
Stack Overflow and the Stack Exchange network of sites have famously run on a series of physical servers lodged in data centers in the US, mostly near New York City. In our scrappy days, we ran everything on a single machine and crowed about it when we got a second server to handle our SQL server. We moved from individual machines to a data center, then another data center, and added CDN replication. We grew over the years to handle our success, but we were still fundamentally based around individual servers housed in a data center that we maintained.
While we had squeezed every bit of performance out of what we had, we knew it couldn’t last forever. Plus those optimizations got in the way of some of the more modern software engineering practices we were trying to adopt, like standalone service and team autonomy. Inevitably, we were going to move the Stack Overflow public site and the rest of the network to a cloud service.
We moved our Stack Overflow for Teams instances to Azure between 2021 and 2023. It was a significant effort that had some false starts and required us to disentangle Teams from the rest of the code. We managed to pull it off successfully; as a bonus, we had many of our core components containerized and in a deployable state. That was the good news.
The bad news was that much of our public site was still architected around the existence of a data center. There were a lot of assumptions around latency, around performance, around everything. The biggest concern everyone—me included—had was, will it even work? Will Stack Overflow, born on the bare metal racks of a data center, manage to ascend to cloud or would we always have poor Josh Zhang on call to drive over to the data center to reboot a machine?
This is the first in a series of blog posts that will discuss how we did, in fact, make it work.
What we learned from the last cloud migration
As I mentioned, we’d already done one project that involved moving servers to the cloud. Since that effort took three tries over three years, we figured we’d take a moment to learn from that process in an attempt to make this one smoother. While the platform would be different this time, many of the issues we had were process-related, as is often the case with large projects.
For this project, we had one deadline that matters: July 31, 2025, when our contract with the data center ended—with no option to renew since the parent datacenter was shutting down. Engineering teams were strongly encouraged to create milestones for the project and set their own deadlines significantly earlier than this hard stop, as we all know that engineering efforts often take longer than planned. We decided not to make public any deadlines that were immaterial to our external users/community. That gave us flexibility when things needed to change and reduced the risk of adding stress to our community and external customers. In past projects we hadn’t done this, and any minor change or acceptable project slippage was magnified needlessly into a PR problem that added stress to all involved. Swapping the infrastructure of a platform relied on by millions of opinionated developers was stressful enough.
The migration of Stack Overflow for Teams was initially done to VMs running Windows. We knew this was suboptimal, but we didn’t want to change the app, the infrastructure, and the way we ran all our applications. We did run into issues where our VMs were not fully immutable and we had to build workarounds to do rolling deployments. So the first thing we did after getting Teams fully migrated to the cloud was move everything to Kubernetes. This meant moving from deployment on Windows VMs running IIS to containerizing our apps and running them on Kubernetes. The migration of the public platform could benefit from this experience, since a lot of the apps we would use were already containerized and we could build on top of that foundation. We absolutely wanted to avoid using virtual machines this time except for SQL Server, which needed dedicated hardware for performance reasons.
Another thing we saw during the Teams migration was that projects like this need are huge projects that need dedicated staff. The Teams migration was initially not treated as a project, and a couple of people were trying to work on it in addition to all their other responsibilities. Only when people could dedicate all their time to moving Teams was when the project advanced. This time, we’d have a dedicated team from the beginning. No half-time work here—engineers would have this as their only focus.
One reason the Teams migration initially was so hard was that it was a big bang. We would split the app from stackoverflow.com and switch all infrastructure. I spent a lot of time thinking about how we could split this and when we came up with a plan that would allow us to take much smaller steps we finally got things moving and finished the migration successfully.
With these learnings, we now started an even bigger project: moving all of the public platform with its millions of users to the cloud.
The architect’s dilemma
People often think that writing code is 80% of the project and launch is 20%. Due to the complexity of our infrastructure, PII/GDPR, and other things, launch is the 80%. This was mainly because our application was architected around our infrastructure. The app was complex, deeply coupled with the datacenter, and mostly undocumented. We had a lot of unknowns to account for in our explorations. When you're draining the swamp, watch out for alligators.
One of the biggest alligators in this swamp would be the tight coupling of application response and timings. Early in Stack Overflow’s design, we optimized pretty heavily for speed and performance, and part of that optimization included expectations about server response times—anything over 30ms could cause serious issues for the site as a whole. Our app knew the infrastructure it was running on. From server names to latency, there were a lot of assumptions in the millions of lines of code we had to migrate.
Because of this, our first focus was running load tests against our application running in the cloud. Load testing would be challenging since we didn’t have an existing rubric for this on our public sites. A noted SRE once observed, “Load testing is like flossing teeth. Everyone knows they should do it, everyone claims they do it, but most people don't actually do it." It was time for us to finally implement this.
We wanted to run our tests on environments that were identical to production, barring scale and access levels, which were more permissive in the test environments. No dependencies would be shared between test and production environments. Application configurations and network routing should be as similar as possible. We are using Terraform to build all our cloud resources so it was relatively easy to spin up additional environments that matched production.
