
We know that Stack Overflow is a daily part of a lot of developers’ lives. I’ve heard from multiple people that they come here daily (if not more often) to get answers to their questions. Sometimes the answer to a question about code comes as a chunk of code. And sometimes that code makes it into production applications because it answered the question perfectly.
A group of researchers investigated these code snippets to see how secure they were, and if the security flaws that they introduced remained vulnerable in the project. Ashkan Sami, Associate Professor at Shiraz University, Foutse Khomh, Associate Professor at Polytechnique Montréal, and Gias Uddin, now Senior Data Scientist at the Bank of Canada, researched C++ code snippets on Stack Overflow to answer this exact question. (Ed note: We spoke to Khomh and Uddin previously about their work pulling opinions from Stack Overflow questions and comments.)
These researchers had been researching how developers use Stack Overflow in parallel when they met at a conference in Sweden in 2018. Khomh had been examining Stack Overflow code for licensing issues, which led the security expert Sami to wonder if the code had flaws that could expose copiers to more than just copyright violations.
Copying code itself isn’t always a bad thing. Code reuse can promote efficiency in software development; why solve a problem that has already been solved well? But when the developers use example code without trying to understand the implications of it, that’s when problems can arise. “Do they really care about scrutinizing it for vulnerabilities, or do they all just use the code off the shelf,” asked Khomh. “And if they do, does this issue spread around?”
Research process
Sami and company weren’t the first researchers to examine vulnerabilities in code posted to Stack Overflow. In reviewing the existing literature, they found that there were no papers addressing Stack Overflow code for the fourth most popular language, C++. “We wanted to focus on C++ to get better knowledge of how vulnerabilities evolve and if the vulnerability migration actually happened from Stack Overflow to GitHub.” said Sami.
They downloaded the SOTorrent data set, which contains ten years worth of Stack Overflow history. A first automated pass found 120,000 pieces of text tagged as code snippets. Through dedupe processes and manual examination, they boiled the set down to 2,560 unique snippets of code. Now the hard work began.
Three of the researchers reviewed every single of those snippets looking for vulnerabilities over multiple rounds of review. After each round, they had to defend why each vulnerable snippet was vulnerable with the entire research group. “It was exhaustive work,” said Sami. “But the vulnerabilities they found were actually vulnerabilities. After several rounds of review, they boiled down to 69 vulnerabilities that we could with some certainty state they are vulnerable.”
Those 69 vulnerable code snippets fell into one of 29 common weakness enumeration (CWE) categories. While 69 doesn’t seem like a lot, they found that those vulnerable snippets had migrated into over 2,800 projects. We’re not talking about school projects; these are actual live projects. Production code in publicly visible Github repos.
Before publishing their results, they made sure to contact all of the repo owners and let them know about the flaws in their code. A few responded and fixed the issues, but there were a lot of non-responses or quietly closed issues. And there could be more out there. “The vulnerabilities that we actually flag, I think it's a subset of what is actually being exchanged around,” said Khomh.
Copying without understanding
Many of the issues that the team found were basic security errors. But that doesn’t mean they weren’t prevalent. One of the more common flaws came from not checking return values. When you don’t check a return value in C++, you run the risk of the dreaded null pointer dereference. This error immediately causes a segmentation fault and crashes the process.
This error is pretty easy to guard against; verify that the return value is !NULL. But the fact that it was so common points out the larger problem. “If you borrow things and you don't understand the content of what you're borrowing,” said Khomh, “then you fall in this trap of reusing code that has potential vulnerabilities. Then you are just spreading those things around.” If you’re going to reuse code, you need to understand that code.
These vulnerabilities can leave software open to malicious actors. Another popular flaw was input validation. Like the return validation error, this flaw occurs when functions process input without making sure it’s something expected. In some cases, this can cause a stack overflow error--our namesake--and possibly cause a program to execute input as arbitrary code. “Even the last year,” said Uddin, “there were some hacking activities that specifically targeted the stack overflow vulnerability in code bases. And that got unauthorized access to millions of user information.”
Both Sami and Khomh are professors, so they run into student work that reuses code all the time. With proper attribution and an understanding of what the code actually does, the copied code can actually help the student learn. More often than not, though, code is copied without any understanding of how it works. The best method is still doing it yourself. “Ideally they should create the solution and get the full mark,” said Khomh. “Then they learn the concept, and they could actually build something out of it.”
But if copied code must be used, attribution and due diligence are a must. “They should credit where they got it,” said Sami. “Again they should check if this component is properly okay to integrate with another component. Just an example, but the problem that happened in Ariane five and blew up the whole spacecraft was because they had an integer problem. The 64 bit number was written into a 16 bit place.” They reused code from the previous mission without checking that it still worked on the new systems.
What Stack can do about it
The researchers made it clear that this isn’t a problem unique to Stack Overflow; any site sharing code snippets as examples would face this. As part of their research, they created a browser extension that will identify the vulnerable code.
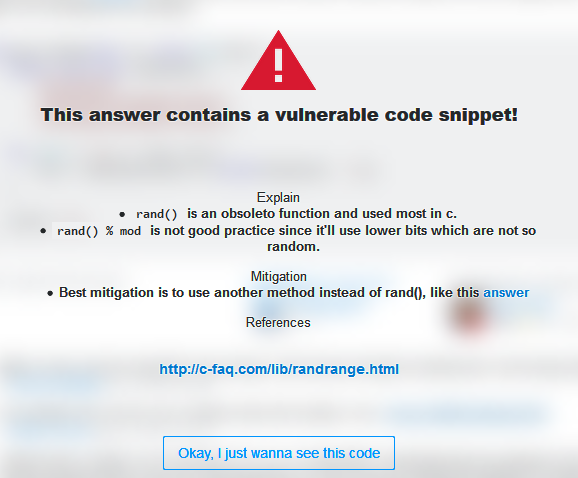
But there are other things that the community can do to help out. First and foremost is to understand that the code snippets posted as examples are not production-ready code. Don’t copy this into a project without understanding the code and testing it. With the extension, you have an awareness of the snippets that the researchers have flagged as risky, but new answers are being added all the time.
They also suggest leveraging the security experts among the community. “Now the Stack Overflow community as a whole, the developers, they're pretty impressive,” said Uddin. “They're very interactive with each other. If we can try to motivate the security experts to both raise awareness and educate the user community, we will not only serve to make the code more secure, but also provide more information to the users who will be using the code.”
Because, in the end, these researchers are also educators. They think that Stack Overflow can help educate curious questioners on security as well as programming technique. As Professor Sami said: “Not just providing answers, but providing insights whether the code is secure or is not secured.”