
I don’t know if you’ve noticed this, but people on Stack Overflow have some pretty strong opinions. When you answer a question, you’re bound to get a few clarifications, corrections, and disagreements. And when you recommend the best API or library to get a job done, then you’re sure to get a wealth of comments about everyone’s experience with those APIs.
Now Stack Overflow was not designed or intended to determine whether any technology is particularly “good” or “bad.” But if you could collect and analyze the opinions posted within the comments and questions, you could start to get a bead on the aggregate sentiment, sort of a Yelp for technology.
In fact, that’s just what Gias Uddin, now a Senior Data Scientist at the Bank of Canada, looked at for his PhD thesis at McGill University. Along with his PhD supervisor, Foutse Khomh, Associate Professor at Polytechnique Montréal, determined a method to mine opinions on APIs and libraries from questions and comments posted on Stack Overflow.
“Our realization was that we have a documentation issue,” says Khomh. “Documentation about software libraries and APIs (Application Programming Interfaces) doesn't support developers efficiently in learning how to use APIs.” To supplement the official documentation the tech community has produced its own documentation through forums where they weigh in on their favorite technologies. “There are all these very rich crowd sources of information available out there about APIs, with people exchanging tips, tricks, experiences and so on. This information can complement the official documentation resources by being more task-based, up to date, and peer-reviewed by the developers who actually used those APIs. That's how we started diving into extracting the essence of rich information from a Q&A platform like Stack Overflow.”
But in order to determine what opinions developers held on any given API, they had three problems to solve:
- Determine the sentiment of a piece of text.
- Locate the names of APIs and libraries.
- Connect the sentiment to the API names.
Tell us how you feel, Stack Overflow
Previous research determined that developers on Stack Overflow generally expressed emotions towards the technology, not towards the other developers in a given thread. So to determine what emotions were being expressed about a given technology, they used a natural language processing technique called sentiment analysis. This looks at various keywords—”good” or “bad”—and determines whether those keywords indicate that the statement is overall positive or negative. Uddin and Khomh have another paper in the works exploring the various existing sentiment analysis tools.
Sentiment analysis is itself a whole line of research, and the problem becomes more complicated when you try to determine if the context around a word affects the comment’s sentiment. Take the word “like.” “I like this”, “This is like the last time I tried it”, and “I’d like a better way to do this” all use the word to express different sentiments. In fact, the second one can’t be determined without knowing about the previous time they tried this.
Their work was further complicated by the domain-specific words used on Stack Overflow to describe technical topics. “Say someone is saying, ‘This API is Threadsafe.’" says Uddin. “Now Threadsafe is in this context a positive sentiment, but Threadsafe is not known as a domain neutral sentiment word because our domain doesn't have any idea what Threadsafe is. But if someone is saying “good,” and if “good” and “Threadsafe” are occurring together quite frequently, and then “good” and “Threadsafe” are both classified as adjectives in a natural language scenario, then you know that there could be some correlation between them.”
To prepare, they needed a data set of sentences with known sentiment. They created a benchmark by manually labeling sentences with both a sentiment and the API aspect about which the opinion is provided. For example, if a comment says, “The API is fast,” it will be labeled as positive and about the aspect labeled under “performance.” Eleven people went through 4,522 sentences from 1,338 Stack Overflow questions and comments and labeled their benchmark data set. Now they could begin automated coding.
They began with off-the shelf detection tools, but those didn’t work very well in this context. So they tried their hand at writing their own sentiment detection algorithms using domain sentiment orientation geared towards the words used by developers. By processing known sentiment adjectives and linking them to other sentiment-neutral adjectives on Stack Overflow, they came up with about 800 new words that could indicate positive or negative sentiment within the language used on Stack Overflow.
To spot the technologies being discussed, they developed an algorithm to link technology keywords to the specific API library being discussed. But not every sentiment expressed is about a technology. The final step was linking the emotional content and the API. For this, they developed a heuristic-based technique to link the two based on the contexts in which they are located. With this link established, Uddin notes, “you can see that these are the different reviews people are giving about these different APIs.”
The proof of concept: Opiner
As a proof of their research, Uddin and Khomh put together Opiner, a website that showcases their algorithms on a sample of Stack Overflow data. It uses only those questions tagged with both ‘json’ and ‘java’ as of January 2014. The website, search, and data rendering was coded 95% in Python, with some of the offline tasks performed using Java.
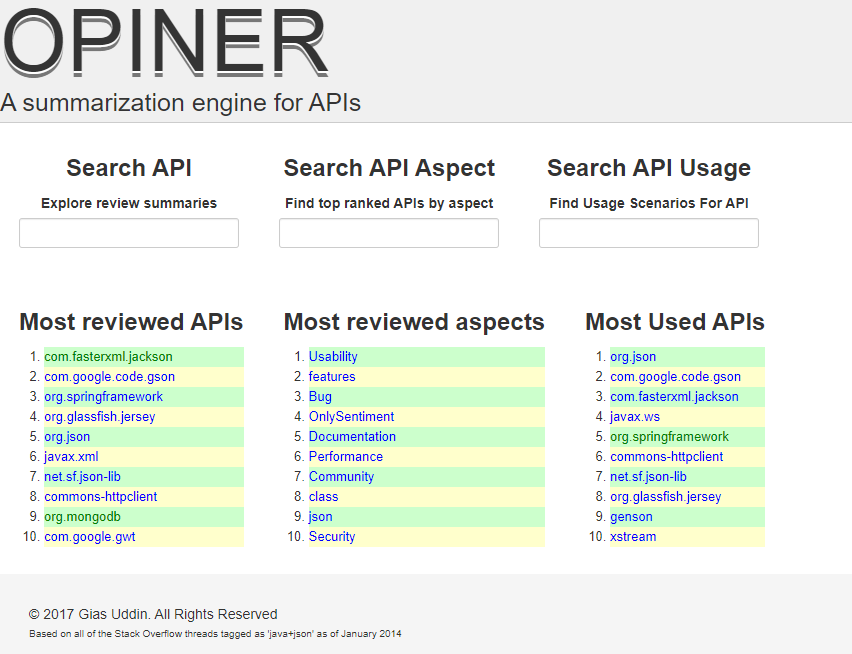
Within this site, they needed some way to efficiently deliver these opinions. “Step number four was understanding that have collected all these different reviews about APIs,” says Uddin. “That is still too many. How can we summarize them?” For each of the APIs in the database, they offer an overview page, where you can dive deeper into all of the comparisons and the aspects indicated.