When we started this, our GCP infrastructure was still being built out so we initially deployed the main Q&A application to Azure on Kubernetes temporarily. This allowed us to start building our load test scripts. I’ll discuss the details of how we built our load test setup in another blog post, but for now it’s good to know that we were successful! We figured out how to scale our new stack with Cloudflare, nginx, and Kubernetes, and we fixed issues in the app that caused slow performance but were not directly visible in the on-premises datacenter. With each iteration, we saw the requests per second that we could handle increase until we were well above the number of requests we had to handle in the data center. This mitigated one of the biggest fears of moving to the cloud!
It also proved out one of the advantages we hoped to gain by running in the cloud. The physical hardware in the datacenter meant we were pretty limited in how we could deploy test environments. We ended up having very different configurations between test and prod, which led to inconsistent test results, testing in production, and production outages. GCP APIs and IaC make it possible to deploy identical environments, so we could be sure any test results would be applicable to a prod deployment.
Now that we knew that we could at least run the public platform in GCP, we could start building out all the bits and pieces.
Building a cloud city
Moving from a set of servers to a cloud provider isn’t as simple as just moving our existing applications to a new location (as we found out previously). Resources scale to meet demand, latency and performance are different, services and dependencies can be colocated for resilience, and self-run dependencies might be better as hosted services.
I already mentioned that we moved to GCP a couple of times, but this wasn’t clear at the beginning of the project. Our Stack Overflow for Teams and Enterprise instances are hosted on Azure, and early designs and discussions assumed that would be the host for the public sites. But we ended up forming a strong partnership with Google Cloud, and decided to host our public sites with them as part of that partnership.
Once we knew GCP was our target, we first had to pick a datacenter location. We needed one that supported the following:
- The VM classes (`M3-ultramem-32`) that our DBRE team requested in two zones.
- Physical separation from the regions of our Azure datacenters in the event of a regional catastrophe.
- Based in the US.
That left us with one choice, us-central1 (Iowa). We’ll use multi-zone services and deployments for reliability for this one region.
We had already made the decision to use Kubernetes as the core application hosting platform for all services, which aligns with our overall broader adoption of Kubernetes since moving Stack Overflow for Teams to Azure. For Teams, all apps are on a modern version of .NET but for the public platform we have some older applications on the full .NET framework and we didn’t have the time to upgrade those to a modern version of .NET before the deadline. We made the decision to run those on a Windows Kubernetes cluster. This was not ideal but at least it allowed us to avoid running VMs for applications and keep our infrastructure fully on Kubernetes.
Once we figured out where our code would run, we needed to decide how it would get there. This was an opportunity to evaluate our existing processes and replace them if they didn’t work for us, as it’s a clean break from the processes of the past. For Teams, we chose GitHub Actions over TeamCity, and we wanted to do the same for the public platform. Artifacts for deployments are stored in CloudSmith and then deployed to Azure and GCP.
For deployment, we’re doubling down on Octopus Deploy. Our other products use Octopus, so this lets us standardize our processes. One unique problem we have is that some of our microservices and legacy apps need to be deployed (with configuration differences) for each product we run: the public platform, a multi-tenant Teams product, and many single tenant Enterprise instances with Teams and Enterprise running in Azure and the public platform in GCP. We didn’t want all engineering teams to have to worry about this so we adopted Cloud Native Application Bundle (CNAB) to package all deployment scripts and artifacts into a container that fully abstracts where and how you are deploying. This makes our pipelines much easier to test and maintain without everyone having to understand all the details.
Our public sites have always used SQL Server, which we’ve optimized to have very high throughput. Many cloud platforms offer their own managed SQL offerings, which sounded nice but did not deliver the performance we needed. This is why we are running SQL Server on dedicated VMs.
For these VMs, we had to consider some of the resource limitations: we needed about 1.5TB of memory to hold the database in memory. This gave us a VM (`m3-ultramem-128`: 128 vCPUs, 3.9 TB memory) with a lot of memory but also a lot of CPUs. Since we only needed the memory and not all the CPU cores, we disabled half of the cores to save on licensing costs. It would have been prohibitively expensive otherwise. Many of the smaller sites could probably survive just fine on more modest specs via managed SQL, but that would require drastic shifts in how we manage them.
As part of our focus on speed, we have a detailed caching strategy that uses Redis. We looked at running GCP’s MemoryStore for the Redis platform-as-a-service offering and running Redis ourselves on Kubernetes. Since we had a tight deadline and didn’t want to worry about running Redis, we went with MemoryStore. Redis instances would be region-specific without replication across regions. The managed offering had a limit on the number of databases, so we updated the application to use a key prefix model instead of per-site Redis databases, which is how our Teams products already work. The last technology in our stack we’d need to consider is Elasticsearch. We considered following Teams, which had moved to Elastic's hosted service (called Elastic Cloud), which they procured through the Azure Marketplace. Sadly, we could not piggyback on their procurement since it would not be running in Azure. We also learned that Teams ran into some problems which would be magnified by our public platform's requirements. We decided to self-host Elasticsearch. The Elastic Cloud on Kubernetes operator made this easy.
