
Almost every application not already based in the cloud is migrating there. This cloud migration causes the complexity of architecture to increase—cloud adoption brings with it microservices, load balancers, block stores, serverless functions, etc. These components enable flexibility, scale, and cost savings, but they also make it extremely difficult for one person to retain the state of the overall system in their head. When outages occur and seconds count, time spent trying to remember how and why service A and service Y communicate is time wasted. In this world, reactive monitoring must be expanded to proactive observability.
What is observability?
Observability is the ability to answer any question about a business or application through the collection and analysis of data. Succinctly, it’s an approach to understanding the operation of a system by reviewing output from the system. In the software world, observability generally is framed in the context of the ‘three pillars’ or telemetry data types: metrics, traces, and logs. Combining these three types of data gives you the power to answer questions about your business/application that you may not have known you’d need answers to when you set it up..
You can learn more in my article that explains what observability is in more depth. Long story short, it’s the evolution of monitoring that’s necessary to keep up with modern, complex systems. If you’re an auditory learner, check out this Stack Overflow podcast from Spiros Xanthos, one of the cofounders of the OpenTelemetry project and a leading expert on observability.
Observability platforms enable you to easily figure out what’s happening with every request and to identify the cause of issues fast. Learning the principles of observability and OpenTelemetry will set you apart from the crowd and provide you with a skill set that will be in increasing demand as more companies perform cloud migrations.
What is OpenTelemetry?
From an end-user perspective, “telemetry” can be a scary-sounding word, but in observability, telemetry describes its three primary pillars of data: metrics, traces, and logs. This data from your applications and infrastructure is called ‘telemetry,’ and it’s the foundation of any monitoring or observability system. OpenTelemetry is an industry standard for instrumenting applications to provide this telemetry, collecting it across the infrastructure and emitting it to an observability system.
OpenTelemetry is the second most-active Cloud Native Computing Foundation project only after Kubernetes and is fully open source. The SDK, collectors, exporters, and other components are all public and undergoing a great amount of development to make them easier to deploy and use.
Here’s an overview of the OpenTelemetry architecture:
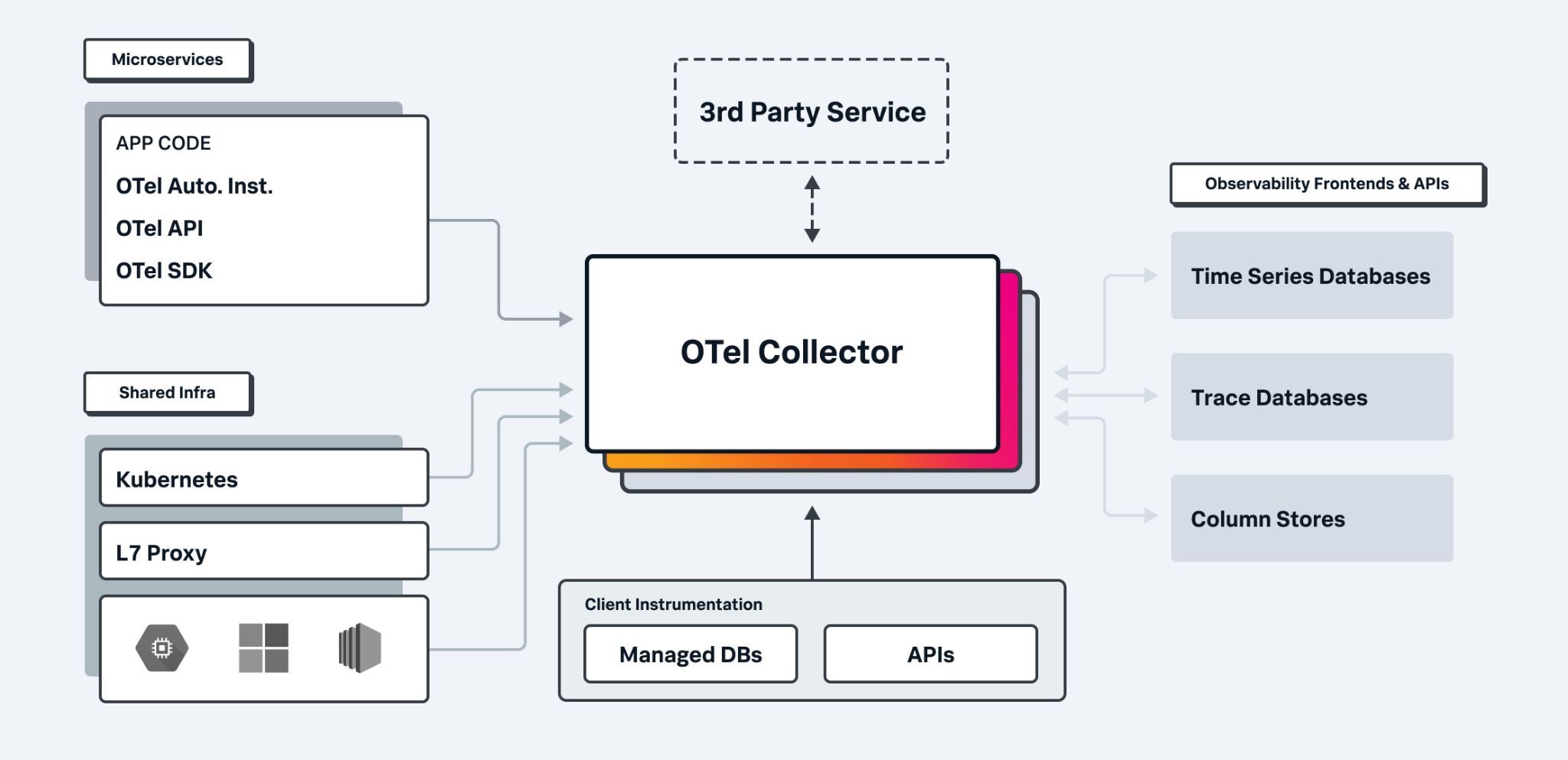
In short, applications use an SDK or Agent to be instrumented to emit relevant metrics, traces, and log data. Infrastructure components also emit metrics. This data flows into a collector that can aggregate or perform other operations on it. Finally, it’s sent to an exporter that can modify the wire protocol or perform processing on the data before it’s sent to an observability system. You can check out more in this document from the OpenTelemetry project.