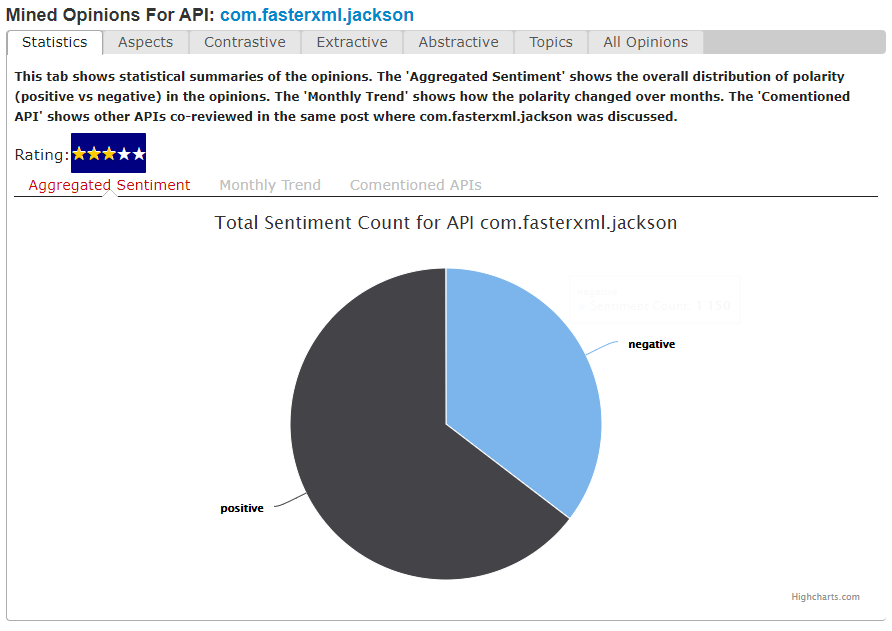
To present more results than just a summary, they added some extra tabs that process the results accordingly and try to make a little more sense of them. Besides the overall aggregation of the overview, they provided three different types of summaries:
- Contrastive - Attempts to match positive and negative comments as to determine which are the more controversial APIs.
- Extractive - Pulls out the most interesting opinions out based on three different algorithms.
- Abstractive - Generalizes summary opinions based on Opinosis, which looks for redundancies in opinions. The Topics tab uses an algorithm called latent Dirichlet allocation (LDA) to find the topic words that are statistically significant to some of the opinions. This tab attempts to understand what the opinions are about by finding their most unique words, then grouping them based on their usage in proximity.
- The Aspects tab attempts to determine which qualities the comments on Stack Overflow are referring to, things like performance, security, and more. “When we did the user study, developers were more interested in aspect-based summarization than all the other summarization we presented ot them,” says Uddin. “Which tells us that just blindly applying summarization techniques from other domains is not useful for the domain of software engineering. Developers further recommended us to combine contrastive summarization with aspect-based summarization; that means given a particular API feature for a given aspect, like performance, how developers are offering differing viewpoints based on their experience.”
In the graph tabs, you can see how sentiment has evolved over time in the Monthly Trend section. Because all of the comments and opinions are linked to a specific posting date, the sentiment they generate is too. “You could see things that used to be popular API, but over time, see people moving slowly toward a new more popular API,” says Khomh.
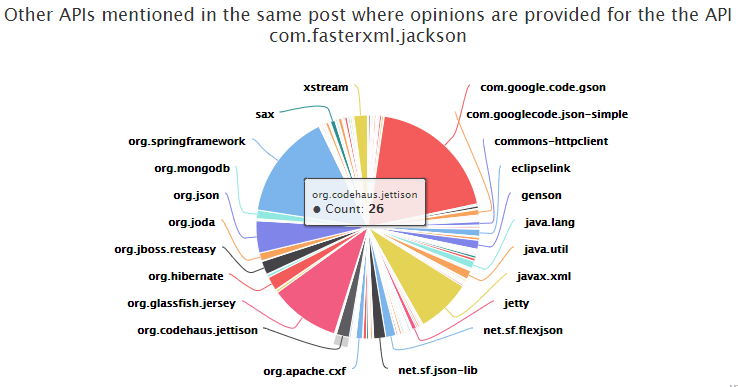
For those more interested in seeing the ecosystem around a particular API, check the Comentioned APIs section. It shows how often a particular API is mentioned with the selected API. While some mentions might be incidental, if an API is mentioned enough, it might be either a strong competitor or something that works well in conjunction.
The research continues
Machine learning and natural language processing are hot topics of research, and Uddin and Khomh will continue to investigate and refine their results. Opiner isn’t meant to be a final database of thought on what APIs are good, but a step towards extracting this information from user-generated commentary not meant to be reviews of the technologies.
“Opiner is fully machine learning,” says Uddin. “It's fully automated, and as you can see if you look at the website, because it's fully automated, you'll see many of them are good, but there is also some error over there because the developed technique was sometimes not able to properly track down opinions, so there is a lot of room for improvement.”
Want to read more? Here's the research behind the site: