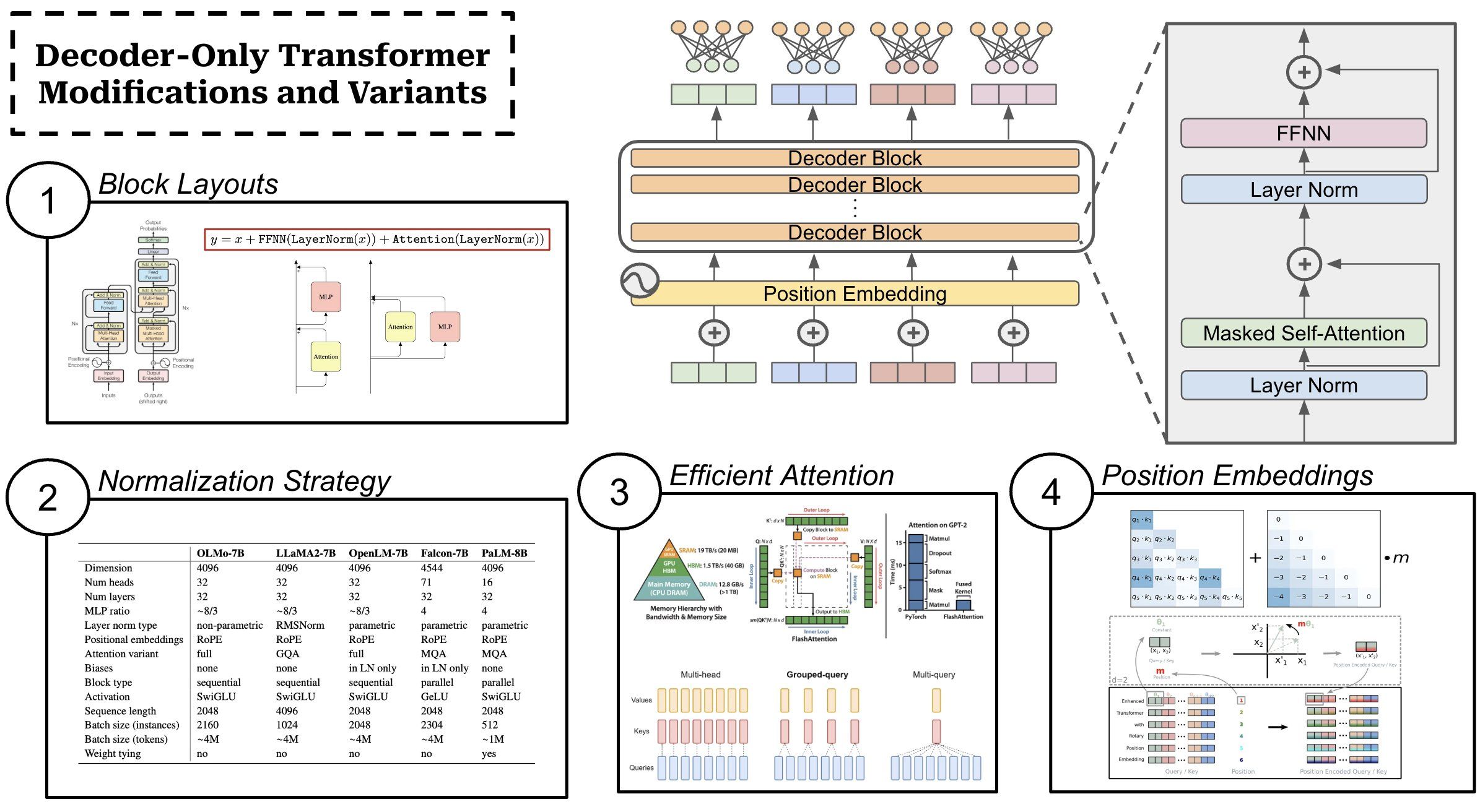
(1) Transformer block layouts. The standard layout of a transformer block is: masked self-attention → layer normalization → feed-forward transformation → layer normalization. We add residual connections around each of these sub-layers. However, the order of normalization operations changes depending upon the implementation; e.g., normalization is sometimes placed before/after each sub-layer, and some architectures—such as Gemma—perform normalization at both locations.
“We normalize both input and output of each transformer sub-layer, a deviation from the standard practice of solely normalizing one or the other.” —from Gemma technical report
Models like Falcon and PaLM have also explored “parallel” block structures that pass input through the attention and feed-forward layers in parallel (instead of in sequence). Such an approach lessens the communication costs of distributed training, and is found by both models to yield no noticeable degradation in performance.
(2) Normalization strategy. While most models use layer normalization, Root Mean Square Layer Normalization (RMSNorm for short!) is a popular alternative. RMSNorm—used by LLaMA and LLaMA-2—is a simplified version of layer normalization that maintains the performance of layer normalization, while improving training stability/generalization and being 10-50% more efficient. Going further, MPT models adopted a low precision variant of layer normalization to improve hardware utilization during training.
(3) Efficient Self-Attention. Although self-attention is the foundation of the transformer architecture, this operation is somewhat inefficient—it is an O(N^2) operation! Many efficient attention variants have been proposed to solve this issue, but very few of them realize any wall-clock speedups in practice. Efficient attention variants used by current LLMs include:
- FlashAttention: reformulates self-attention (drop-in replacement) in an IO-aware manner to improve training speed and enable longer context lengths.
- Multi-Query Attention: shares key and value projections between all heads of the self-attention layer to improve inference speed.
- Grouped-Query Attention: an extension to multi-query attention that separates key/query projections into groups that share the same projection (instead of having all of them share the same projection) to avoid performance deterioration.
FlashAttention has also been further developed by the recent proposal of FlashAttention-2 and FlashDecoding (i.e., extends flash attention to speed up both training and inference).
(4) Better position embeddings. The vanilla transformer architecture uses additive, absolute position embeddings, which have problems with extrapolating to sequence lengths longer than those seen during training. For this reason, a variety of alternative position encoding schemes were proposed, including relative position embeddings that only consider the distance between tokens rather than their absolute position. Currently, the two most popular strategies for injecting position information into the transformer architecture are:
- Rotary Positional Embeddings (RoPE): a hybrid of absolute and relative positional embeddings that incorporate position into self-attention by encoding absolute position with a rotation matrix and adding relative position information directly into the self-attention operation.
- Attention with Linear Biases (ALiBi): incorporates position information directly into self-attention at each layer of the transformer by adding a static, non-learned bias to the attention matrix instead of using position embeddings.