
[Ed. note: While we take some time to rest up over the holidays and prepare for next year, we are re-publishing our top ten posts for the year. Please enjoy our favorite work this year and we’ll see you in 2022.]
Update: I realize we didn't add a lot of context here when telling the story of the engineering decisions we made years ago, and why we're moving away from some of them now. This is an attempt to fix that omission.
Over the past 13 years, we have progressively changed priority as a business. Early on, scaling to millions of users was our main concern. We made some tough calls, and consciously decided to trade off testability for performance. After successfully achieving that scale, much of the context has changed: we have a much faster base framework now, given all the latest improvements in the .NET world, meaning we don't have to focus as much on the raw performance of our application code. Our priorities have since steered towards testability. We got away with "testing in production" for a long time, largely due to our (very active) meta community. But now that we're supporting paying customers, identifying bugs early on reduces the cost of fixing them, and therefore the cost of business. Paying the accumulated tech debt takes time, but it's already helping us get to more reliable and testable code. It's a sign of the company maturing and our engineering division re-assessing its goals and priorities to better suit the business that we're building for.
In software engineering, a number of fairly non-controversial best practices have evolved over the years, which include decoupled modules, cohesive code, and automated testing. These are practices that make for code that’s easy to read and maintain. Many best practices were developed by researchers like David Parnas as far back as the 1970s, people who thought long and hard about what makes maintainable high quality systems.
But in building the codebase for our public Stack Overflow site, we didn’t always follow them.
The Cynefin framework can help put our decision into context. It categorizes decisions into obvious, complicated, complex, and chaotic. From today's perspective, building a Q&A site is a pretty well-defined—obvious—problem and a lot of best practices emerged over the past years. And if you're faced with a well-defined problem, you should probably stick to those best practices.
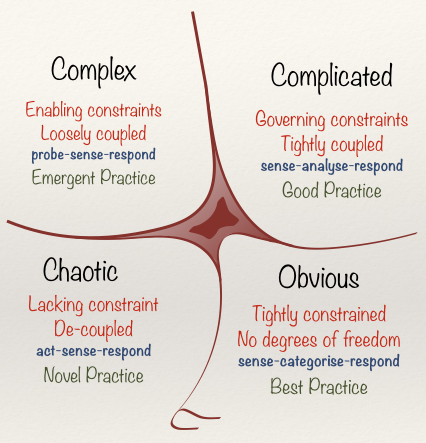
But back in 2008, building a community-driven Q&A site at this scale was far from being obvious. Instead, it fell somewhere in the "complex" quadrant (with some aspects in the "complicated" quadrant, like tackling the scaling issues we had). There were no good answers on how to build this yet, no experts who could show us the way. Only a handful of people out there faced the same issues.
For over a decade, we addressed our scaling issues by prioritizing performance everywhere. As one of our founders, Jeff Atwood, has famously said, “Performance is a feature.” For much of our existence, it has been the most important feature. As a consequence, we glossed over other things like decoupling, high cohesion, and test automation—all things that have become accepted best practices. You can only do so much with the time and resources at hand. If one thing becomes super important, others have to be cut back.
In this article, we walk through the choices we made and the tradeoffs they entailed. Sometimes we opted for speed and sacrificed testing. With more than a decade of history to reflect on, we can examine why best practices aren’t always the best choice for particular projects.
In the beginning...
When Stack Overflow launched in 2009, it ran on a few dedicated servers. Because we went with the reliability of a full Microsoft stack—.NET, C#, and MSSQL—our costs grew with the number of instances. Each server required a new license. Our scaling strategy was to scale up, not scale out. Here’s what our architecture looks like now.
To keep costs down, the site was engineered to run very fast, particularly in accessing the database. So we were very slim then, and we still are—you can run Stack Overflow in a single web server. The first site was a small operation put together by less than half a dozen people. It initially ran on two rented servers in a colocation facility: one for the site and one for the database. That number soon doubled: In early 2009, Atwood hand-built servers (two web, one utility, one database) and shipped them to Corvallis, OR. We rented space in the PEAK datacenter there, which is where we ran Stack Overflow from for a long time.
The initial system design was very slim, and they stayed that way for most of the site’s history. Eventually, maintaining a fast and light site design became a natural obsession for the team.
Safety’s off
If you look at the programming languages that are used today, they fall on a spectrum of high and low-level based on how much that language abstracts the bare metal functionality. On the upper end of high-level languages, you have JavaScript: memory allocation, call stacks, and anything related to native machine code is handled transparently. On the other end, you have C: allocate and free memory for variables manually, no garbage collection, and doesn’t really handle vectorized operations. High-level languages provide safety but have a lot more runtime overhead, so can be slower.
Our codebase works the same way. We’ve optimized for speed, so some parts of our codebase used to look like C, because we used a lot of the patterns that C uses, like direct access to memory, to make it fast. We use a lot of static methods and fields as to minimize allocations whenever we have to. By minimizing allocations and making the memory footprint as slim as possible, we decrease the application stalls due to garbage collection. A good example of this is our open source StackExchange.Redis library.
To make sure regularly accessed data is faster, we use both memoization and caching. Memoization means we store the results of expensive operations; if we get the same inputs, we return the stored values instead of running the function again. We use a lot of caching (in different levels, both in-process and external, with Redis) as some of the SQL operations can be slow, while Redis is fast. Translating from relational data in SQL to object oriented data in any application can be a performance bottleneck, so we built Dapper, a high performance micro-ORM that suits our performance needs.
We use a lot of tricks and patterns—memoization, static methods, and other tricks to minimize allocations—to make our code run fast. As a trade-off, it often makes it harder to test and harder to maintain.
One of the most noncontroversial good practices in the industry is automated tests. We don’t write a lot of these because our code doesn’t follow standard decoupling practices; while those principles make for easy to maintain code for a team, they add extra steps during runtime, and allocate more memory. It’s not much on any given transaction, but over thousands per second, it adds up. Things like polymorphism and dependency injection have been replaced with static fields and service locators. Those are harder to replace for automated testing, but save us some precious allocations in our hot paths
Similarly, we don’t write unit tests for every new feature. The thing that hinders our ability to unit test is precisely the focus on static structures. Static methods and properties are global, harder to replace at runtime, and therefore, harder to "stub" or "mock." Those capabilities are very important for proper isolated unit testing. If we cannot mock a database connection, for instance, we cannot write tests that don't have access to the database. With our code base, you won't be able to easily do test driven development or similar practices that the industry seems to love.
That does not mean we believe a strong testing culture is a bad practice. Many of us have actually enjoyed working under test-first approaches before. But it's no silver bullet: your software is not going to crash and burn if you don't write your tests first, and the presence of tests alone does not mean you won't have maintainability issues.
Currently, we’re trying to change this. We're actively trying to write more tests and make our code more testable. It's an engineering goal we aim to achieve, but the changes needed are significant. It was not our priority early on. Now that we have had a product up and running successfully for many years, it's time to pay more attention to it.
Best practices, not required practices
So, what’s the takeaway from our experience building, scaling, and ensuring Stack Overflow is reliable for the tens of millions who visit every day?
The patterns and behaviors that have made it into best practices in the software engineering industry did so for a reason. They make building software easier, especially on larger teams. But they are best practices, not required practices.
There’s a school of thought that believes best practices only apply to obvious problems. Complex or chaotic problems require novel solutions. Sometimes you may need to intentionally break one of these rules to get the specific results that your software needs.
Special thanks to Ham Vocke and Jarrod Dixon for all their input on this post.