In the age of AI, being able to make applications and create code has never been easier. But is it any good? Here's what vibe coding is like for someone without technical skills.
For promising Gen Z students, a career as a software developer seemed like the golden ticket to career stability and success. But in the age of AI, the career promise for Gen Z software developers is gone.
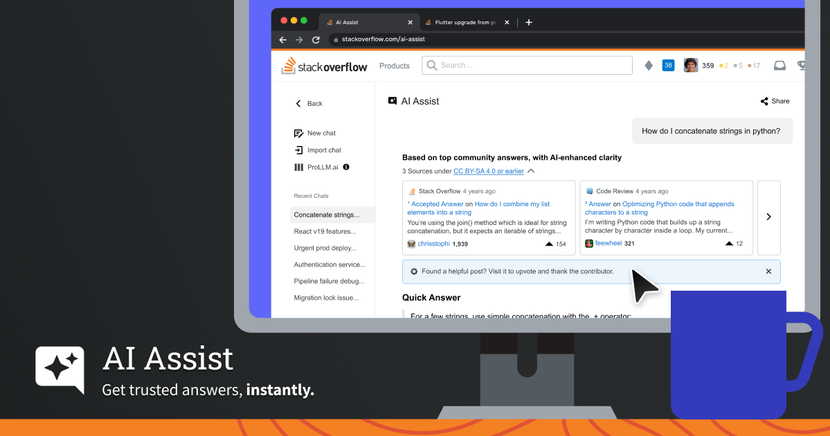
The way that developers interact with knowledge has changed in the age of AI. That's why we created AI Assist—a new way for users to access our 17 years of expert knowledge, and how Stack Overflow is remaining the always-open-tab of programmers around the world.
The internet is facing a fundamental shift—and the way we measure success online is shifting too. Reach, trust, attribution, and influence are the new metrics to measure against in the post GenAI era.
Ryan sits down with Dimitri Stiliadis, CTO and co-founder of Endor Labs, to talk about how AppSec is evolving to address AI’s use cases. They discuss the implications of AI-generated code on security practices, the importance of human oversight in managing vulnerabilities, and how organizations should be balancing security and efficiency with AI.
While AI coding assistants are helping developers become more productive, the true value of AI lies in its ability to automate the non-coding tasks that have historically been bottlenecks, allowing leaders to create more agile teams and focus on higher-level strategic problems.
Kylan Gibbs, CEO of Inworld, joins the show to discuss the technical challenges of creating interactive AI for virtual worlds and games, the significance of user experience, and the importance of accessibility and cost-efficiency in deploying AI models.
In this episode of Leaders of Code, Jody Bailey, Stack Overflow’s CTPO, Anirudh Kaul, Senior Director of Software Engineering, and Paul Petersen, Cloud Platform Engineering Manager, discuss the U.S. Bank’s journey from traditional banking practices to embracing new technologies.
Ryan welcomes Mahir Yavuz, Senior Director of Engineering at Etsy, to the show to explore the unique challenges that Etsy’s marketplace faces and how Etsy’s teams leverage machine learning and AI to manage product SKUs, enrich inventory metadata, and improve both buyer and seller experiences.
Ryan is joined by Kieran Furlong, CEO of Realta Fusion, to talk about the future of fusion as a safe and sustainable energy source, the computation and scientific advancements that have made fusion possible, and how fusion technology innovations will address data and AI’s rising energy demands.
In this episode of Leaders of Code, Jody Bailey, Chief Product and Technology Officer at Stack Overflow, sits down with Dane Knecht, the newly appointed Chief Technology Officer at Cloudflare.
As a generation characterized as "digital natives," the way Gen Z interacts with and consumes knowledge is rooted in their desire for instant gratification and personalization. How will this affect the future of knowledge management and the technologies of tomorrow?
Kathleen Vignos, VP of Software Engineering at Capital One, sits down with Ryan to explore shifting to 100% serverless architecture in enterprise, deploying talent for better customer experience, and fostering AI innovation and tech advancements in a regulated banking environment.
Ryan talks with Greg Fallon, CEO of Geminus, about the intersection of AI and physical infrastructure, the evolution of simulation technology, the role of synthetic data in machine learning, and the importance of building trust in AI systems. Their conversation also touches on automation, security concerns inherent in AI-driven infrastructure, and AI’s potential to revolutionize how complex infrastructure systems are managed.
Today’s episode is a roundup of spontaneous, on-the-ground conversations from HumanX 2025, featuring guests from CodeConductor, DDN, Cloudflare, and Galileo.
In this episode of Leaders of Code, we chat with guests from Lloyds Banking Group about their focus on engineering excellence and the need for organizations to adapt to new technologies while ensuring customer safety and meeting their expectations.
In today’s episode, Ryan sits down with Richard “Spencer” Schaefer, cofounder and CTO of Lunar Analytics and a federal AI officer, and Caroline Zhang, cofounder and CTO of Knowtex, which provides AI-powered voice technology to automate workflows. They talk about safeguarding patient privacy, how AI changes doctor-patient interactions and healthcare delivery, the challenges inherent in rolling out AI technology, and the importance of quality data to fuel AI initiatives. Also included: a chat with Jeff Berkowitz, cofounder and CEO of Delve Deep Learning.
Ryan chats with Amr Awadallah, founder and CEO of GenAI platform Vectara about how retrieval-augmented generation (RAG) has advanced, why fact-checking and accurate data are essential in building AI applications, and how Vectara’s Mockingbird model seeks to minimize hallucinations.
On this episode of Leaders of Code, Maureen Makes, VP of Engineering at Recursion, discusses AI's role in drug discovery, scaling and integration challenges, and the importance of innovation in achieving the high standards desired.