In moving our application to the cloud, we’d need to take a hard look at our security measures. Our previous solutions, HAProxy logs and a homemade system called Traffic Processing Service (TPS), were slated for retirement with the datacenter shutdown. Instead, we planned to move all public assets behind the Cloudflare CDN and process the logs with Snowflake. The idea was that if everything was behind CDN and those logs were already going into Snowflake, it would be easier to train people to get what they need from Snowflake than to implement another solution. Plus, we’d have a unified solution for security, edge caching, and failover.
And with this we have the foundational architecture of our cloud environment spanning Cloudflare, nginx, Kubernetes, SQL Server, Redis and Elastic. The following image shows what our architecture looks like.
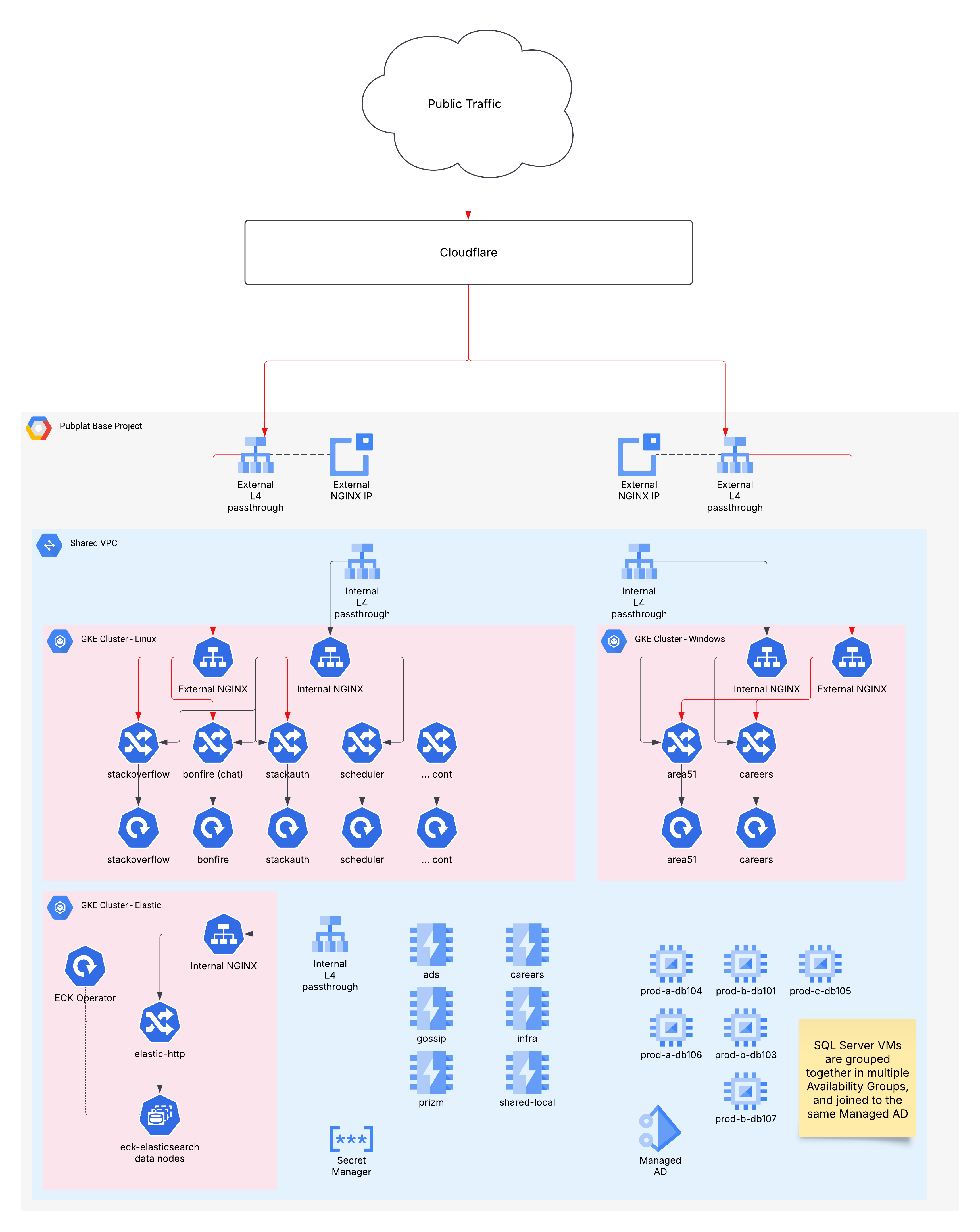
Piece by piece
Load testing and building out the infrastructure were things we could do in parallel. Once the load testing was successful, we started migrating all our applications and data to GCP. For this, we adopted an iterative strategy. We would move the smallest possible service over and learn from it. This would then influence our next step.
In the next article in this series, we’ll dig into the details of our load testing experience. In the third part, we will discuss how we migrated our apps.