
[Ed. note: While we take some time to rest up over the holidays and prepare for next year, we are re-publishing our top ten posts for the year. Please enjoy our favorite work this year and we’ll see you in 2026.]
Last year we released Staging Ground to help new question-askers get feedback on their drafts from experienced users in a dedicated space before their question is posted publicly on Stack Overflow. We’ve since seen measurable improvements in the quality of questions posted; however, it still takes time for a question to get human feedback and make it through the full Staging Ground process.
Reviewers also noticed that they were repeating the same comments over and over: this post doesn’t belong here, there’s context missing, it’s a duplicate, etc. In classic Stack Overflow fashion, there are even comment templates they can apply for the right situations. This looked like an opportunity to use machine learning and AI to identify those common cases and speed up the process so human reviewers could spend their time tackling the more nuanced cases. Thanks to our partnership with Google, we had a solid AI tool (Gemini) to help us test, identify, and produce automated feedback.
In the end, we found that evaluating question quality and determining the appropriate feedback required some classic ML techniques in addition to our generative AI solution. This article will walk through how we considered, implemented, and measured the results of Question Assistant.
What is a good question?
LLMs can provide a lot of useful insights on text, so we were naturally curious if they could produce a quality rating for a question in a particular category. To start, we used three categories and defined them in prompts: context and background, expected outcome, and formatting and readability. These categories were chosen because they were the most common areas in which reviewers were writing the same comments repeatedly to help new askers improve their questions in Staging Ground.
Our tests with LLMs showed they could not reliably predict quality ratings and provide feedback that correlated with each other. The feedback itself was repetitive and did not correspond with the category—for example, all three categories would regularly include feedback about the version of the library or programming language, which was not exactly useful. Worse still, the quality rating and feedback wouldn’t change after the question draft was updated.
For an LLM to reliably rate the quality of a question when the concept itself is subjective in nature, we needed to define, through data, what a quality question is. While Stack Overflow has guidelines for how to ask a good question, quality is not something that can be easily translated into a numerical score. That meant we needed to create a labeled dataset that we could use to train and evaluate our ML models.
We started by trying to create a ground truth data set, one that contained data on how to rate questions. In a survey sent to 1,000 question-reviewers, we asked them to rate the quality of questions on a scale of 1 to 5 in the three categories. 152 participants fully completed the survey. After running the results through Krippendorff’s alpha, we got a pretty low score, which meant this labeled data wouldn’t make reliable training and evaluation data.
As we continued exploring the data, we came to the conclusion that a numerical rating doesn’t provide actionable feedback. If someone gets a 3 in a category, does that mean they need to improve it in order to post their question? The numerical rating doesn’t give context for what, how, or where the question needs to be improved.
While we wouldn’t be able to use an LLM to determine quality, our survey did affirm the importance of the feedback categories for that purpose. That led us to our alternative approach: building out feedback indicators for each of the previously mentioned categories. Rather than predicting the score directly, we built out individual models that would indicate whether a question should receive feedback for that specific indicator.
Building indicator models
Instead of using only an LLM with the possibility of a wide range of responses and generic outputs, we created individual logistic regression models. These produce a binary response based on the question title and body. Essentially: Does this question need a specific comment template applied to it or not?
For our first experiment, we chose a single category to build models for: context and background. We broke the category into four individual and actionable feedback indicators:
- Problem definition: The problem or goal is lacking information to understand what the user is trying to accomplish.
- Attempt details: The question needs additional information on what you have tried and the pertinent code (as relevant).
- Error details: The question needs additional information on error messages and debugging logs (as relevant).
- Missing MRE: Missing a minimal reproducible example using a portion of your code that reproduces the problem.
We derived these feedback indicators from clustering reviewer comments on Staging Ground posts to find the common themes between them. Conveniently, these themes also matched our existing comment templates and question close reasons, so we could use past data in training a model to detect them. Those reviewer comments and close comments were all vectorized using term frequency inverse document frequency (TF IDF) before passing in those features to logistic regression models.
Although we were building more traditional ML models to flag questions based on quality indicators, we still needed to pair it with an LLM in the workflow to provide actionable feedback. Once an indicator flags a question, it sends a preloaded response text with the question to Gemini, along with some system prompts. Gemini then synthesizes these to produce feedback that addresses the indicator, but is specific to the question.