For many languages, instrumenting applications can be done automatically. To instrument a Java application, all you have to do is drop a JAR into the CLASSPATH and add an argument to the application’s launch command. As long as you have a collector running on the same machine, that’s all there is to it.
What’s in it for me?
You mean besides having easy access to data that explains how your system is functioning? The biggest benefit of using OpenTelemetry for observability is that you only have to do instrumentation and telemetry pipeline work one time, no matter what system you use to analyze the data. You can use a commercial product, open-source, or even roll your own, and you never have to duplicate any of the work you did to instrument your applications.
Many commercial products suggest you use a proprietary agent that claims to make setup easier, but this really is a trap—you’re limited in flexibility to what their agent supports, and if you ever want to change platforms, you have to re-do all the instrumentation work. Why not do this once and retain ownership of your own data?
OpenTelemetry is being adopted rapidly and is a key tool to understand and master as you can read in this article from The New Stack. Becoming an expert now can set you up for success in a few ways:
- If you’re hoping to work in tech, but haven’t decided on your career path, the demand for experts in monitoring and observability will not be decreasing for the foreseeable future. On the contrary, it’s likely to increase as applications become increasingly complicated and require more effort to troubleshoot and operate. Learning OpenTelemetry and observability principles can make you a more compelling candidate if you’re trying to break into the DevOps or SRE world—and this world is lucrative. In the most recent Stack Overflow Developer Survey, SREs in the United States reported a median salary of $150,000 a year.
- If you’re already working in this world, you know that the complexity of your universe continues to increase. Having a handle on it through observability makes you more valuable to your employer and more valuable the next time you change jobs. Being able to demonstrate that you can set up a robust observability pipeline that enables all the benefits I’ve discussed makes you more marketable and lets you play with something that operates in real-time and at a huge scale.
- In either instance, learning OpenTelemetry future-proofs your skill set. The future of monitoring is observability, and the future of observability is OpenTelemetry. Learning it now makes you ahead of the curve and makes sure that you’re learning something that can be used in a myriad of different deployment scenarios and environments.
Leaning into this world can also enhance your network. OpenTelemetry has a robust and active community, with mailing lists, a Slack channel, and of course, GitHub. The project is growing every day and you’ll get exposure to the cutting edge of observability and cloud migration. OpenTelemetry also includes support for a large number of languages (including Erlang/Elixir, Rust, and Go) frameworks (like Spring and Flask,) and libraries such as `net/http` and `gorilla/mux`. You can rely on your OpenTelemetry knowledge to be transferable across languages, frameworks, and libraries.
How do I get started?
As an engineer, the best way to get started with something is to get your hands dirty. As someone who works for a commercial observability vendor, I’d be remiss to not tell you to try a free trial of Splunk Observability Cloud—there’s no credit card required and the integration wizards that walk you through setup actually have you integrate your architecture with OpenTelemetry. Despite the fact that our endpoint is a commercial product, you can reuse the instrumentation work you do setting up our product with basically anything else.
I’d also encourage you to check out the OpenTelemetry project website, and to read some questions tagged observability (or ones tagged OpenTelemetry specifically) here on Stack Overflow (also, ask your own! There’s a lot of rep to be snagged from contributing on this topic). If you’re still confused about the whole observability thing to begin with, I also wrote a Beginner’s Guide to Observability that explains the concepts in more detail.
You can get started instrumenting infrastructure in literally a few minutes, so why not take this time to learn what observability and OpenTelemetry are all about? Your career will thank you.
The Stack Overflow blog is committed to publishing interesting articles by developers, for developers. From time to time that means working with companies that are also clients of Stack Overflow’s through our advertising, talent, or teams business. When we publish work from clients, we’ll identify it as Partner Content with tags and by including this disclaimer at the bottom.