This mermaid diagram shows the flow:
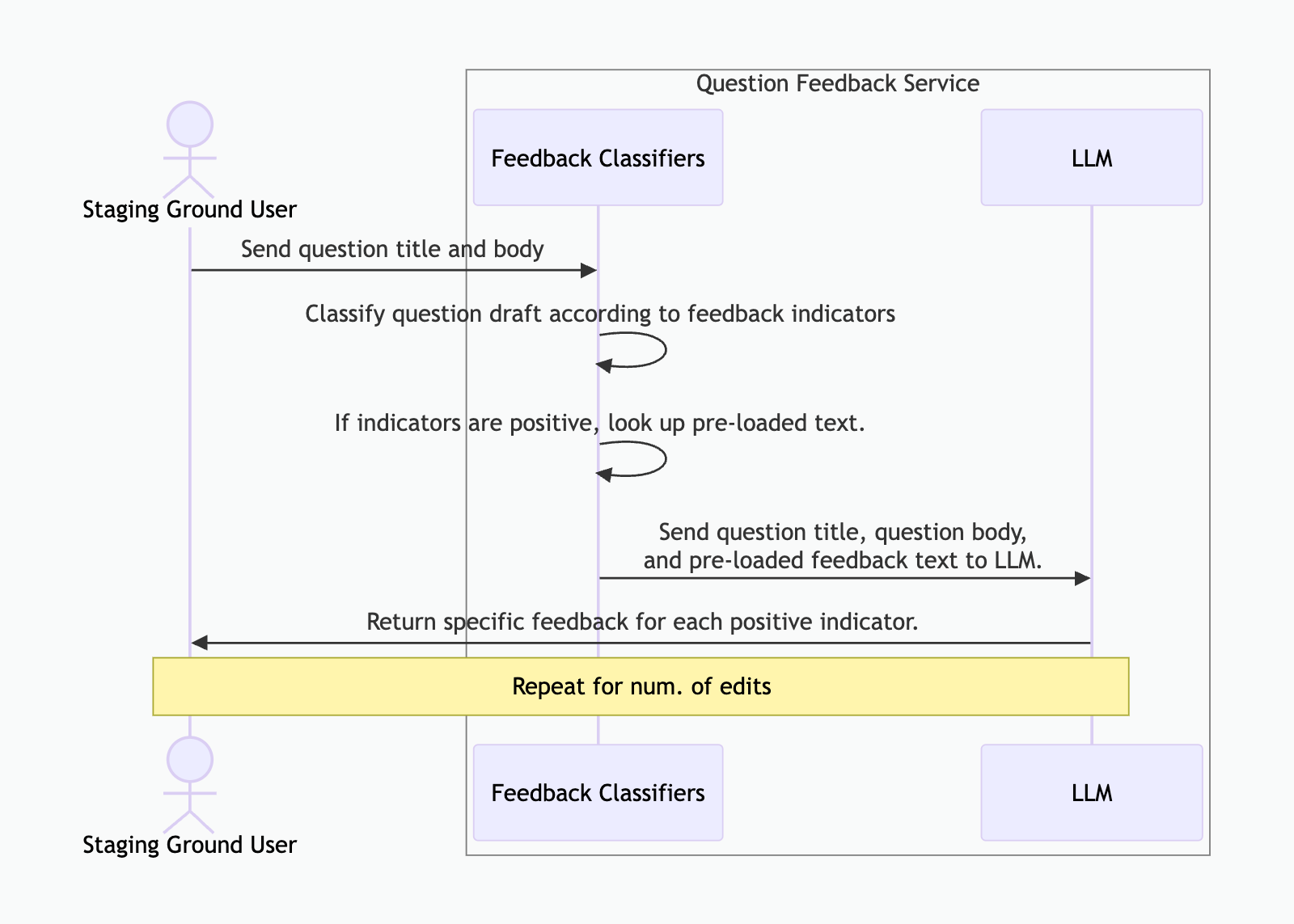
We trained and stored these models within our Azure Databricks ecosystem. In production, a dedicated service on Azure Kubernetes downloads from Databricks Unity Catalog and hosts the models to generate predictions upon feedback request.
Then our models were ready to start generating feedback.
Testing it on site
We ran this experiment in two stages: first on Staging Ground only, then on stackoverflow.com for all question askers with Ask Wizard. To measure success, we collected events through Azure Event Hub and logged predictions and results to Datadog to understand whether or not the generated feedback was helpful for the user, and to improve future iterations of the indicator models.
Our first experiment was in Staging Ground, where we could focus on new askers who likely needed the most help drafting their first question. We ran it as an A/B test, where all eligible Staging Ground askers were allocated for the experiment, split 50/50 between the control and variant groups. The control group did not receive assistance from Gemini, while the variant group did receive assistance from Gemini. Our goal was to see if the Question Assistant could increase the number of questions approved to the main site and reduce the time questions spent in review.
The results of the experiment were inconclusive based on our original goal metrics; neither approval rates nor average review times improved significantly for the variant group compared to the control. But it turns out that this solution actually solves a different problem. We saw a meaningful increase in success rates for questions; that is, questions that stay open on the site and receive an answer or a post score of at least plus two. So while we did not find what we were originally looking for, the experiment still validated that Question Assistant had value to askers and a positive impact on question quality.
For the second experiment, we ran the A/B test on all eligible askers on the Ask Question page with the Ask Wizard. This time, we wanted to confirm the results of the first experiment and see if Question Assistant could also help more experienced question-askers.
We saw a steady success rate of +12% across both experiments. With the meaningful success rates and consistency of our findings, we made Question Assistant available to all askers on Stack Overflow on March 6, 2025.
The next step forward
Changing course is not uncommon in research and early development. But realizing when you're on a path that won’t provide impact and pivoting to new logic is key to making sure all the puzzle pieces still fit together, just in a different way. With traditional ML and Gemini working together, we were able to fuse the suggested indicator feedback and the question text in order to provide more specific, contextual feedback that is actionable for the asker in improving their question, making it easier for users to find the knowledge they need. This is one step forward in our work to improve the core Q&A flows to make asking, answering, and contributing to knowledge easier for everyone. And we’re not done with Question Assistant just yet. Our Community Product teams are looking ahead to ways we can iterate on the indicator models and further optimize the question-asking experience with this feature.